# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
3D模型的实例分割一直受限于稀缺的训练数据与高昂的标注成本,训练效果有待提升。
近年来使用成熟海量的2D实例分割数据来辅助实现3D实例分割成为了一个极具潜力的研究方向,但实现思路不尽相同。
近日IDEA计算机视觉与机器人研究中心(CVR,Computer Vision and Robotics)的张磊团队提出了一种名为OVSeg3R的开集3D实例分割学习新范式。
该范式基于团队此前发布的最强闭集3D实例分割模型SegDINO3D
拓展至开放词表,大幅缩小了长尾类与头部类的性能差距(差距从11.3 mAP降至1.9 mAP),实现了开集3D实例分割的性能飞跃。
与传统训练范式相比,OVSeg3R无需对输入点云进行人工后处理,也不需要高成本的物体3D掩码人工标注,大幅降低了3D实例分割的训练成本,有望让3D实例分割从“只能识别已知类别”的闭集模式,到“可识别未知类别”的开集模式实现商业落地,广泛应用于自动驾驶、智能家居、机器人导航等需要精准3D场景理解的领域。
 △ 视频1:从视频到开集空间感知工作流
△ 视频1:从视频到开集空间感知工作流

△ 视频2:OVSeg3R与闭集SoTA模型(SegDINO3D)感知结果对比可视化
3D实例分割,就是让计算机像人眼一样,看懂三维空间里的每一个物体,以及精准勾勒出每个物体的边界范围。
这项技术是自动驾驶、机器人服务等智能场景的“眼睛”,没有它,自动驾驶汽车就分不清行人与障碍物,服务机器人也找不到需要递送物品的桌子。
尽管3D实例分割技术已发展多年,但行业内一直存在一个无法绕开的核心瓶颈:3D数据的获取和标注成本太高,难度太大。
我们可以通过一个直观的对比理解这个问题:2D图像标注很简单,标注员在图片上框选物体、标注类别即可,一张图片几分钟就能完成;但3D数据标注完全不同,它需要处理的是一种由无数个三维坐标点组成的场景模型(即点云)。
标注员要在这个立体模型中,不断调整角度、逐点勾勒出每个物体的轮廓(即3D掩码)。这个操作不仅需要专业的3D建模知识,还极其耗时。
这种模式直接导致了3D感知模型的训练数据,在数量和类别丰富度上远远落后于2D图像数据。
行业内也尝试过通过外挂2D感知模型或者逐场景优化来解决这个问题,但这些方法大多存在明显的缺陷,典型的解决方案如:
1. 将3D感知模型的任务收缩到只需要输出3D掩码,掩码所对应的类别则通过投影回到2D上,然后让外挂的2D感知模型来接手分类任务。
简单说,就是让3D模型只负责“找到有物体”,然后把找到的物体投影回2D图像,让成熟的2D模型来判断“这是什么”。这种方法虽然利用了2D模型的强大分类能力,但3D模型本身发现新物体的能力没有任何提升,依然只能找到训练过的有限类别,无法应对未知物体。
2. 将多视角的2D感知模型的结果借助深度图投影到3D空间,然后再通过启发式算法通过人工设定的规则将多视角的感知结果聚合,让属于同一个3D实例的掩码聚合到一起。
这就像用多张不同角度的照片拼立体模型,看似可行,但拼接用的rule-based算法非常脆弱,一旦物体被遮挡、重建噪声过大,都有可能导致拼接错误,最终影响识别精度,性能上限低。
3. 通过3D高斯技术把3D场景投影成2D图像,用2D模型的识别结果来训练3D模型。
但这种方法有个致命问题:需要针对每个场景单独优化3D高斯表征,就像给每个房间单独画一张专属地图,无法通用,极大限制了模型的实用性。
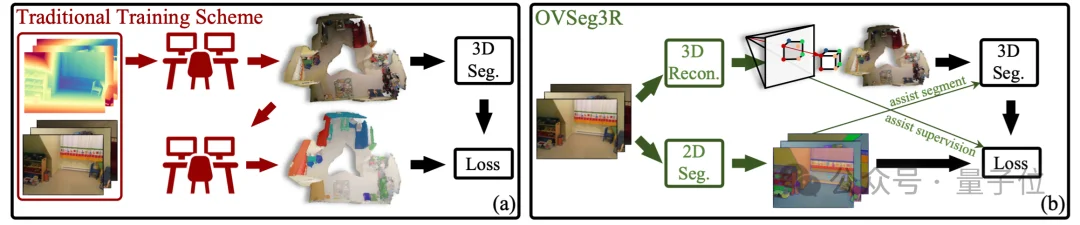
△ 图1 左图为传统的训练方案;右图是OVSeg3R的训练方案
正是在这样的背景下,研究团队提出了OVSeg3R,其核心思路在于:既然2D感知模型已经很成熟、数据也足够丰富,那就让3D模型向2D模型学习。
而连接两者的关键,就是3D重建技术。通过使用3D重建降低数据获取成本,同时用其提供的2D与3D映射关系,把2D模型的识别结果搬到3D空间,从而自动生成3D训练标注,形成数据闭环。
要实现3D模型向2D模型学习的核心思路,OVSeg3R需要解决两个关键难题:
一是3D重建结果通常比较平滑,就像把场景磨平了一样,一些几何结构不突出的物体(比如薄纸巾、扁平的垫子)会和背景融在一起,导致3D感知模型根本找不到它们;
二是如果简单地将各个视角的2D感知结果投影到重建出的3D场景中,那么,只要一个3D实例在一个视角下可见,就会产生一个标注,从而导致过多的重复的标注结果,极大地影响了模型训练过程的稳定性。
为了解决上述难题,OVSeg3R设计了一套清晰的学习范式,这个过程共分为3个阶段:
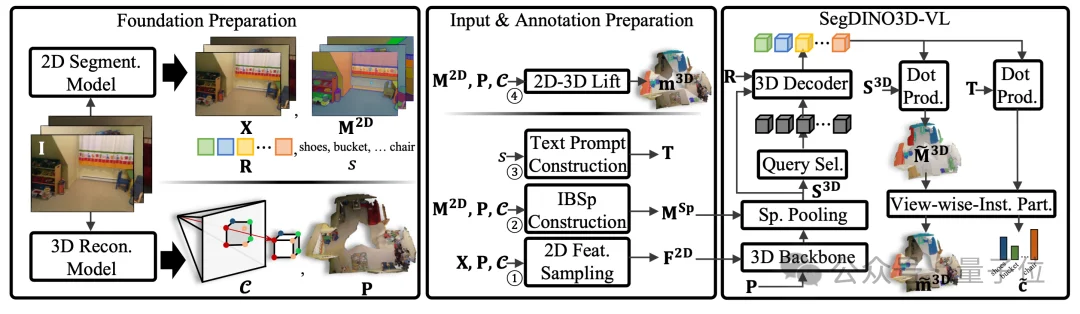
△ 图2 OVSeg3R的学习范式
首先,研究团队会输入一段场景视频。这段视频会被分成两条路径处理:
一条路径送入3D重建模型,生成场景的3D点云(也就是立体模型),同时得到2D图像像素与3D点云坐标的对应关系;
另一条路径送入成熟的2D分割模型,在获得图像级、物体级的特征(作为SegDINO3D特征补充)的同时,也会提供2D实例分割结果,以及对应的各个实例的类别名称。
这一阶段的核心是把2D模型的知识转化为3D模型能看懂的资料,同时解决3D重建平滑和重复标注的问题,具体做了4件事:
给3D点贴语义标签:获取每个3D点所对应的含有丰富语义信息的2D特征。
基于重建提供的2D与3D的对应关系,我们可以为每个3D重建出的点提供其所对应的含有丰富语义特征的2D图像特征。相比起SegDINO3D,这一步不需要额外计算相机参数来匹配2D和3D。
给点云分组:把庞大的3D点云划分成一个个小的超级点(superpoint)。
关键在于,划分不只是看几何结构是否连续(比如桌面上某块空白区域中的点彼此间很平滑、连续,则被归为一个超级点),还参考了2D分割结果作为判断超级点边界的依据(比如“相片”的点和“墙面”的点即使在几何结构上十分连续,也不会归为一组)。
研究团队把这种划分方式称为“基于实例边界的超级点(IBSp,Instance-Boundary-aware Superpoint)”(如图3中的(b)所示)。IBSp不仅提高了模型训练的稳定性,而且对于实际应用场景也十分有意义(用户通常没有3D传感器,输入通常为视频)。
制作分类参考依据:把2D感知模型识别出的所有物体类别名称拼成一个字符串,形成文本提示(text prompt),用来作为后续分割模型进行开集分类时的依据。当然,在实际推理时,用户可以指定任意的文本提示。
生成分视角标注:把每个视角的2D分割结果,通过2D与3D的对应关系投影到3D空间,生成每个视角对应的子场景3D标注(如图3中的(a)所示)。
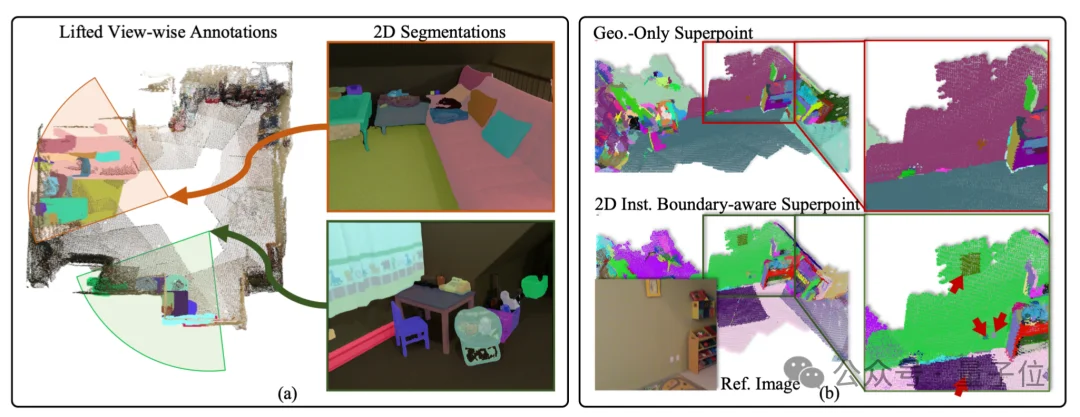
△ 图3 对应上述OVSeg3R技术中的两个关键步骤的可视化说明
这一步的核心是让3D模型(基于SegDINO3D拓展的SegDINO3D-VL)学习并掌握开集分割能力,具体过程可以分为“特征提取-解码-监督学习”3个环节:
特征提取:把3D重建得到的带噪点云,以及每个点对应的2D语义特征,一起送入3D骨干网络,提取出每个点的3D特征;再根据之前划分的超级点进行聚合,得到超级点级的3D特征。
特征解码:把超级点级3D特征送入Transformer解码器,解码出实例级特征。这些特征一方面会用来和超级点特征计算相似度,从而得到分割结果;另一方面,为了将分类能力拓展到开集,研究团队将这些特征和从文本提示拿到的文本特征计算相似度,从而拿到开集分类结果。团队将这个拓展后的SegDINO3D称为SegDINO3D-VL。
监督学习:研究团队设计了一个名为“视角级实例划分(VIP,View-wise Instance Partition)”的策略,把模型估计出的各个分割结果划分到到他们所属的视角,并用阶段2生成的分视角标注上进行监督学习。简单说,就是让模型只在当前视角的标注范围内学习,从而避免把其他视角的重复标注计算进来,极大地提升了训练的稳定性。
通过上述方案创新,OVSeg3R在极具挑战性的ScanNet200 3D实例分割基准测试中,不仅大幅超越所有现有开集模型,同时刷新了闭集模型的最新记录,将长尾类与头部类的性能差距从11.3 mAP骤缩至1.9 mAP,彻底改善类别性能不均衡问题。
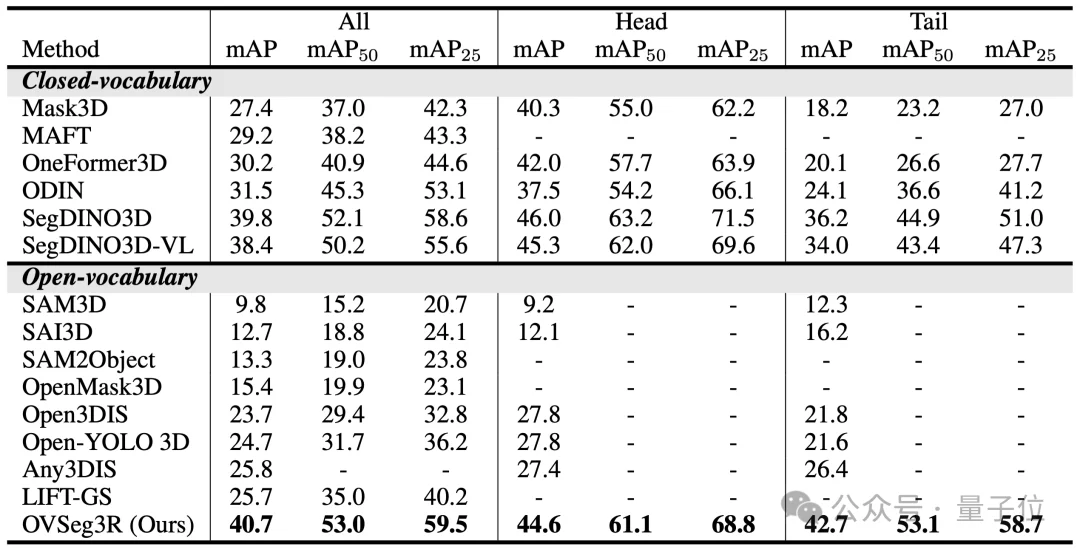
△ 图4 OVSeg3R刷新ScanNet200 3D实例分割基准的闭集和开集记录
不仅如此,在标准开集设定下(仅用20类人工标注训练,需在200类上测试,其中与人工标注的20个类别概念有显著差别的类别被定义为novel类别),从下表可以看出,在novel类上性能(mAPn)较此前最优方法飙升7.7mAP,开集识别能力呈现显著优势。
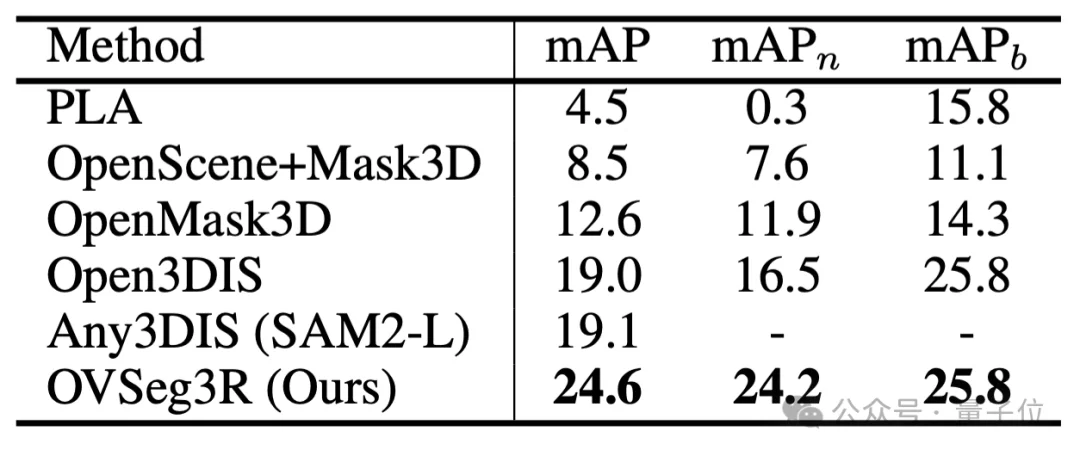
△ 图5 在标准的开集设定下,OVSeg3R在novel类别呈显著优势
如图6、图7所示,由于几何结构稀疏(比如三脚架)以及细小物体(比如瓶子、鼠标、插排)在充满噪声的点云上进行人工标注的难度很高,因此在现有数据集中,这些类别的缺失十分严重,导致已有算法无法处理这些类别。但OVSeg3R依然能将这些物体稳定地识别并分割出来。

△ 图6 OVSeg3R稳定识别出细小物体和几何结构稀疏物体

△ 图7 更多in-the-wild的结果可视化
OVSeg3R强大的成本和开集识别优势,有望在推动开集3D实例分割落地发挥重要作用。以具身智能为例:
OVSeg3R正在打破制约具身智能发展的“数据成本”与“开放世界”双重壁垒。
通过消除对昂贵人工3D标注的依赖,OVSeg3R利用3D重建与2D基础模型从原始视频中自动生成高质量语义标签,显著降低了机器人感知系统的训练与迁移成本。
在语义导航与长程规划中,OVSeg3R的开集识别优势使其能精准定位训练集中未见的“长尾”物体。
例如,它能成功识别几何特征微弱的电源插座或细长的三脚架,有效解决了在传统数据集上训练出的模型对扁平或细小物体“视而不见”的难题,确保了机器人自主充电与避障的安全性。
在精细操作场景下,OVSeg3R利用2D视觉的丰富纹理弥补了3D几何的不足。
面对白色塑料袋等几何模糊、易与地面混淆的非刚性物体,OVSeg3R能凭借其IBSp(2D实例边界感知超点)技术生成精确的3D掩码,为机器人抓取与导航应用奠定空间感知基础。
作为一种可扩展的“数据引擎”,OVSeg3R将海量视频转化为机器人的3D语义知识,不仅解决了Sim-to-Real的语义鸿沟,更为构建低成本、高泛化的通用具身智能系统铺平了道路。
现阶段,该技术成果的产业转化已取得进展,并由IDEA孵化企业视启未来主导推动落地。
文章来自于“量子位”,作者 “IDEA团队”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
