# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
始智AI wisemodel.cn开源社区
始智AI wisemodel.cn社区将打造成huggingface之外最活跃的中立开放的AI开源社区。“源享计划”即开源共享计划,自研的开源模型和数据集,以及基于开源成果衍生的开源模型和数据集等,欢迎发布到wisemodel.cn社区,方便大家更容易获取和使用。
龙年伊始,Sora横空出世,举世震惊。Sora声称“作为世界模拟的视频生成模型”,豪气干云。有人悲观预言很多传统领域可能被颠覆,其中最为岌岌可危的可能是计算机图形学,短视频和影视娱乐行业。依随OpenAI透露出更多技术细节,很多Sora生成的物理悖谬的视频流传于网络。这里笔者依据现代数学特别是整体微分几何领域的一些观点来解释目前Sora技术路线中的缺陷,希望能够抛砖引玉,为广大AI研究和工程人员拓宽思路,共同促进提高。这里主要用流形嵌入理论、灾变理论(临界态理论)、纤维丛示性类理论、热扩散方程和最优传输方程(蒙日-安培方程)的正则性理论来解释。
流形分布定则
在深度学习领域,一个自然的数据集被视为一个流形上的概率分布,这被称为是流形分布定则。我们将观察到的一个样本看成是原始数据空间中的一个点,大量的样本构成原始数据空间中的一个稠密点云,这片点云在某个低维流形附近,这个流形被称为是数据流形。点云在数据流形上的分布并不均匀,而是满足特定的分布规律,被表示成数据概率分布。
那么,我们自然产生如下的疑问:1. 为什么数据点云是低维的,而非占满整个原始数据空间?2. 为什么点云集合是流形,即局部是连续光滑的?
关于第一个疑问的回答是:因为自然现象满足大量的自然规律,这些规律的限制降低了数据样本点云的维数,而无法占满整个空间。比如,我们考察所有自然人脸照片构成的数据集,每个采样点是一张图片,像素的个数乘以3就是原始图像空间的维数。原始图像空间中的任意一点,都是一幅图片,但是极少的图片才是人脸图片,才会落在人脸图片流形上,因此人脸图片流形不可能占满整个原始图像空间。人脸需要满足很多自然的生理学规律,每个规律都会降低数据流形的维数,例如左右对称,就减少了近一半的像素,都有五官等确定的几何与纹理区域,每个器官的形状类似,描述的参数不多,因此进一步降低维数。最终控制人脸的基因非常有限,由此人脸图片流形的维数远远低于图片像素个数。
再如,我们观察平面区域的稳恒态温度分布,由物理热扩散定理,稳定函数满足经典的Laplace方程,由其边界值所唯一确定。如果我们在区域内部有n平方个采样点,在区域边界有n个采样点,那么每个观察到的温度函数被表示为维数为n平方的向量,即原始数据空间维数为n平方,但是实际的流形维数为边界函数的维数n。由此可见,满足物理定律的观察样本构成的数据流形维数远远低于原始数据空间维数。
关于第二个问题的回答是:绝大多数情形下,物理系统是适定的,但在临界状态下,物理系统会发生突变(由灾变理论或者临界态理论来描述)。物理定律多由偏微分方程系统来描述,微分方程的解由初始值和边界值来控制,系统是适定的,意味着由于能量守恒、质量守恒、能量传递小于光速等物理限制,初边值逐渐变化时,解也随之逐渐变化。在偏微分方程的正则性理论中,这意味着边值的索伯列夫范数控制解的索伯列夫范等等。我们将解视为数据流形上的点,边值视为其对应的局部坐标(即隐空间中的对应隐特征向量)。
从数据流形到隐空间的映射被称为是编码映射,从隐空间到数据流形的映射被称为是解码映射。正则性理论保证编码映射和解码映射是连续的乃至光滑的,解的唯一性保证这些映射是拓扑同胚或者微分同胚。边值可以任意局部扰动,即隐变量存在一个开欧式圆盘的邻域。这意味着满足特定物理定则的观察样本构成了数据流形。
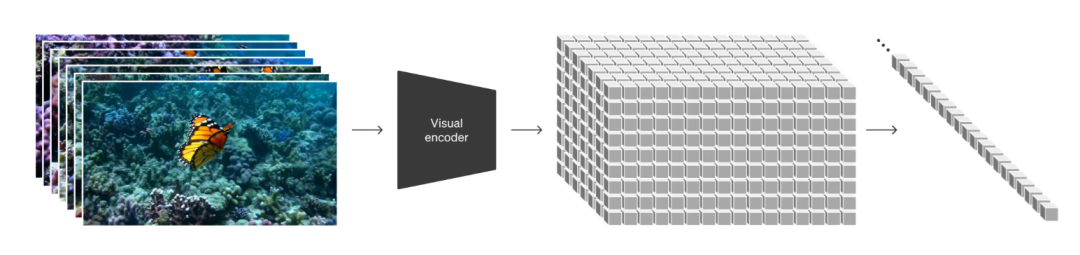
图1. Sora 将视频编码映射到隐空间,再切割成时空补丁,被称为时空令牌(time-space token)。(openai.com)
如图1. 所示,Sora的训练集为短视频集,每个样本是一个短视频,同类的短视频构成一个数据流形。Sora将其编码到隐空间进行降维,然后在隐空间中将隐特征向量切割成补丁,加上时间顺序,构成时空补丁,亦即时空令牌(time-space token)。这里时空的概念是比较关键的,每个令牌在短视频的帧序列号(时间),在当前帧的行列序号(空间)都被记录在令牌里。
概率分布变换
我们可以进一步问如下问题:3. 数据流形上的概率分布如何表示?
关于第三个问题的回答是:用传输变换,将数据概率分布变成计算机可以生成的高斯分布。这个传输变换可以在原始数据空间中进行,也可以在隐空间中进行。常用的传输变换包括最优传输变换和热扩散。我们用流体力学的观点来解释。假设整个隐空间是一个水箱,里面有某种溶剂,其密度为概率密度。我们扰动水箱,使得液体流动起来,使得溶剂密度发生变化。我们计算每个水分子的流向和流速,使得概率密度的熵一直增加,最后就得到高斯分布。例如,我们考虑人脸数据分布,这里每个水分子就是一张人脸图片。我们为人脸图片不断添加噪声,得到一系列图片,直至变成一张白噪声图片。这一系列图片就是水分子的运动轨迹。最后每张人脸图片变成白噪声,所有这些白噪声分布满足高斯分布。这一过程被称为是郎之万的动力学。反过来,给定一张白噪声,我们沿着水分子轨迹倒溯源头,就得到一张人脸图片。这就是扩散生成模型的原理(diffusion model)。当然,也可以直接用最有传输理论求解隐空间到自身的同胚,将数据分布变成高斯分布,这需要求解蒙日-安培方程。由此可见,数据分布的所有信息都由传输映射所包含,而传输映射被一个深度网络来表达。

图2. Sora用扩散模型从白噪声时空令牌生成数据时空令牌。(openai.com)
如图2所示,Sora在隐空间将数据令牌的概率分布通过扩散过程(郎之万动力系统-每个令牌上逐渐添加噪声)传输变换成高斯分布,再通过传输变换的逆变换将隐空间中的白噪声令牌变成隐数据令牌。
大语言模型的加持
Sora结合了大语言模型ChatGPT,这极大地提升了系统的性能。首先,Soar的训练样本是(文本,视频)对,有些视频对应的标题过于简短,字幕缺少,Sora采用了Dall-E的重新标题技术。
Sora的训练集包含一些优质的样本,(高度描述性字幕,短视频),由此训练了短视频数据流形(包括时空令牌流形),每个流形用其字幕(标题)来标识。对于缺乏标题或者字幕含混的劣质短视频,Sora将其编码到隐空间,在隐空间中寻找临近优质视频的隐特征向量,然后将优质视频的字幕(标题)拷贝给劣质视频。用这种方法,Sora可以为所有的训练视频数据添加高度描述性的字幕,从而提高了训练集的质量,进一步提升系统性能。
同时大语言模型可以将用户输入的提示进行扩充,变得更加精准,更加具有描述性,从而使得生成视频与用户需求更好契合。这使得Sora如虎添翼。但是Soar依然存在着很多缺陷,我们可以通过如下例子进行分析。
相关性与因果律的矛盾
ChatGPT将语句分解成令牌,然后用Transformer学习在上下文中令牌间连接的概率分布。与此类似,Sora将视频分解成时空令牌,然后学习上下文中令牌间连接的概率分布,并且依据这一概率分布由白噪声生成令牌,连接令牌,解码成短视频。每个令牌表达图像或者视频中的一个局部区域,不同局部区域间的拼接成为问题的关键。Sora相对独立地学习每个令牌,将令牌间的空间关系用训练集中体现的概率来表达,从而无法精准表达令牌间时空的因果关系。

视频1. Sora生成的老奶奶吹生日蜡烛视频。(openai.com)
如视频1所示,在Sora生成的视频中,每一帧都异常逼真,但是当老奶奶吹了生日蜡烛的时候,蜡烛的火苗纹丝不动。如果我们将视野缩小到每一个令牌的区域,我们看到美轮美奂的真实画面,令牌之间的衔接也非常平滑自然,但是当相距较远的令牌之间有因果联系的时候,即吹出的空气影响火苗的跳动时,两个令牌之间的物理因果没有体现出来。这意味着Transformer用以表达令牌之间的统计相关性,无法精确表达物理因果律。虽然transformer可以在一定程度上操纵自然语言,但自然语言无法准确表达物理定律,而物理定律目前只有偏微分方程才能精密表达。这反应了基于概率的世界模型的某种局限性。
局部合理与整体荒谬的矛盾
目前Sora相邻令牌间的拼接做得很合理,但是整体拼接的视频却可能出现各种悖谬。这意味着局部拼接与整体拓展之间的鸿沟。

视频2. Sora生成的“幽灵椅子”视频。(openai.com)
我们观察“幽灵椅子”视频,如果我们将视野限制在屏幕中间的一个局部区域,则视频非常合理。仔细检测不同令牌区间直接的连接,也非常连续光滑。但是整个椅子如鬼魅般悬空,这与日常经验相悖。这种“局部合理,整体荒谬”的生成视频,意味着Transformer学会了Token间局部的连接概率,但是缺乏时空上下文的大范围整体观念。在这个视频中,整体观念来自于物理中的重力场,虽然局部看不出来,但是整体上无时不在。

视频3. Sora 生成的四足蚂蚁。(openai.com)
再如Sora生成的“四足蚂蚁”的视频,蚂蚁的动作栩栩如生,宛如行云流水。局部上非常流畅自然,令人不禁联想或许在某个星球上存在这种四足蚂蚁。但是整体上,地球的自然界并没有四足蚂蚁。这里局部的合理无法保证整体的合理,这里的全局观念来自于生物学的事实。

视频4. Sora 生成的南辕北辙跑步机。(openai.com)
再如Soar生成的“南辕北辙跑步机”视频,如果我们观察每一个局部区域,看到的视频都是合理的,视频令牌间的连接也是自然的,但是整体视频却是荒谬的,跑步机与跑步者的方向相反。这个视频的全局观与来自于人体工程学的事实相悖。
这些例子表明,目前的Transformer虽然可以学习局部的上下文,但无法学习更加全局的上下文,这里的全局可能是物理中的重力场,也可以是人体工程学,或者生物中的物种分类。这种全局观点,恰是朱松纯教授提出的AI世界中的暗物质思想。虽然每个训练样本视频都隐含地表达了全局的观念,但是令牌化的过程却割裂了全局的观念,有限地保留了临近令牌间的连接概率,从而导致局部合理,整体荒谬的结果。
现代整体微分几何非常重视整体和局部的矛盾,为此发明了多种理论工具。比如,我们可以在拓扑流形的局部构造光滑标架场,但是无法将其全局推广,全局推广的障碍就是纤维丛的示性类。复流形上,我们可以局部构造亚纯函数,但是整体上无法将局部的函数拼接成整体的亚纯函数,这种局部推广到整体的差异用层的上同调理论来精确刻画。很多物理理论都表示成特定纤维丛的示性类理论,例如拓扑绝缘体理论。这种局部容易构造,整体推广出现实质性困难的数学理论,实际上是人类深层次探索自然的智慧结晶。这种整体的拓扑、几何观点目前还没有推广到AI领域,如果Transformer能够自行学会这种上下文中的整体障碍,那么AI将会更加有效地探索自然界。
临界状态的缺失
自然界的绝大多数物理过程都是稳恒态与临界态的交替变化。在稳恒态中,系统参数缓慢变化,容易获取观察数据;在临界态中(灾变态),系统骤然突变,令人猝不及防,很难抓拍到观察数据。因此,临界态的数据样本非常稀少,几乎在训练集中零测度。由此,Sora系统学习到的数据流形,绝大多数都是由稳恒态的样本所构成。物理过程中的临界态样本多分布在数据流形的边界。因此,在生成过程中,Sora非常容易生成稳恒态的视频片段,但是往往跳过临界态。但是在人类认知中,最为关键的观察恰恰是概率几乎为零的临界态。

视频5. Sora 生成的果汁泼溅。(openai.com)
Sora生成的果汁泼溅视频中,有两个稳定状态,水杯直立的状态,和果汁已经泼溅出来的状态,但是最为关键的临界状态:果汁从杯中流洒出来的过程却没有生成出来。虽然只有短暂的几帧,但是对于人类感知整个过程却是非常重要。Sora无法生成关键临界态的图像可能有如下原因:
物理过程中的不同稳衡态样本生成数据流形的不同联通分支,临界态样本在稳恒态流形边界附近,在两个稳衡态流形边界之间。热力学扩散过程将流形的边界变得模糊,从而混淆了流形边界,生成了过程含混的视频。换言之,临近态对应着数据流形的边界,学习过程中应该保持边界情形,而不应产生模式混淆。
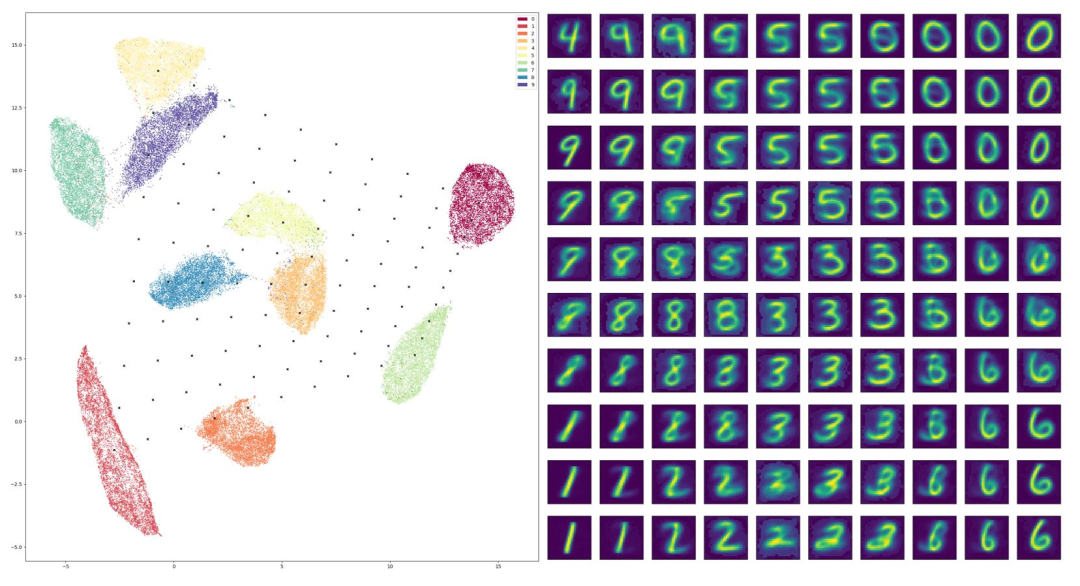
图3. 模式混淆(mode mixture)。
如图3所示,我们用MNIST训练了一个编码解码器,在隐空间画出了数据集的隐空间分布,10个手写体数字对应着10个团簇,每个团簇是一个模式(mode),即数据流形的一个联通分支。团簇的边界就是数据隐空间分布支集的边界。我们在隐空间生成了100个采样点,通过解码生成100个手写体数字图像。如果采样点落在某个团簇内部,则其生成的图像就非常清晰;如果采样点落在团簇边界的外部,则其生成的图像就非常模糊,往往是两个手写体数字的融合。因此,识别数据流形的边界对于识别临界状态非常重要。
Sora采用的目前最为热门的扩散模型,在计算传输映射的时候,必然会光滑化数据流形的边界,从而混淆不同的模式,直接跳过临界态图像的生成。因此视频看上去从一个状态突然跳跃到另外一个状态,中间最为关键的倾倒过程缺少,导致物理上的荒谬。

视频6. Sora 生成的小狗。(openai.com)
视频6显示了另外一种由于横跨流形边界而出错的情形。Sora生成小狗群在嬉笑斗闹,时而相互遮挡,时而散开。在视频的某一刹那,屏幕中的3只小狗突然变成4只小狗。我们如此解释:4只小狗的图片构成一个流形(或者连通分支),3只小狗的图片构成另一个分支,在4只小狗图片流形的边界处,有个临界事件:四只小狗彼此遮挡,图片中只能看到3只小狗。Sora的扩散模型没有识别出流形的边界,而是冲破这边界,在3只小狗图片的流形和4只小狗图片的流形间跨越。正确的做法应该是先识别流形的边界,然后在物理无法跨越的情形下(如3只边4只),在边界处返折回原来流形。
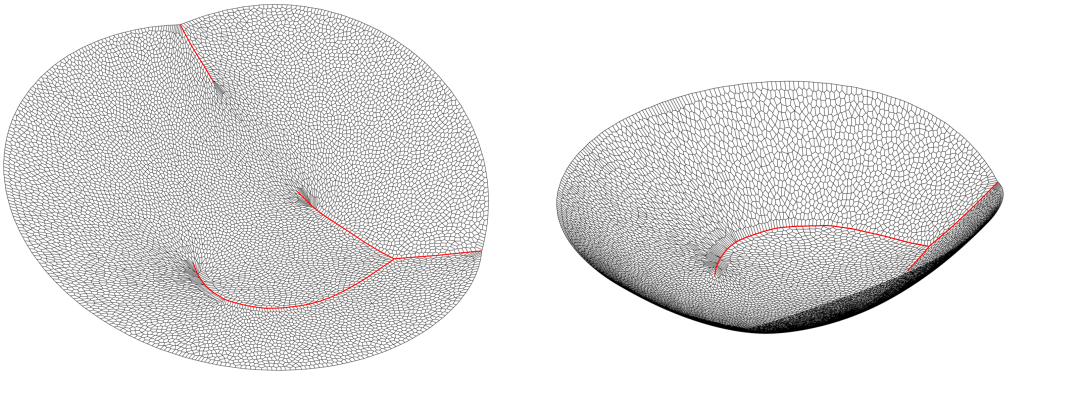
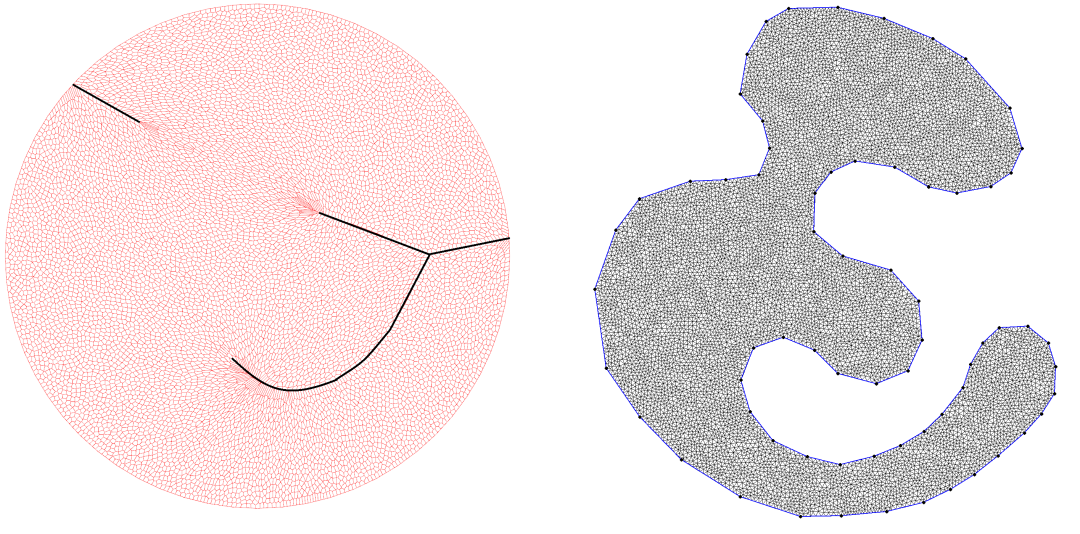
图4. 基于几何方法的最优传输映射可以精确检测到数据流形的边界,精确得到临界态。
扩散模型的弊端可以被基于几何方法的最优传输模型所克服。如图4所示,假设我们计算从圆盘内部的均匀分布到右侧海马形状区域内的均匀分布的最优传输映射,根据相应的Brenier定理,最优传输映射由某个凸势能函数的梯度映射给出。这一势能函数满足蒙日-安培方程,势能函数并非处处可导,其连续、非可导的集合投影到圆盘区域的奇异集合(黑色曲线),规则点映射到目标区域的规则点,奇异集合映射到目标区域的边界(每个奇异点同时映射到左右两个边界点)。当我们跨越奇异集合的时候,就意味着我们跨越了两个稳衡态,必然有临界(灾变)事件发生,即稳恒态被打破的物理事件。由此可见,精确找到传输映射的奇异集合,探测临界(灾变)状态,对于物理世界建模具有根本的重要性。
小结
由此可见,虽然Sora声称是“作为世界模拟的视频生成模型”,目前的技术路线无法正确模拟世界的物理规律。首先用概率统计的相关性无法精确表达物理定律的因果性,自然语言的上下文相关无法达到偏微分方程的精密程度;其次,虽然Transformer可以学习临近时空令牌间的连接概率,但是无法判断全局的合理性,整体的合理性需要更高层次的数学理论观点、或者更为隐蔽而深厚的自然科学和人文科学的背景,目前的Transformer无法真正悟出这些全局观点;另外,Sora忽略了物理过程中最为关键的临界(灾变)态,一方面因为临界态样本的稀缺,另一方面因为扩散模型将稳恒态数据流形的边界模糊化,消弭了临界态的存在,生成的视频出现了不同稳恒态之间的跳跃。而基于几何方法的最优传输理论框架,可以精确检测到稳恒态数据流形的边界,从而强调了临界态事件的生成,避免了不同稳恒态之间的横跳,更加接近物理的真实。
目前,由Sora为代表的数据驱动世界模拟模型,和由第一性原理建立起来的物理定律和偏微分方程的世界模拟模型开始进入了酣战状态。这或许是人类历史的伟大转折点。希望年轻的读者们都能踊跃跻身到时代的洪流之中,用自己的聪明才智推动科技与社会的发展!
文章来自于微信公众号 “始智AI wisemodel”,作者 “顾险峰”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
