# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT


(一)广域网,横跨海陆
为了AI还真是,
搞网络的钱不少花,
大动作,大投入,
数据中心内部网络,重做;
数据中心外部网络,也重做;
确切表达,不是完全推翻,但也是大变革。
数据中心里的网络,
谭老师我写了好几篇了,
高低得看看,跨数据中心的网络,也就是广域网,
这网规模大,非常大,巨大,
这么大,还想做好,岂不很难?
重做,要有很大决心,挑战一堆。
但有AI在,谁也阻挡不了头部大厂的决心。
有网络技术大佬曾和我说,
大网的难度比起小网,至少高两个数量级。
这种大网,动不动就跨海;
Meta的广域网海底电缆怎么搞的呢?
2025年11月,
《解锁AI潜力,跨越5万公里全球》;
5万公里,比地球周长还长。
每根光缆里塞16对光纤;
这是老系统的两倍容量;
还要“疏通高层关系”,
跨越50个司法管辖区,
花近6年时间,动用35艘海上船只,
累计运营时长相当于32年。

以前的海底光缆,大多是运营商专属,
要么一家独揽,要么几家瓜分,
小服务商想拿到带宽,不仅贵,还得看人脸色。
这么大的工程,为啥是美国Meta公司出头?
这背后,是科技巨头对全球广域网话语权的争夺;
就不展开了,C位是广域网,
科技巨头的投入和野心,都浓缩在漫画里了。
跨海之后就上岸,城市之间建广域网,
那该怎么干呢?
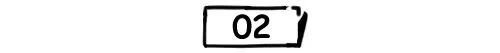
(二)先问客户,需要一张什么样的广域网?
面对尊敬的金主(网络用户),
稳定性要高、性能要好、成本要低,
请努力保持微笑。
(此处有3000字的怨气没发出来)
稳定性,
首屈一指重要,
或者说,稳定性是n个零前面的一,
历史中绝不缺少稳定性的教训,
不过,人类从历史中学到的唯一的教训,
就是没有从历史中吸取任何教训;
而且,广域网的故障,
从来没有“小教训”;
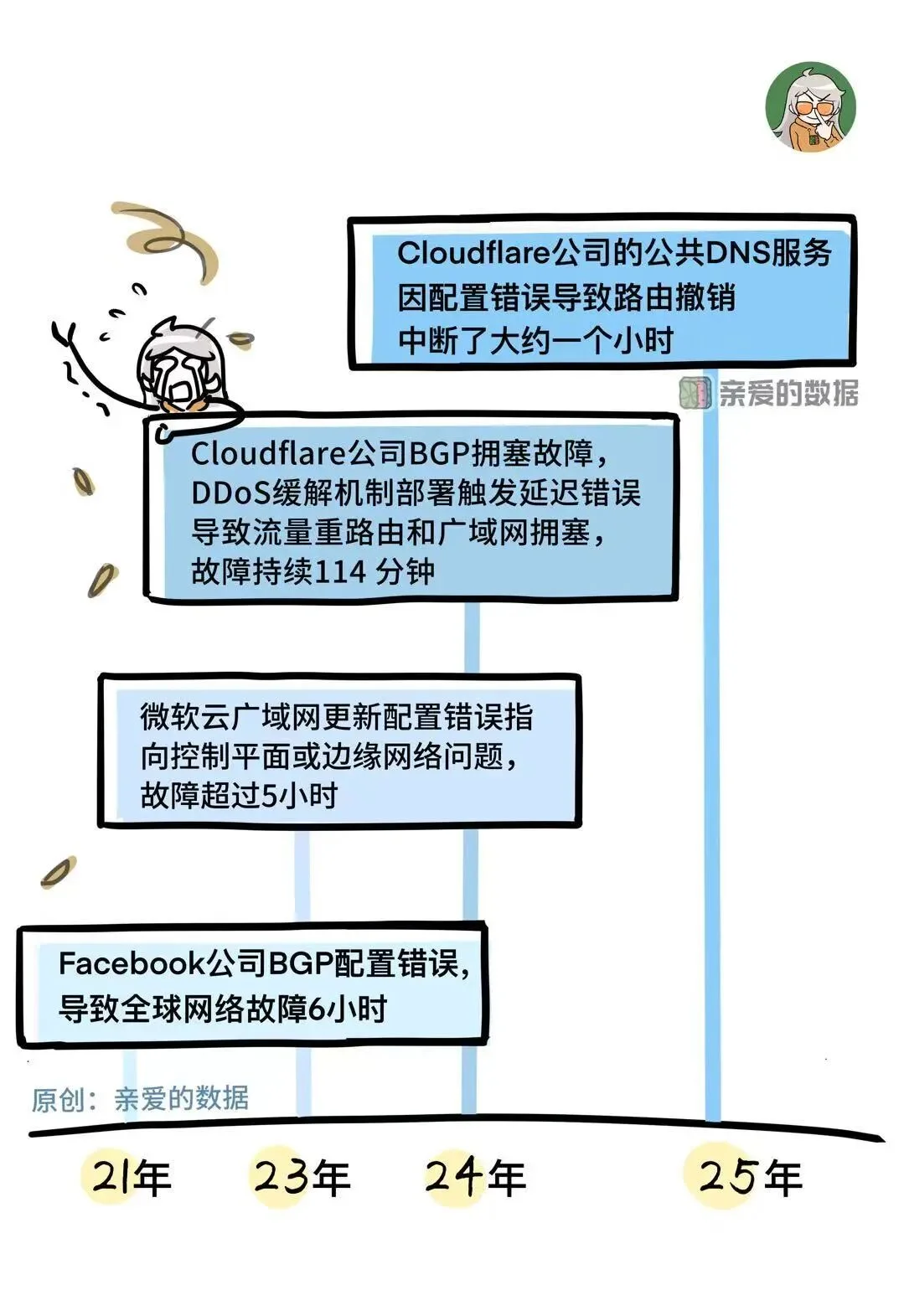
风波历尽,在保障稳定的前提下,
就要比拼性能了。
性能有几个最重要的核心指标:
带宽、网络延时、丢包率;
而今,需求五花八门,
“高性能”早已不再是单一维度的指标。
有些要低延迟,像视频会议;
有些追求极致低延迟,
如,股票高频交易;
有些更看重带宽稳定与零丢包,
如,AI训练的数据同步;
正因如此,好网络不在于一味给带宽给资源,
而在于“对症下药”,
根据每类(应用)需求,
恰如其分地提供服务质量,精细控制。
这种理念背后还有一个现实考量:
高性能,有成本,
如果为所有流量都配超低延迟,
零丢包和超高带宽,
不仅资源浪费严重,
整体系统成本也将难以承受。
事实上,许多应用对网络瑕疵很有容忍度。
例如,普通网页浏览,
过程中偶尔丢失几个数据包,
浏览器会自动重传,用户几乎毫无感知;
而同样的丢包,
若发生在AI模型训练的数据同步阶段,
则可能导致训练速度骤降,甚至任务失败。
于是,“差异化服务”这一能力走上舞台中央,
因此,理想的网络架构应当——
能识别不同业务类型,
并为其分配匹配的服务等级(SLA)。
啥业务配啥待遇,
不搞一刀切;
这种“因地制宜”的策略,
既保障了核心业务的性能需求,
又避免了不必要的开销。
归根结底,最好的性能并非“绝对最强”,
而是“刚刚好”。
这正是,网络的核心价值所在。
成本是商业逻辑的基础,无须多言;
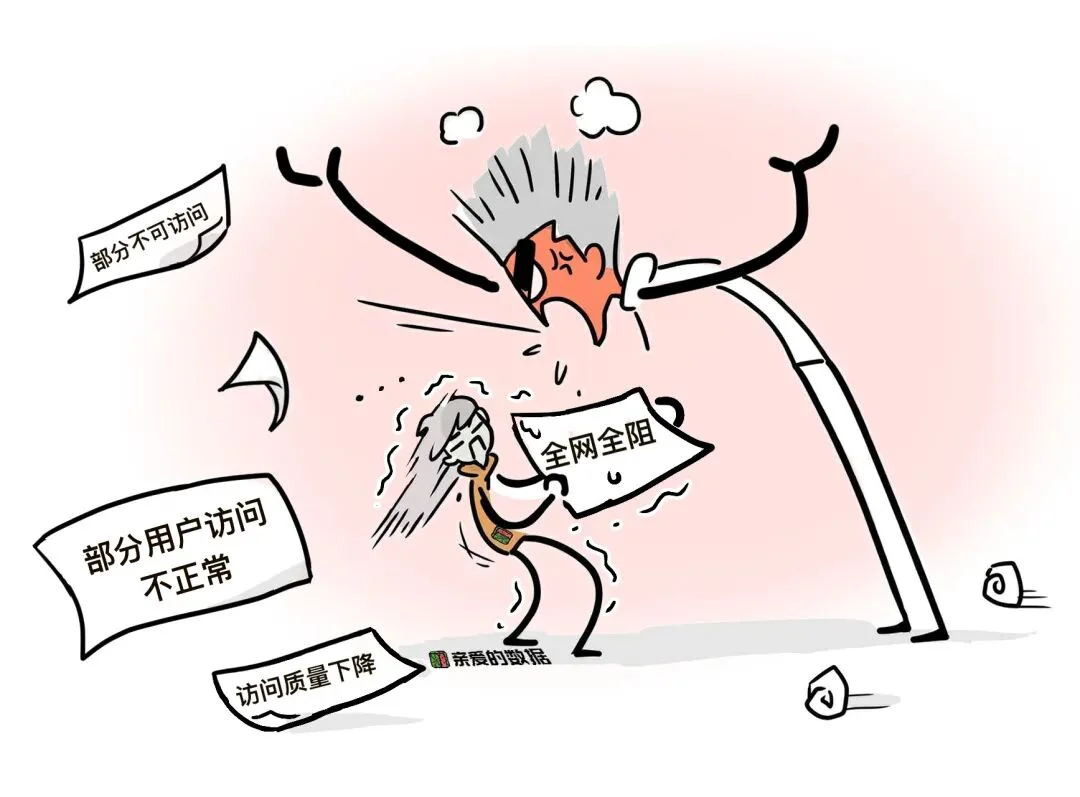
再加一点,
离开规模谈稳定,性能和成本,
是耍流氓。
什么意思呢?一个AI实验室里,
5台服务器40张GPU卡,
稳定和性能都可以十分卓越,
但,这种卓越无法复制于,
4000张GPU卡的大规模集群。
站在头部大云厂商角度,
要以低成本提供高稳定,
高性价比的网络服务,
成本包括Capx(资本性支出),
和Opex(运营性支出),
其中Opex是大头,
也就是说,大规模网络的运维效率是重中之重,
怎么样提升?又做到何种程度?
我只能说,这种“理想”,
AWS做到了,谷歌,Meta也做到了,
阿里云做到了,
这类代表性网络架构,也已成熟,
比如,阿里云HPN。
这些是数据中心网络的情况,
而对于广域网而言,
则是另一番天地。
广域网历史包袱很重,
以前的广域网(技术架构),
过于复杂,已然事实,
想翻转此局面,
中小厂商肯定没有实力,
大厂商谁会出手?
在何时出手,而又如何出手?
复杂加复杂,直接遭遇不可能三角,走不通了。
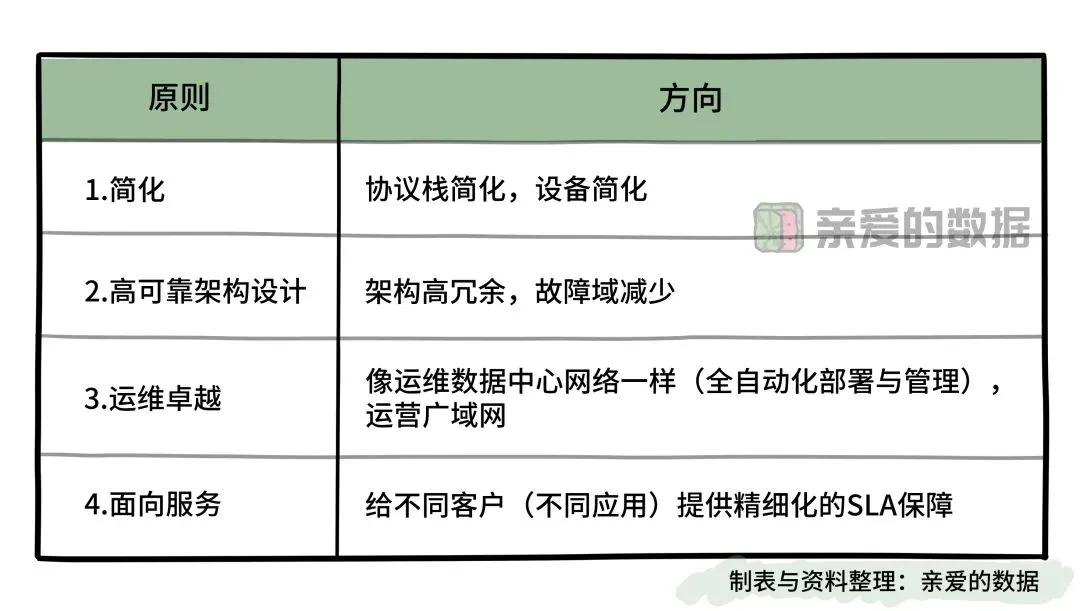
(三)聊下广域网设计原则
如何达成“梦中情网”?
简化的确是一条思路,
关键在于,怎么简化?
得找个真正的专家聊聊;
好在,有机会和,
阿里云广域网架构与研发总监苏远超聊了,
他是这么说的:
“多年以前,当我还在思科做架构的时候,
我们就开始思考,
传统网络架构需要增加新功能,
恐怕勉为其难,力不从心;
比如,控制面特别繁重、扩展困难、
运维繁琐、容易出错……
但是重构这事,在思科公司落不了地,
它不只是网络本身的变革。
有很多依赖项,
需要网络和运营支撑系统一体化才能做成。”
这可能是阿里广域网(eCore)曾经的“野望”,
而今,eCore正在运行,用“现实”代替“想法”。
几个小时,我们讨论得很充分,
还是那句老话,技术的突破,常在工程前沿阵地。
我顺手总结了超哥的核心观点:
一举解决从前传统广域网三十年的难题,
第一,最根本的一点就是“简化”。
过去,网络协议繁杂,功能堆叠,
导致路由器设备十分庞大,
从上到下简化,将原有的N个协议,
精简至两个(ISIS和BGP),
大大缩小了难题的空间,
难度指数级地下降。
第二是高可靠架构设计,
架构高冗余,故障域减少;
AI对网络稳定性的要求苛刻,
“故障爆炸半径最小化”。
第三是运维卓越,
第四是面向服务,此篇按下不表。
这些原则需要在具体设计中平衡。
不难观察:顶级厂商创新方向,
他们力图简化,
且追求获得更好的服务。
我总结一下:简化的工作很多,
不仅简化控制平面,
还重构网络分层、协议运行域划分等,
把全网的大域分解成,
小的平面和更紧凑的运行区域;
这样一来,协议状态无需全域同步,
从根本上缩小故障域,
从而提升稳定性。
“稳定性”一词,总是频繁提到,
甚至有时候把一些表面上的改进,
也归为“为了稳定性”。对稳定性的考验,
一天24小时,要真实数据加以说明。
苏远超告诉我:
“今年城域网故障就减少了80%以上。”

(四)“为何你们能做单栈单片”?
单栈的“栈”是协议栈,
单片的“片”是芯片;
很明晰哪,单栈是软件,单片是硬件,
挑战性问题抛给阿里:
为何你们能做,而不是别人?
这就得从历史的相似性中找一些启发:
以前思科公司,
为了让一个路由器达到很大的带宽,
把一个路由器拓展到,
多框连在一起(Multi-Chassis Router),
可惜,这个做法很有局限性,
虽然解决了一个问题,
但是引入了更棘手的问题。
也就是:解决了规模和性能,
但是引入了,
高运维成本和难运维的问题;
这熟悉的配方,熟悉的套路,
这套“枷锁”和当下热门的AI超节点,
是不是十分类似?
我不下结论,交给读者自己判断。
打开这个“枷锁”的钥匙,
我认为是“单栈单片”,
这是一种设计理念。
先把协议简化,简化软件,
再简化硬件,双管齐下。
为什么以前不这么干?
因为以前软件和硬件,都没准备好。
比如,路由器承载很多功能,
且要求大带宽。
芯片很难同时做到,
因为功能丰富和带宽是相互妥协的关系。
要么放弃丰富功能,要么放弃大带宽,
纠结很多年,总需要一个新出路。
这时候就不得不提,
源于思科公司的Segment Routing技术。
或者说,思科团队也追求简化思想,
需要和一个持有相同技术理念的软件团队,
双向奔赴。
于是,思科和阿里的合作,水到渠成。
协议简化之后,
路由器设备也可以采用大带宽芯片来实现功能。
然而,对于路由器设备来说,
仅仅依靠大带宽是不够的,
它还需要大缓存来支持长距离传输。
针对这一需求,
思科的Silicon One
P200 芯片应运而生。
单栈单片架构,
既具备大带宽,又具备大缓存,
是经过特定优化的芯片。
于是,一通操作猛如虎,
带宽直达51.2T。
架构和协议简化了,
高效且专门优化的,
大带宽芯片(51.2T)也有了,
此时,控制面和数据面的条件都已具备,
单芯片的路由器已然成为可能。
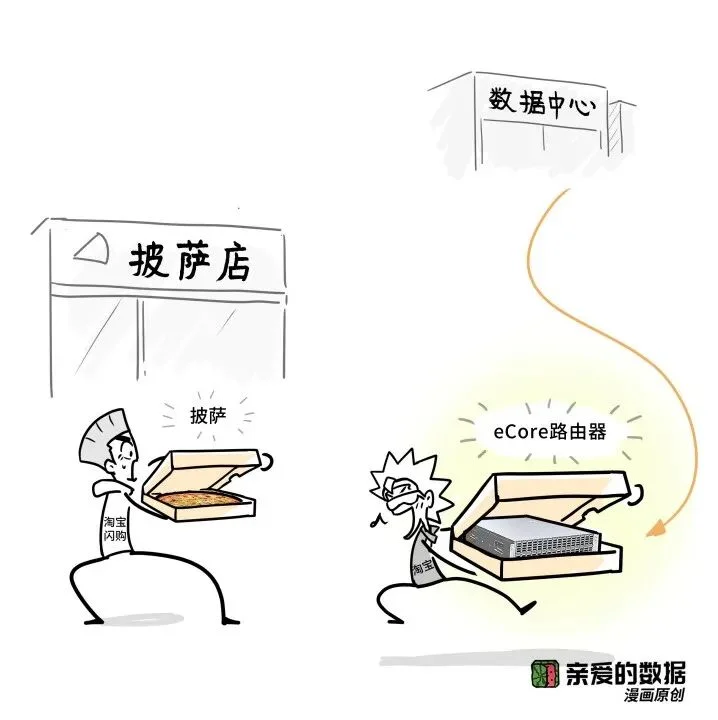
设备简化到什么程度呢?
披萨盒式(Pizza-box)白盒路由器,
最终,做到了:
原本,
需要多个芯片拼接在一起;
现在每台设备只配备一个芯片,
避免了多芯片协作的复杂性。
结果,虽然设备数量增多,
但每台设备变得简单,
整体架构高效和灵活。
简单来说,
这是协议栈的简化和大带宽芯片,
相辅相成的结果,
也就是“单栈单片”。

(五)架构设计图长啥样?
简化,听上去真不错,
但要落地,并非易事,
如何简化呢?最好先来看全局图;
苏远超给我看了一张《高层次设计图》,
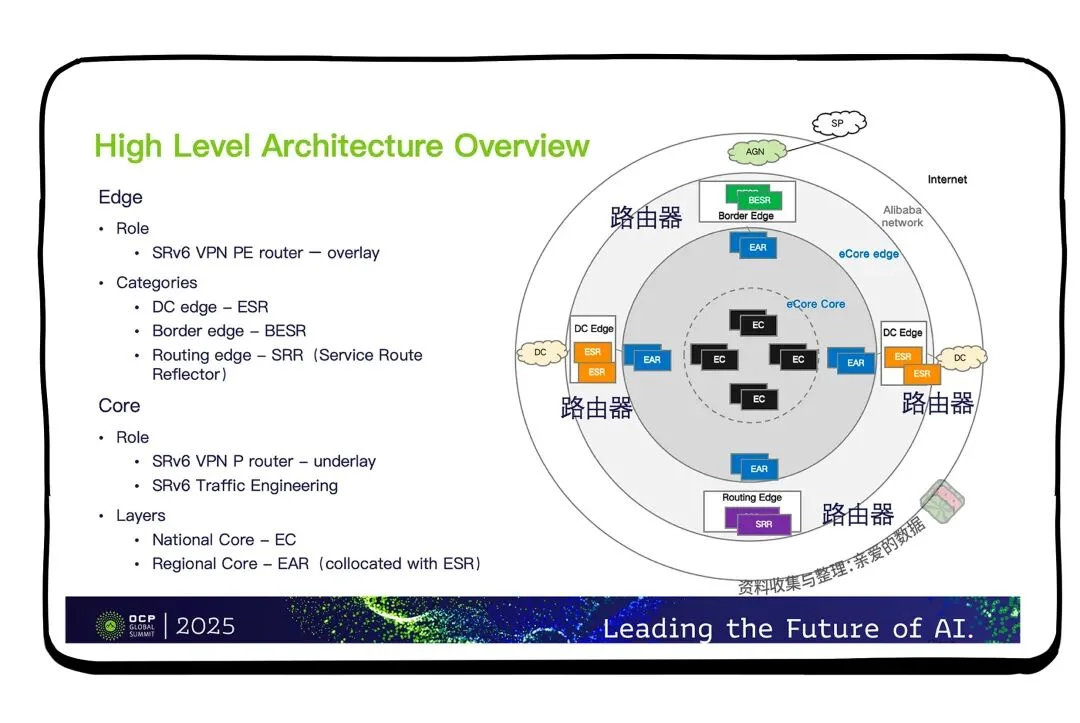
将广域网分解成多个层次,
每个层次负责处理特定的功能或问题,
从而简化了整个网络的管理和操作,
层次化设计确实可以看作,
是一种“分而治之”的策略。
图上阿里云广域网络(名叫eCore),
分为边缘(Edge)和核心(Core)两部分。
核心层里有EC(核心路由器),
就像城市间的飞机,
数据经过EC,好比坐上了飞机;
有飞机自动导航系统,
路由器之间使用ISIS协议,
在不同的城市之间,
比如,京沪牛马专线,传输数据;
而在边缘层是(也就是EAR和ESR),
分别好比汽车和电瓶车,
负责处理从overlay网络(虚拟网络),
到underlay网络(底层网络)的转发。核心层里,
核心路由器主要任务是路由计算,
比如,最短路径选择,
让流量按最优路径传输。
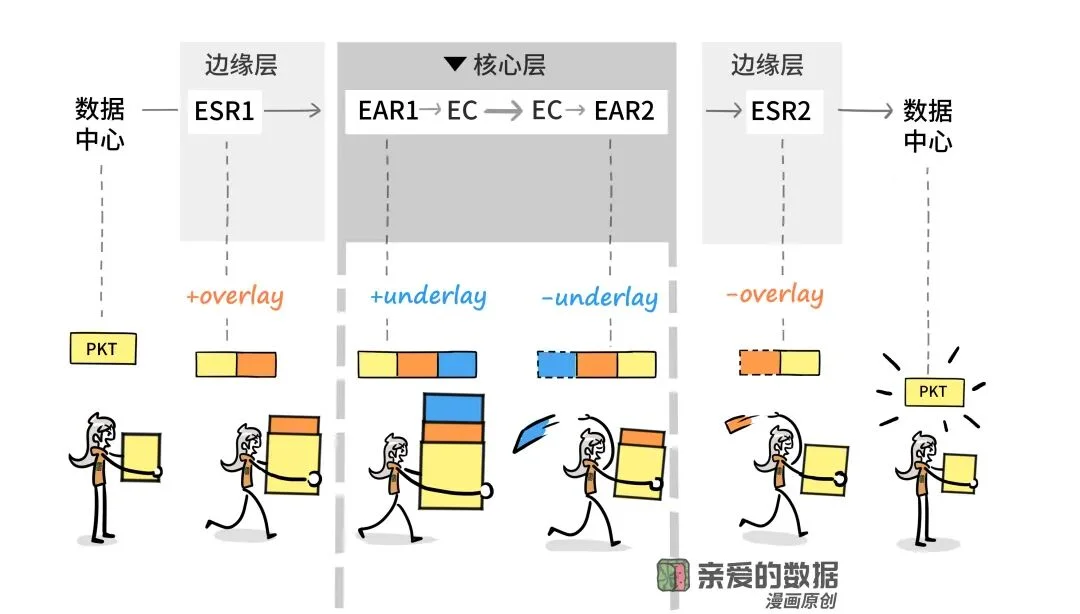
我们按照进出的顺序撸一遍,
当要传输内容从数据中心出去时,
怎么走呢?
首先,会经过边缘路由器,
这些路由器擅长处理数据的封装,解封装。
接着,数据流会进入核心层路由器,
在这些核心路由器上,计算最优路径,
简而言之,核心层和边缘层的划分,
体现在路由器负责工作的不同。
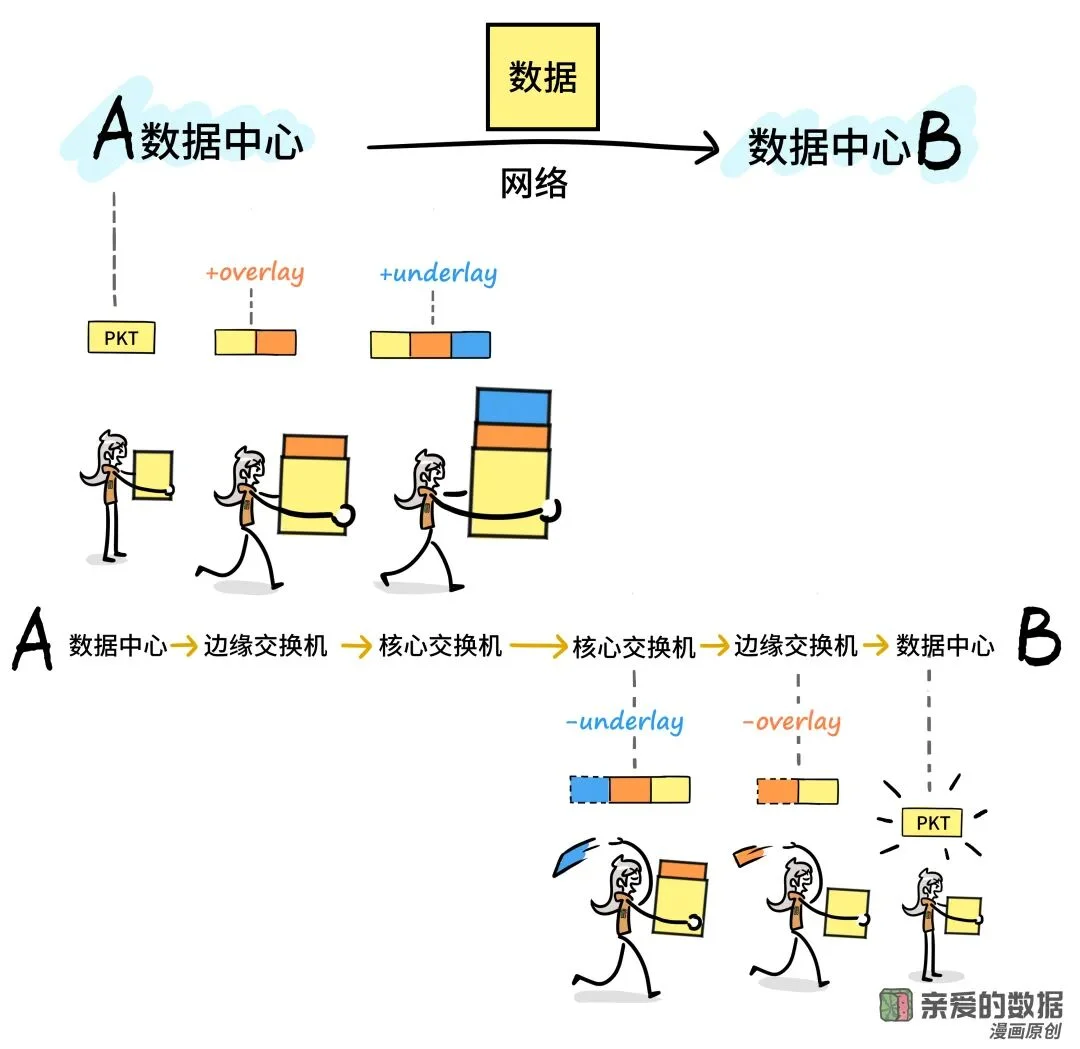
怎么进出数据中心?
得好好理解核心层和边缘层,
再捋一下《数据中心一日游》攻略:
1.PKT(原始发送的内容)先到ESR:
数据包从源头出发后,
首先到达ESR(Edge Service Router)层。
在此阶段,原始数据包(PKT),
会被封装(overlay网络),
形成一个新的封装层,
使得数据包可以通过虚拟网络进行传输。
2.ESR封装后,进入EAR:
给数据包封装(underlay网络),
通过EAR(Edge Access Router),
进入underlay网络。
尽管数据包仍然带有overlay封装,
EAR会给数据包加上封装(underlay网络),
使其能够在物理网络中转发。
EAR负责将带有封装的数据包
(overlay和underlay),
传输到下游网络。
3.数据包走出EC设备,
会在EAR剥掉封装(underlay网络),
再在ESR阶段把封装剥掉(overlay网络),
走出EAR和ESR之后,
进入数据中心前,会恢复为原始数据包(PKT)。
(六)为何服务得更细腻
理解这点,需要理解源路由技术,
英文名,Segment Routing,SR;
有了SR,用上SRV6协议,
才能有提供精细服务的可能。
当然落地还需要芯片,
思科公司Silicon One芯片。
不过,得单拎出来讲;
这篇到此,下篇见。

文章来自于微信公众号 “亲爱的数据”,作者 “亲爱的数据”



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
