# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你懂OCR吗?2025年之前,可能人人都懂。
但2025年之后,你还认为你真的懂OCR吗?
是的,随着AI大模型研发在架构、记忆、存储等等领域的深水区创新,OCR重新成为了技术专项。DeepSeek在研究、智谱在研究、阿里千问和腾讯混元也都在研究……
那么,怎样才能速成AI时代的OCR呢?
还得是吴恩达老师,火速来了新课程,帮你速通OCR。
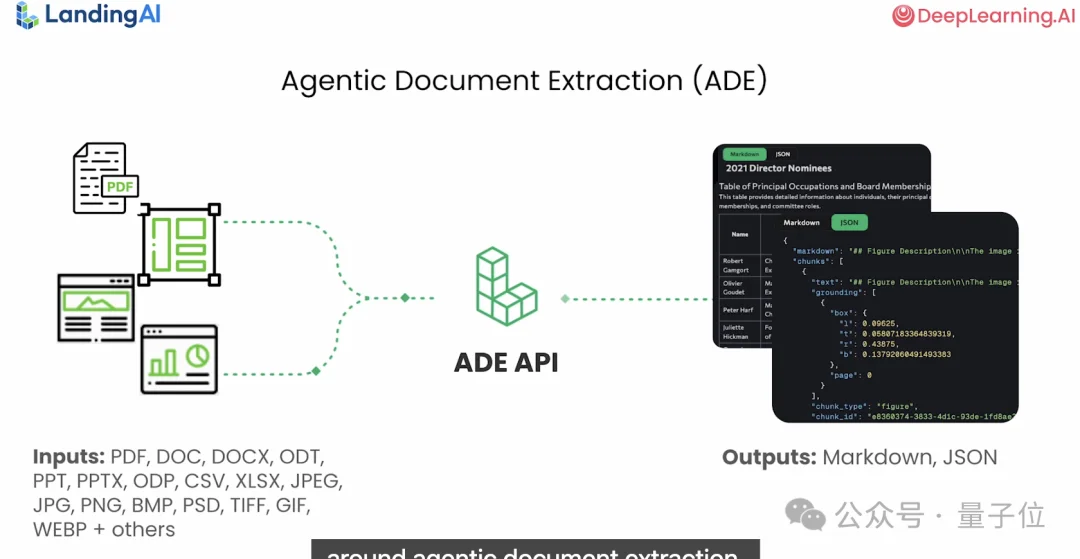
在新课程里,直接提出了一个新方案——智能体文档提取(Agent Doc Extraction)。
不仅是OCR技术在Agent时代的进阶,更是一个统一的智能体工作流。
并且这个方法在DocVQA基准测试中的准确率达到了99.15%。

新课上线,不仅手把手教你跑通本地代码,还给出了在AWS上部署的完整线路~
在介绍ADE之前,先来了解一下各大厂近期在OCR技术上的密集更新。
如果把目光放回到2025,就不难发现,吴恩达老师的这门课也是对这一技术深水区回归的及时呼应。
从10月份开始,DeepSeek让这项技术的讨论爆发。
DeepSeek-OCR玩起“视觉压缩一切”,靠专属视觉编码器把万字长文压成百个视觉token,在10倍压缩下仍能保持97%的高准确率,单块A100-40G显卡每天就能处理20万页以上文档。

几乎同一时间,智谱联合清华大学发布了Glyph框架,异曲同工地通过“文本渲染成图”的思路,把超长文本转成紧凑图像,轻松突破上下文窗口限制。
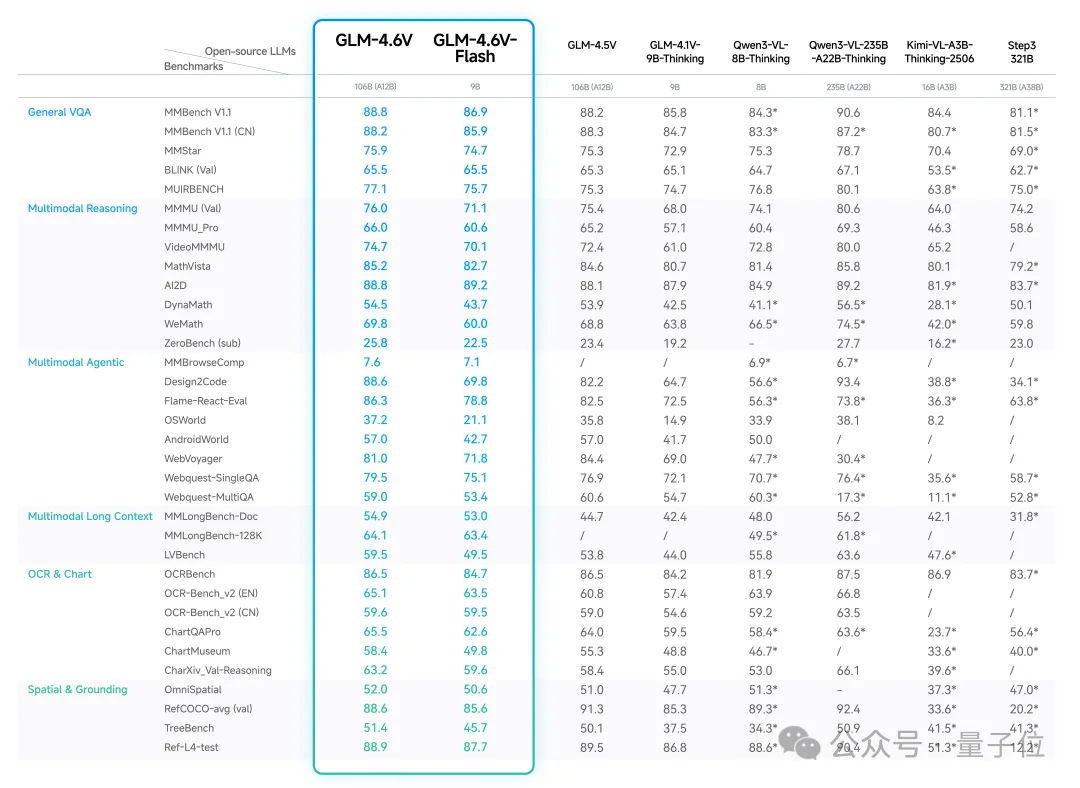
后续到了12月,智谱GLM-4.6V多模态系列正式发布,包含9B与106B参数版本。
前者在低成本本地OCR场景表现突出,支持复杂扫描、笔记与模糊文档;后者凭借128K上下文窗口甚至能跨页理解长税表、合同与科研图谱,把OCR拉向文档理解与知识抽取层面。
实际上,阿里千问10月发布的Qwen3-VL-30B等版本也在OCR领域有重要升级。
11月底的时候,腾讯混元也加入了这一轮集中突破,1B参数的HunyuanOCR开源后迅速受到关注。
虽然参数少,却具备处理表格、结构化文档、多语种内容的能力,运行速度快,易部署,很快成为开源热门。
机器学习大神吴恩达老师显然也意识到了OCR的大热趋势,火速出了一版速通课。
虽然不是教你怎么改进OCR技术,但教你怎么给OCR装上智能体大脑。

首先,课程详细回顾了OCR技术的演进。
从最早的规则时代到现在的智能体时代,每一步更新都是在填传统OCR的坑。
以前用Tesseract,全靠人工写规则;后来有了PaddleOCR,靠深度学习认字儿。
但它们在提取文字时都会把文档“压平”,导致表格结构、图注关系及阅读顺序等关键信息丢失。
这样一来,下游大模型拿到的就都是半成品数据,特别容易出现幻觉。
而课程里的ADE方案,相当于给OCR加了三大支柱,靠「视觉优先」策略看懂文档布局,用「以数据为中心」保证精准,再凭智能体化主动思考。
搭载DPT(文档预训练Transformer)模型后,ADE工作流将文档视为一个整体的视觉对象,去理解其布局和空间关系。
并且,DPT模型在DocVQA基准测试中取得了99.15%的高分,甚至超越人类。

在实战中,ADE也展现出了极强的鲁棒性。
超过1000个单元格的巨型表格、复杂的手写微积分公式,还是带有弯曲印章的证书,甚至是纯图示的安装说明书,它都能精准解析。
在落地层面,ADE引入的视觉接地技术,不仅能提取文字,还为每个数据块分配唯一ID和精确的像素坐标,并能生成局部截图。
这样一来,AI只要一回答某个数据是多少,你一点就能看到原始文件里对应的地方,做到“有图有真相”。
此外,课程还提供了极具实操价值的云端部署指南,教你怎么把这技术用到云端,在AWS上搭个全自动流水线。
把PDF传到S3存储桶,Lambda就会自动进行ADE解析,把结构化的Markdown存好,再让Bedrock知识库建索引,最后靠Strands Agents做成能记事儿、会推理的行业知识助手。
从认清楚像素里的字,到在云端大规模用起来,只能说,这3h的课程,“学不了吃亏,学不了上当”~
课程地址:
https://www.deeplearning.ai/short-courses/document-ai-from-ocr-to-agentic-doc-extraction/
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
