# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

机器学习部署在边端设备的时候,模型总是存储在云端服务器上(5G 基站),而模型输入输出总是在边端设备上(例如用照相机拍摄照片然后识别其中的目标)。在这种场景下,传统有以下两种方案完成机器学习的推理:
这种方案需要每个用户分别把自己的模型输入上传到云端,然后在云端完成推理,最后把模型输出下载到各个用户。
这种方案需要消耗大量的带宽资源,尤其是在大用户规模的情形下;其次,这种上传用户模型输出的方案会涉及用户隐私泄露的问题。
这种方案要求是云端服务器把模型广播给所有的用户,每个用户各自存储模型,并且在边缘端进行计算。
这种方案极大挑战了边缘用户的算力,并且在模型存储的过程中还有边端存储读写的开销。
在我们的工作里,我们提出了第三种分离式计算(disaggregated computing)的方案:广播模型并在射频上完成计算。
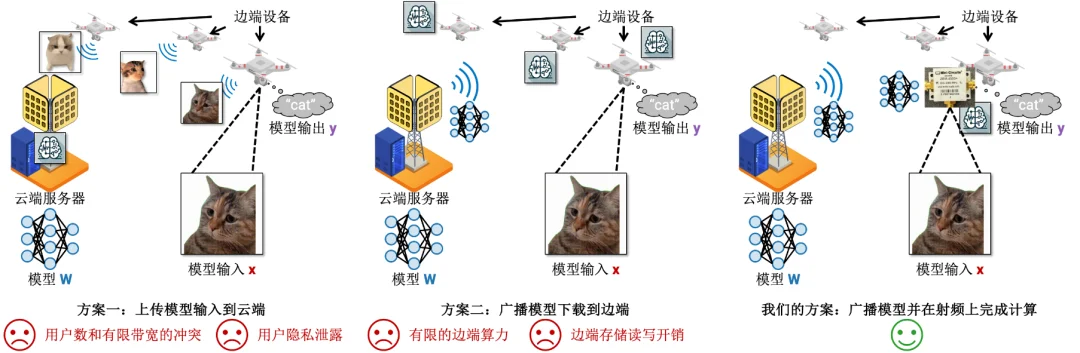
在这种方案里,模型存储在云端并且在射频上广播,用户也把模型输入调制到射频上。所有的计算都在边缘端的混频器(frequency mixer)的模拟计算中完成,混频器输出直接就是模型的输出。
这种方案成功解决了上述两种方案的问题:模型不需要存储在边缘端,所以没有存储读写的开销;混频器是所有带网络连接功能的边缘设备的必备元件,并且是无源的,所以功耗极低。
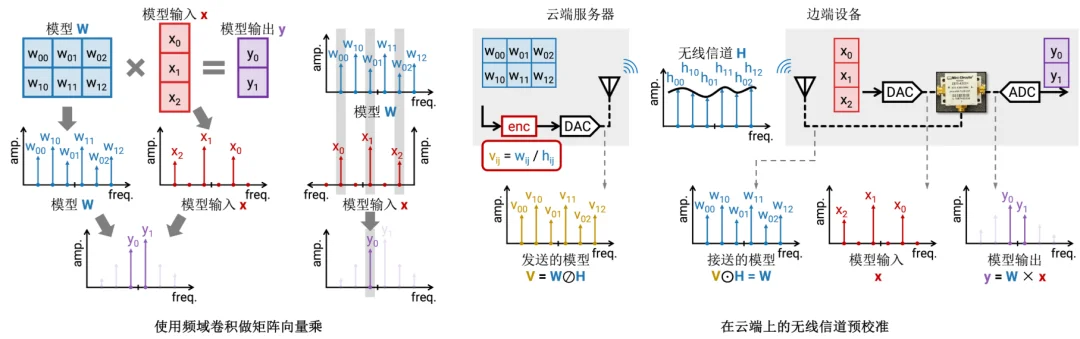
混频器的本质是一个时域上乘法器。它把收到的射频信号和本地震荡器产生的信号相乘,输出就是解调后的基带信号。在我们的工作中,我们把射频信号换成了广播的模型,本地震荡器的信号换成了模型输入,于是混频器的输出就成了模型的输出。
在数字信号处理中,时域上的乘法就是频域上的卷积。当我们把模型推理过程抽象成矩阵向量乘 y = Wx 的时候,我们就可以用卷积来完成这个矩阵向量乘。
另外,我们还需要提前在云端测量无线信道 H。在发送的时候就预调制一个无线信道的逆变成 V,这样通过无线信道后在边缘端接收到的信号就变成了我们希望得到的 W。
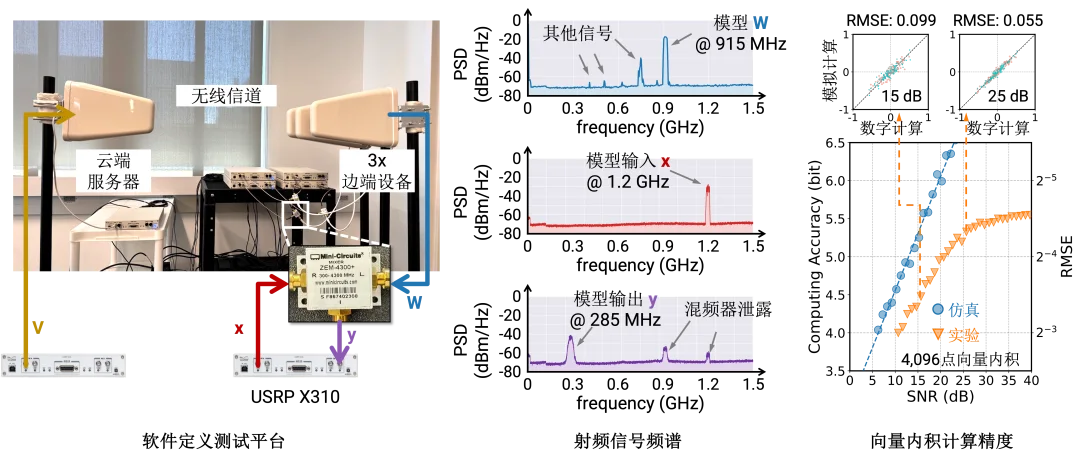
我们实现了一台云端服务器广播给三个边缘设备的机器学习推理。我们在软件定义测试平台(software-defined radio testbed)上进行实验验证,其中我们使用 USRP X310 作为主要的无线收发机,外接 ZEM-4300+ 作为主要的混频器。
我们使用了 915 MHz 的频率和 25 MHz 的带宽来无线广播模型。
我们先考虑了通用复数域的 4096 点的向量内积进行计算精度的测试,实验上得到的最高计算精度能达到 5.5 bit,对于大部分机器学习推理已经足够。
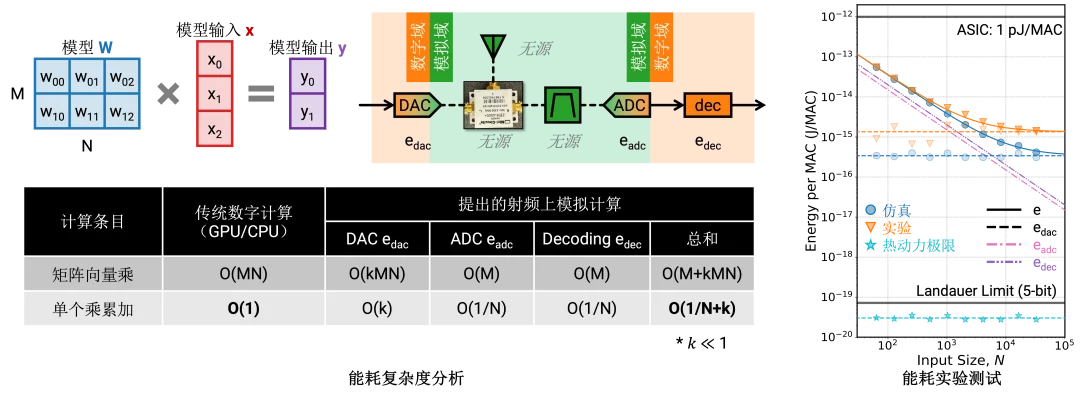
考虑一个输入维度是 N,输出维度是 M 的矩阵向量乘,我们的模拟计算架构能耗来源于三个部分:
综上所述,整个系统的能量消耗是 O(M + kMN) 对整个矩阵向量乘;均摊到一个乘累加(MAC)上就是 O(1/N + k)。也就是说,计算的矩阵向量乘规模越大,单个乘累加的能耗越低。
在我们的实验平台上,我们实现了最高到 32768 点的向量内积,能耗可以达到飞焦级,比传统的数字计算(皮焦级)低了 2~3 个数量级。

在 MNIST 数据集上,我们训练了一个单全连接层的机器学习模型(等价于逻辑回归),我们展示了一个视频样例。
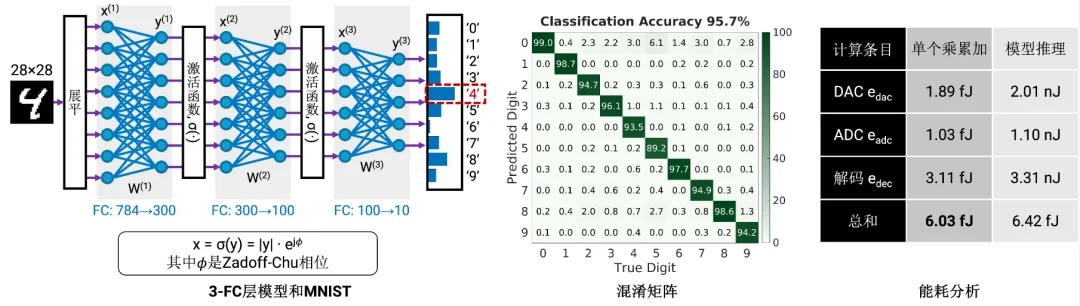
此外,我们也考虑了三个全连接层的模型,传统的数字计算可以达到 98.1% 的精确度。在用我们的框架时,精确度可以达到 95.7%,但是能耗仅需 6.03 fJ/MAC,也就是一次推理共计6.42 fJ。
我们也考虑了其他机器学习任务,例如 AudioMNIST 数据集上的语音识别,精确度达到了 97.2%,而能耗下降到了 2.8 fJ/MAC。
我们的核心创新包括:
神经网络模型被编码为无线射频信号,由中心无线节点统一广播,覆盖范围内的任意数量边缘设备都可同步完成推理,实现真正的「计算即广播」的多终端 AI 推理范式。
利用边缘设备中本就存在的射频频率混频器,该方法无需任何专用 AI 芯片或电路改动,就能在射频信号域完成乘加运算,实现真正「零额外能耗」的模拟计算。
通过频域编码,一个频率混频器即可完成高达 32,768 维的内积运算,突破了传统模拟计算在规模上的限制,能够支撑现代深度学习模型的推理需求。
文章来自于“机器之心”,作者 “杜克大学的高智辉、陈廷钧教授和 MIT 的 Dirk Englund 教授团队”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
