# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025年,风光无限的机器人们在Demo中大秀绝活,从叠衣服、工厂和物流站分拣包裹,到零售店卖货……它们忙碌的身影存在于各种各样的场景中。但回到现实世界,具身智能真正参与的生活和生产环节,却少之又少。
机器人落地干活难的真正阻碍,在于它们泛化能力弱。2025年的主流技术路线VLA让具身智能可以通过海量标注数据学习动作,但这只是“记住”了特定场景下的动作序列,而非“理解”任务逻辑。所以如果换了环境、操作物体,机器人就没法“举一反三”。
以物流搬运场景为例,2025年主流VLA路线,更多是通过大量数据,让机器人见过各种各样的货箱和搬箱子的动作学习这件事。但是机器人通常只学到了动作姿势,没有真正理解任务本身,所以遇到没见过的箱子可能就不会操作了。

(图源/视觉中国)
而且,使用一款机器人本体采集的数据,放到构型不同的机器人身上,就难以复用。
因此,具身智能基础模型公司眸深智能正在通过自研的世界动作模型(World Motion Model),赋予机器人理解物理规律和动作原理的通用能力,提升泛化水平,让机器人拥有一颗原生大脑。
正是出于对上述新技术方向的认可,上海国和投资、徐汇资本和复容投资近期完成对眸深智能的数千万元投资,公司也已经完成了超3000万元订单签署。眸深智能的技术同时获得一级市场头部投资人和产业客户的双重认可。
眸深智能的技术积累,始于公司首席科学家、复旦大学未来信息创新学院教授陈涛的科研成果。
2018年,在2D图像理解领域深耕多年的陈涛判断:二维视觉智能会逐步触及天花板,关键突破口在于让机器理解并生成三维空间中的运动。
2022年,他做出3D MotionGPT,让计算机可以像ChatGPT一样通过输入语言指令,生成包含空间信息(XYZ)的动作序列——一个类似“火柴人”在运动的3D画面。
这项技术走向具身智能相关的创业,源自一次学科交叉的自然延伸。
3D MotionGPT发表后不久,复旦校内一位做机器人控制的学者向陈涛发出邀请:既然一句话能让“火柴人”做动作,能不能把这套能力落到真实机器人上,让机器人也能“听懂指令—生成动作—和物理世界交互”。
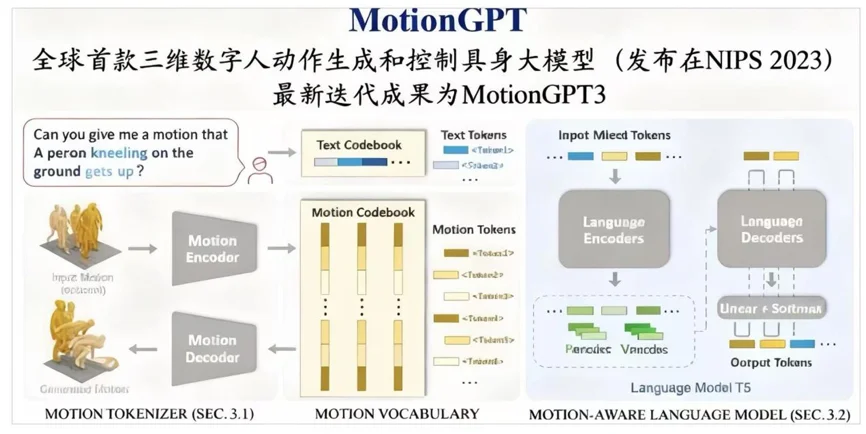
这一合作成为陈涛进入机器人大脑研发领域的起点,逐渐形成眸深智能自研的技术路径“世界动作模型”。
在行业语境里,VLA和世界模型构成了当下具身智能模型的两大技术流派,但二者皆有边界。
VLA更容易做出快、直观的效果,生态与开源数据也更成熟;但它强依赖“场景—动作”的数据覆盖,长尾变化一多,就容易出现“姿势像、但没做到位”的情况。
世界模型擅长在虚拟环境中对物理世界建模、预测与仿真,更像“仿真引擎”和“数据生成器”,但把仿真中学到的规律高保真迁移到真实机器人执行,仍要跨过控制、接触、噪声与工程化成本的鸿沟。
与之相比,世界动作模型更务实,它把世界模型中运动学的规律和知识装入其中,却不做泛泛的全世界建模。
“机器人的的功能要面向不同场景,同一个场景还有不同的任务,它们训练数据都不一样。比如工业场景的上下料,在什么位置、有多大角度,或者搬运物料的路径,全都不同。甚至还有健康居家、叠衣服备餐等等场景,如果说暴力地把这些数据放在一起,模型会很容易找不到自己的收敛函数以及优化目标,”陈涛详细阐释了世界模型在原理上的难点,并给出结论:“所以我认为,在机器人领域,世界模型短期还是很难去产生很好的效果。”
陈涛的判断是:机器人更可能先出现一批“小而精”的垂类世界动作模型,一个个具体场景和任务拼起来,再形成通用能力——比一步到位的“全世界模型”更可落地。
因此,眸深智能并非瞄准一个特定的场景,而是要为机器人打造一个通用大脑,第一阶段落地聚焦于工业及物流搬运、康养这两大方向作为机器人通用大脑的试验田。
至于眸深智能的技术路线怎么做,陈涛对硬氪做了通俗易懂的介绍。
简单而言,这条路线的关键,不是把能力拆成很多孤立模块,而是让机器人具备三层连续能力:
•对空间和物体的感知与定位:知道“物在哪、我在哪”;
•任务语义理解:可以听懂人的需求,明白自己要做什么事情;
•执行规划与动作生成:输出任务执行的路径规划、动作序列,并能根据环境变化动态调整与避障、协作,以及在遇到紧急情况时及时停止。
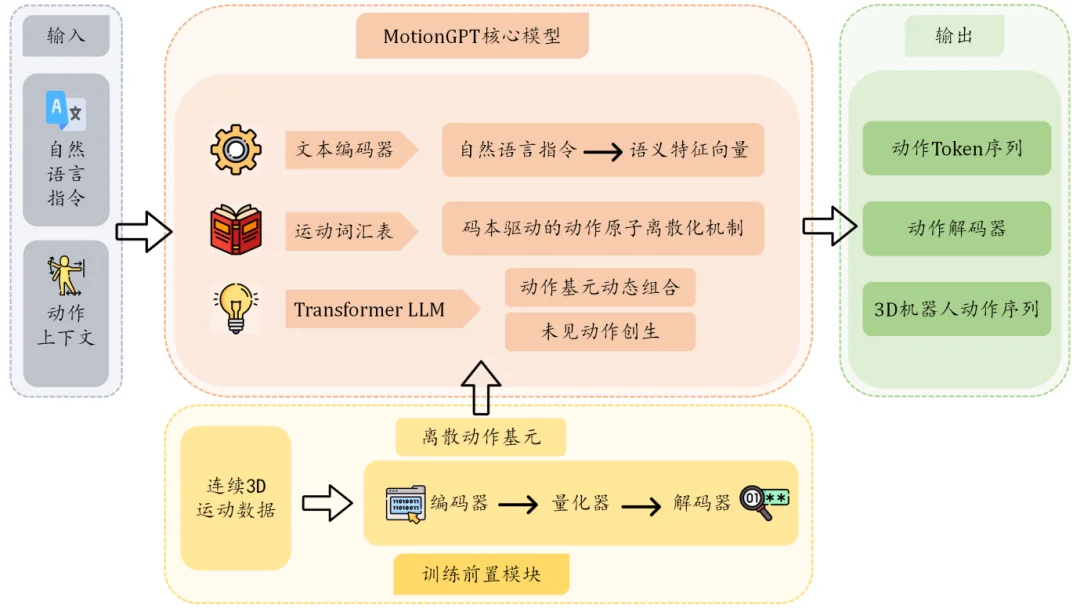
MotionGPT框架图
为了达到以上能力,世界动作模型在训练上大量使用互联网上的开源动作数据和开源视频——这是业内少见的数据使用思路。
数据配方上,比例可达到“80%开源视频+10%动捕数据+10%真机数据”。真机数据需求可降到传统方案的约1/10量级,这缓解了VLA对真机数据的依赖。
具体做法而言,团队从视频中提取人体关键点序列,做平滑与结构化处理,再用于运动模型训练;模型先在更通用的运动数据上获得“运动规律”的底座能力,随后再通过仿真与少量真机数据做适配。
因为模型学习的是任务与动作本身,所以这一路线可以达到很好的泛化性,在学习新任务时只需很少的数据和时间;同时,作为通用的大脑,世界动作模型的底座能力不与某一款机器人机型绑定,这也为跨本体控制留下空间。
而且,世界动作模型支持多模态信息输入,比如让机器人执行整理会议室桌椅的任务,既可以给它任务空间的视频、照片,或者空间的点云范围,也可以向它语音描述会议室的情况。这让机器人可以更灵活地知晓空间与任务,多模态配合也增强了机器人的理解。
第二个独特技术路径在于,世界动作模型把语言当作指令入口:机器人不只是“照着既定流程做动作”,而是能在执行过程中持续理解人的意图,并据此调整任务策略。这种多模态交互能力带来的直观体验是——机器人可以“随叫随停”,在现场实时改方向、换目标、调整抓取与操作。
举个例子,在眸深智能聚焦的康养场景里,陈涛借用了智驾的L1到L4做类比,给机器人能力分级:越往上,越考验持续理解、协同与闭环执行。按他的说法,最难的是类似L4的阶段——机器人需要围绕人的意图进行持续交互与自主决策;而更基础的L1阶段往往几乎不涉及复杂接触,更像“信息与服务层”的辅助,因此语音指令反而成为关键入口。
比如一个最基础的老人居家健康看护:老人意外摔倒后,通过语音让机器人向家属及医院发出求助。此时机器人不仅要“听见一句话”,还要把这句话落到现场行动。
它可能要放下手中正在干的活,执行这项更紧急的任务,然后需要判断自己处在什么场景、与老人和障碍物的相对位置如何、通道是否可通行,随后输出一套可执行的路径规划与运动轨迹,完成靠近、观察、呼叫与信息传递等动作序列,并在老人再次发声或环境变化时及时调整。
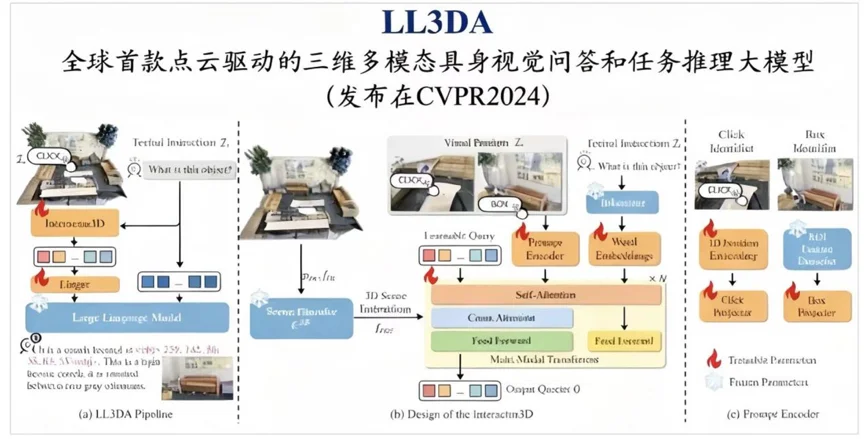
这套“语言驱动—理解环境—生成动作—落地执行”的链路,眸深智能将其组织为一条闭环:感知侧用LL3DA做三维感知与决策,规划侧用生成式MotionGPT做动作规划,再叠加自研的关节重定向、逆运动学的求解技术,把高层语义规划一路接到末端的动作控制,让机器人在真实场景里能更稳定地把任务做完。
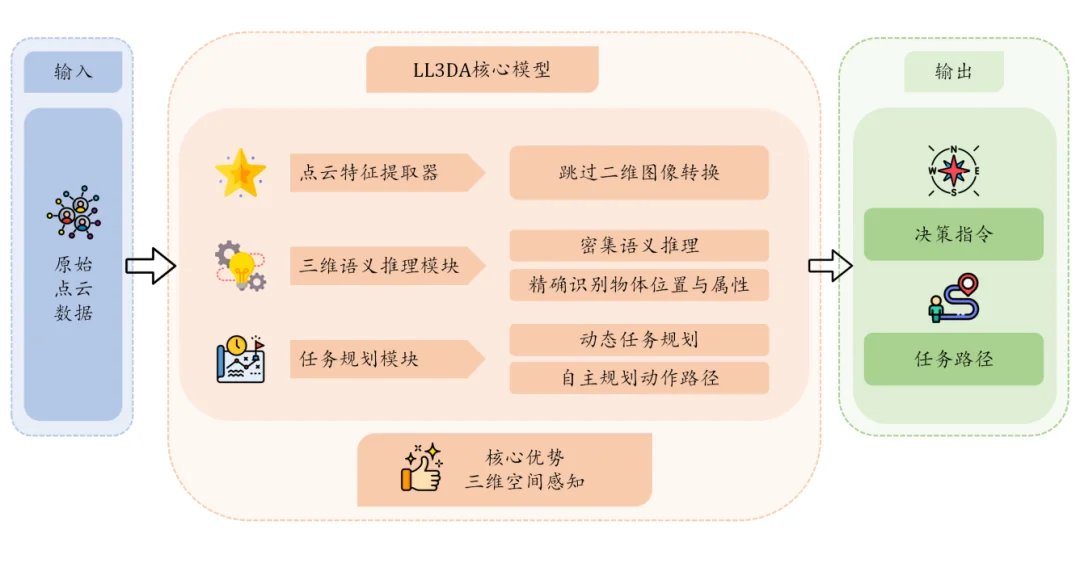
LL3DA框架图
解决了大脑的控制能力,具身智能里“能不能进场干活”还存在另一个工程问题:芯片带不动模型。
真实仓库和工厂不会等云端返回结果——网络抖一下、时延高一点,动作就可能变形,轻则抓不牢、走偏,重则碰撞和停机。因此,端侧部署模型,是一个很好的解法。
但端侧的卡点往往很直接——算力不够。

(图源/视觉中国)
眸深智能的代表性方案为MADTP动态令牌剪枝算法,用于百亿参数模型的端侧部署。
通俗易懂地说,就是把模型做“轻”:一方面做压缩,把体量很大的模型压到端侧可承载的规模;另一方面在推理阶段做动态调用,按任务复杂度调动不同参数量,避免端侧每次满负荷运转,从而把算力消耗压到可控区间。
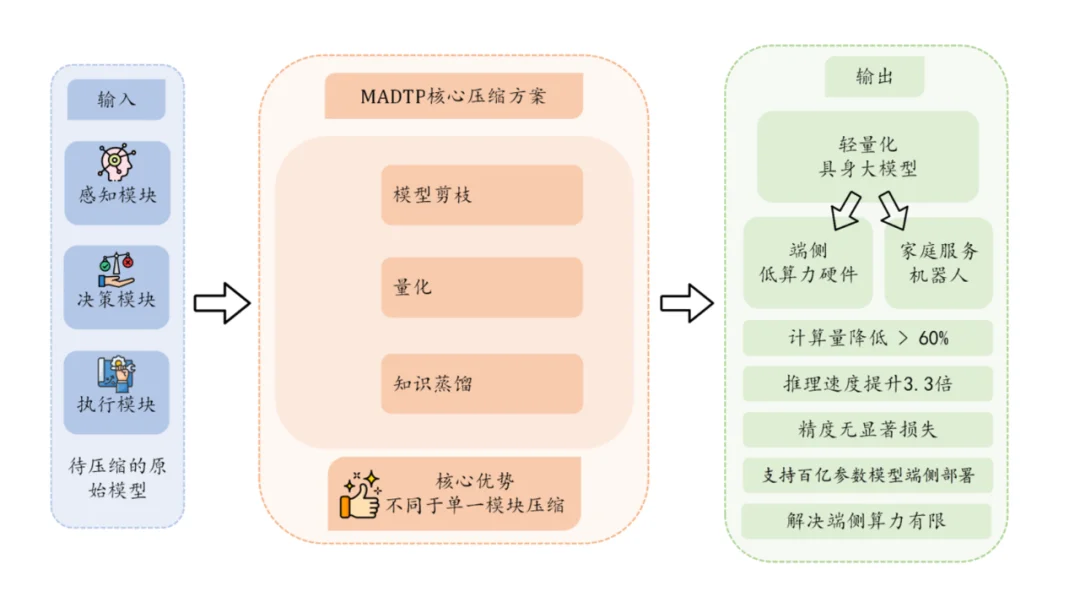
MADTP框架图
这些能力来自眸深智能的团队基因:核心成员不仅有高校背景的科研能力,也有软硬协同的产业背景。
首席科学家陈涛教授入选全球2%顶尖科学家,是复旦大学深度学习实验室负责人、上海创智学院教授、全球AI2000学者、国家高层次人才;曾就职于华为新加坡中央研究院,主导开发华为海思首代AI图像算法引擎“悟空”。
联合创始人张益民曾任英特尔中国首席科学家,长期深耕人工智能技术研发与产业化落地,目前指导眸深智能机器人工程化与技术架构优化。
从成果来看,世界运动模型可实现推理速度提升3.3倍,对单机端侧算力需求可降至原来的10%。同时,性能方面,还可以实现端侧最高20倍推理加速、关键响应延迟降至10毫秒级。
为支撑这些能力落到实际硬件,团队此前也在多种国产芯片平台上完成适配积累,包括昇腾310、910以及地平线J5、J6等,为后续端侧规模化部署打下基础。
公司关于具身大模型轻量化的研究成果获得IJCAI 2025全球最佳论文奖,陈涛也成为过去五年来唯一获此成绩的中国学者。
面向产品化交付,眸深智能计划于2026年推出标准化的“机器人大脑”模组,该模组搭载在具身智能本体之后,可将眸深智能的模型能力应用于机器人。目前,国内多家头部的芯片厂商已经和眸深智能建立了战略合作伙伴关系,共同推进产业前沿探索。
眸深智能的团队结构也服务于“从研究到落地”的目标:核心成员不仅有科研能力,也具备长期的商业化经验积累。
CEO穆泽林为连续创业者,负责战略、融资与客户拓展:曾参与掌门教育早期创办,并在华兴资本主导多家企业累计完成数十亿人民币融资项目;之后联合创办AI智能通信企业木心智能,带领团队实现年营收破亿并成功并购退出。
在产业协作上,眸深智能以“大脑提供者”的身份与上下游伙伴共同耕耘。
公司技术与宇树科技的机器人本体结合,在杭州的具身智能中试基地进行规模化验证;与工业自动化龙头禾川科技合作,为柔性制造车间提供智能搬运解决方案;也与国地中心等国家级创新平台共同攻关高端制造应用。
这种与本体厂商、场景方、集成商的多元合作,正在推动其技术从实验室走向产业闭环。
据穆泽林透露,眸深智能成立不到一年,已完成3000万元的订单和1500万元的交付回款,获得了产业客户的支持与认可。
一级市场对于眸深智能也展现了积极回应。
此轮融资的投资人、徐汇科创投总经理、孵化器基金负责人马熙表示:“眸深智能作为复旦大学科技成果转化、以大脑算法为核心技术的具身智能企业,研发团队具备在机器视觉和多模态具身模型领域的能力优势以及丰富的研发积累,徐汇资本出资参投有望推动区域具身智能产业集聚,有利于补强徐汇区具身智能产业链环节,更是对知名学府科技成果转化的支持。”关于本轮资金的使用计划,陈涛表示,将资金用于引进工程化人才、扩建算力集群与实体机器人训练场,持续提升世界运动模型的相关能力,并加速产业验证。
在百花齐放的具身智能行业,竞争火热,但热闹的估值和期待能否兑现,最终仍要回到一个共同标准:机器人能否在真实场景中稳定干活。指导机器人完成工作任务、并在变化环境里保持成功率的“聪明大脑”,成为具身智能产业链上关键一环。
文章来自于“硬氪”,作者 “硬氪”。


