# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
好消息,好消息,真·Sora视频上新了!走过路过不要错过!
(不用苦苦等候,或撑大眼睛费劲吧啦鉴别真假Sora产品了)。

就在过去短短几个小时里,包括Bill Peebles、Tim Brooks两位负责人在内的工作人员唰唰唰N连发。
(好了好了,知道你们是好朋友)
不仅有前所未的多视角、新功能展现,最重要的是,各个视频的呈现效果依然处于令人惊叹的段位。
比如Go Pro视角下潜水去探索沉船。

比如下面这段视频,效果跟此前写实、逼真的画风有点不一样。
而且Sora产出的是同一片段的不同视角画面。

它的提示词是:精心制作的立体模型,描绘了日本江户时代的宁静场景。传统的木结构建筑。一个孤独的武士,穿着复杂的盔甲,缓慢地穿过城镇。
另外比较惊艳的还有一头大眼睛、长睫毛、口喷冷气的小白龙,就是下面这位:

有人尝试用同样的prompt在DALLE·3上画画,得到的结果是这样的:

就,还挺神似!
但Sora小白龙的效果让某种声音越来越大,那就是:
好家伙,我一眼就看出这玩意儿有虚幻引擎的影子!

不过,这波视频还是惹得网友们wow wow的,不停惊叹,怎么Sora每波视频效果都越来越好了?
我的天爷啊,等Sora公测开放等得大家一天只能吃下三顿饭了!
有的网友超级激动,已经在知名新产品挖掘平台ProductHunt上给Sora的API站好了坑。
万事俱备,只欠东风。
首先来看看Sora这波上新,此次最惊艳的是由玻璃制成的乌龟,日落时分在沙滩上爬行。

不过也有细心的网友发现:“我只看到了三条腿…”“前面两条腿更像乌龟的脚蹼”


而在Midjourney上使用相同的提示,效果是这样的。

另外,多个视角展现也成为了此次上新的亮点。
比如在夏威夷玩跳伞。

提示词:a man BASE jumping over tropical hawaii waters. His pet macaw flies alongside him(一名男子在夏威夷热带海域进行低空跳伞,他的宠物金刚鹦鹉与他并肩飞翔)
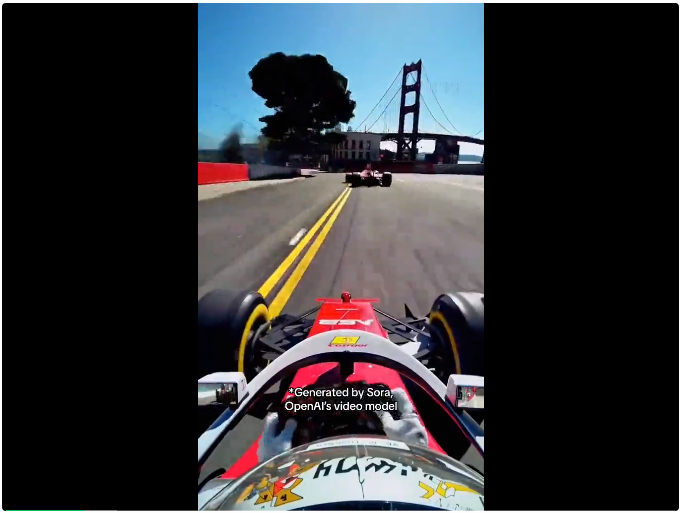
甚至还有F1赛车手的视角。
此外,Sora还暴露了一些类似剪辑的新功能——无缝衔接。
此前看到,它能通过文本、图像或视频输入对模型进行提示。
如今发现,它还可以在两个输入视频之间逐渐进行插值。两个毫不相干的Sora视频,结果无缝过渡成了新视频。

咳咳,不过水下为啥会有蝴蝶??
任意尺寸比例生成,此次新视频也得到了展现。
以下视频来源于
QSQT

不过由于悉数都是Sora团队成员发布的视频,有网友觉得,除非有个非OpenAI工作人员才测试,不然Sora就是个vaporware(雾件)
这些案例中,也有被认为翻车的……
提示词:a dark neon rainforest aglow with fantastical fauna and animals(黑暗的霓虹雨林,闪烁着奇幻的动物和动物的光芒)
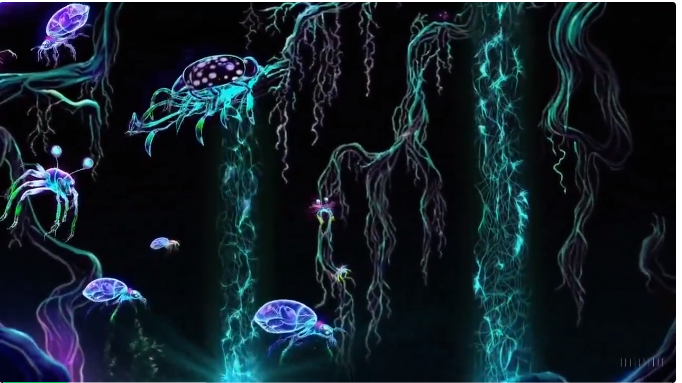
网友表示:为什么会是矢量动画的风格,提示中根本并没有这样的提示。
这是我见过Sora最糟糕的例子
与此同时,关于Sora所生成视频的讨论重心,逐渐从“这不符合物理世界的规律”,转移到更深层次——
关于其背后训练数据来源的讨论。
现在的民间主流说法(doge)是:
这绝对用了3D引擎/UE5来训练的!

英伟达科学家、大家伙熟悉的老盆友Jim Fan老师就在首日猜测过,称Sora虽然没有明确表示调用了UE5,但极有可能把用UE5生成的文本、视频当作合成数据,添加到自个儿的训练集中。

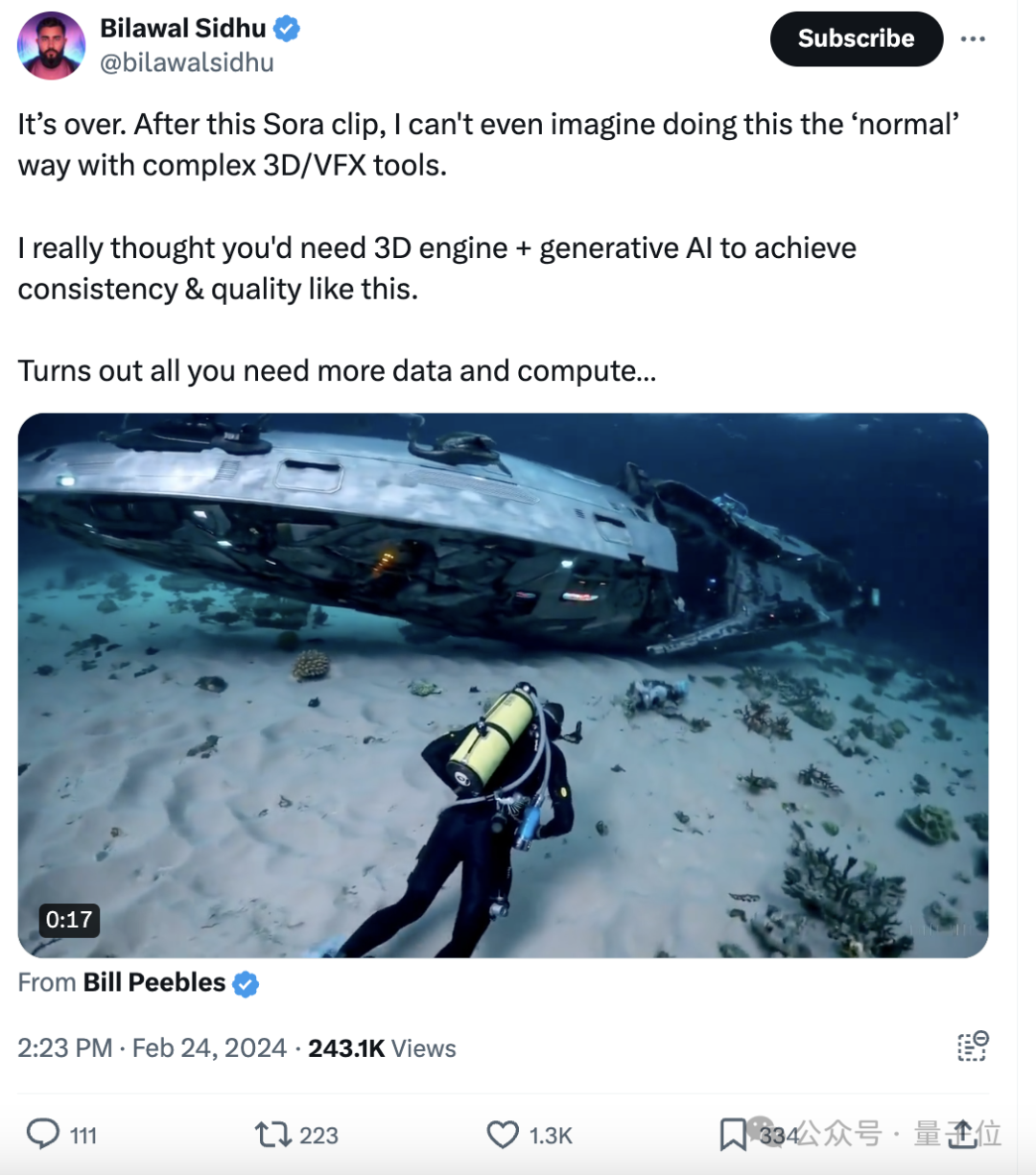
也有一位前谷歌工作人员对Sora这次的新视频进行了在线锐评:
Sora这效果,我真的认为需要3D引擎+生成式AI结合,才能实现这样的一致性和视频质量。
事实证明,就是得要更多的数据和计算……
倒不是Jim Fan等人的一家之言。早在第一波Sora视频亮相时,这种声音就第一时间起来了,声量还很不小。
再多举个。
一位从事数据科学和ML的推友罗列出了自己站队这种观点的“证据”。
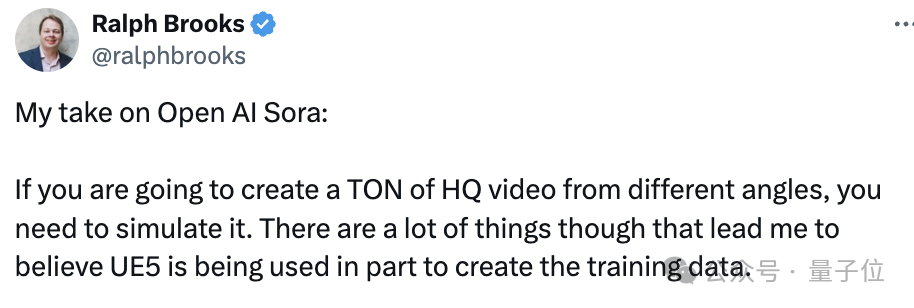
他亮出的牌是漫步樱花街头的那段视频。
然后配文道:“视频中移动的人似乎与UE5演示中的人类的移动方式非常相似。现实中的人走路逛街,并不会老用一个恒定的速度。”

也有人质疑这种说法,毕竟Youtube等互联网上拥有数十亿(可能还不止)小时的视频片段,干啥要用虚幻引擎来增加工作量呢?
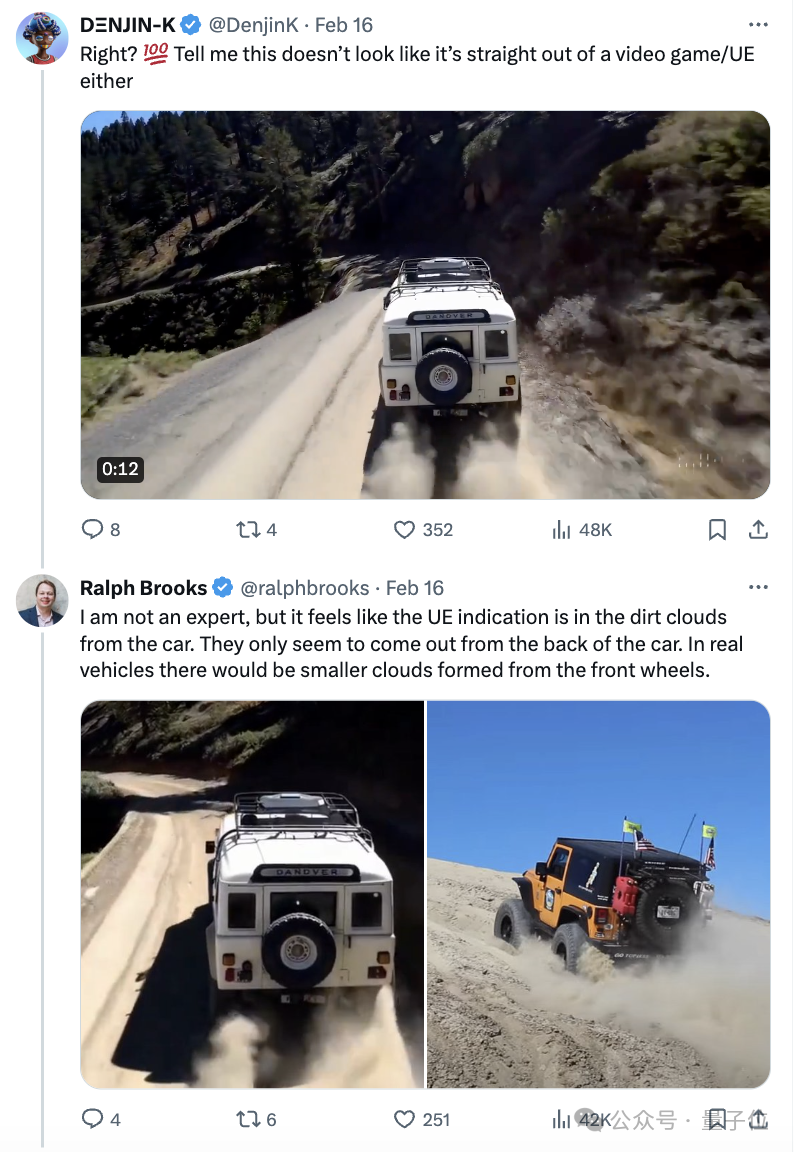
于是就有人把“汽车行驶”的视频片段丢到上面这位推友小哥面前,说这看起来也不像是用了3D引擎搞的呀!
小哥友好地嘚吧嘚嘚吧嘚,开始了自己的分析:
“我不是专家……但感觉UE让汽车行驶掀起的尘土,只在后轮部分有。但其实现实情况中,前轮部分也会扬起尘沙。”
当然也有不少人赞同他,附和道:
虽然不一定用的是UE5吧……但事实确实是,用数字孪生模拟可能效果和效率都更好。
而且这样还能用较少的IRL数据进行更高质量的数据采样。
以及还有人把自己理解中Sora的pipeline都列到推特上了。

这种讨论大规模流传开后,不少人对Sora可能是“UE5+AIGC”产生的效果嗤之以鼻。
“哼!我话放在这儿,合成数据是视觉机器学习的作弊代码!!”

同时有人从这种讨论中看到了不久之后的一种可能性。
即未来的生成不是通过模拟真实物理来呈现,而是通过训练模拟物理模拟(即现实世界)的模型来呈现。
嗯……咱就是说,谁能一口否定没有这种可能呢?
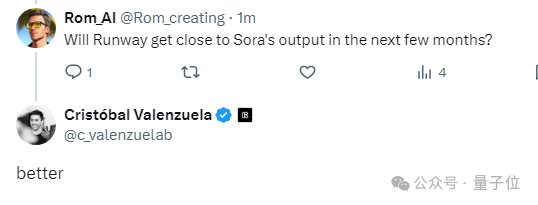
Sora上新视频后,有网友急冲冲去问了另一家AI视频生成头部玩家Runway的首席执行官。
“最近几个月,有发布新版本的打算吗?就是质量接近Sora的那种~”
Runway CEO冷冷回了一个词儿:
better
参考链接:
[1]https://twitter.com/minchoi/status/1761367515777695965
文章来自于微信公众号“量子位”(ID: QbitAI),作者 “白交、 衡宇”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
