# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Skills刚爆火,又有新的Agent范式来搅局了……
根本不用Skills,也不需要上GitHub翻项目、找工具。直接把需求丢给Agent,它能一边干活,一边给自己造装备。

是的,完全不需要人类伺候,也不用给AI师傅递板手、搬梯子。
工作中遇到啥需要用的装备,Agent能自己直接「进化」出来。
以Gemini 3 Pro为后端,在地狱级评测HLE(Humanity’s Last Exam)上一骑绝尘,仅次于GPT5.2-Pro智能体。
在几个高难评测集里,比官方未披露方法的含工具使用的结果,高了将近20分。
甚至还是One take,一口气跑出来的。
这是刚刚新发的一篇论文。
发现这篇论文,还是因为前几天刷到了个demo。
第一眼看上去,只是个很普通的交互场景:用户有个任务需求,丢给了Agent一串Prompt。
找找2023届毕业生中,哪些州的ACT考试参与率达到或超过50%,且平均综合分数在20分及以上。并给出这些州中,各州学生达到科学基准的比例。

然后Agent开始做分析、规划任务,挑选可能会用到的工具。
目前为止,一切都还很正常。
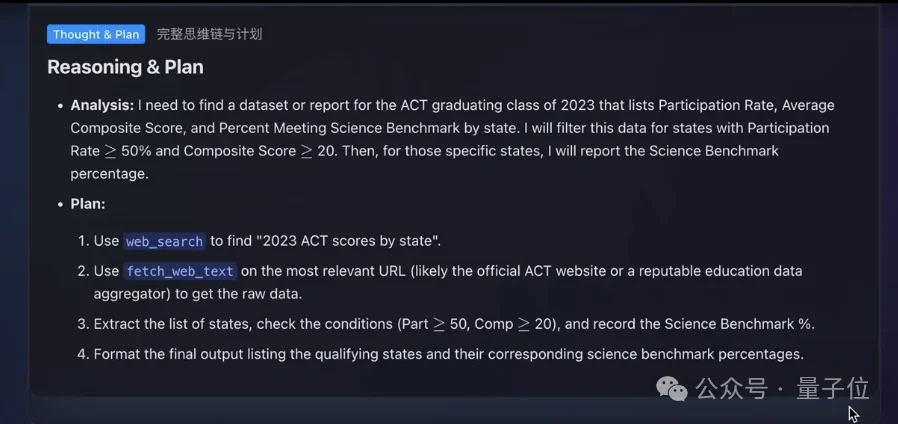
但说实话,感觉这个demo选的任务不是很好,太开放,不像是现有工具能一次解决的,估计得迭代对话不少次。
嚯!果然出问题了,工具不够用,干不下去。
诶,等一下……
它怎么开始自己造工具了??用错了还能修复?
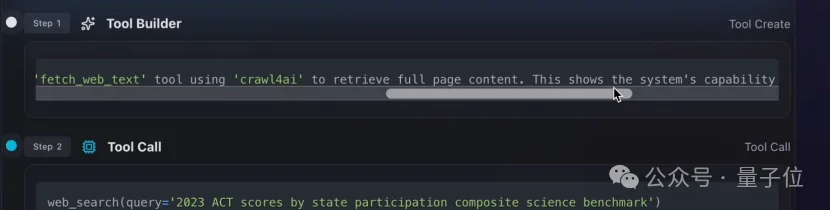
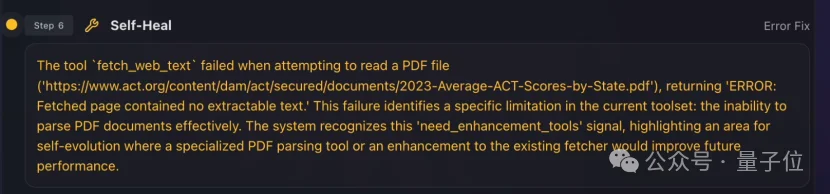
有点过于魔幻了啊。感觉就像动物园里,前一秒还躺着剥香蕉的猩猩,转头一看,一个跟头翻起来,开始钻木取火了。
我赶紧把论文翻出来,从头到尾扒了一遍,
不看没事,这一看,扒出来一堆更让人细思极恐的细节。
这家伙,居然靠这种方式,在只有一次答题机会的5个评测集中,造了128个工具!!
是的,白手起家,从0开始,一个一个捏到了128。
简直是天崩开局。
更惨的是,研究人员还一上来就把它扔进了地狱级的Benchmark—HLE(Humanity’s Last Exam)上,和基于GPT、Claude、Gemini的这些Agent怪物同台竞争。
不过,意料之外的事情发生了。
遇到「打」不过的题目,这家伙居然会自己造武器。
一路边打怪,边合成装备。
等把HLE两千多道题刷完,它已经悄悄攒了97把大宝剑。
这还没完,它又背着这九十多把大剑,前往了更多样的Benchmark试炼场——DeepSearchQA、FinSearch Comp、XBench。
还是故技重施,继续造工具,继续打怪升级。
一直刷到将近4000道题时,它突然停了,不造装备了。
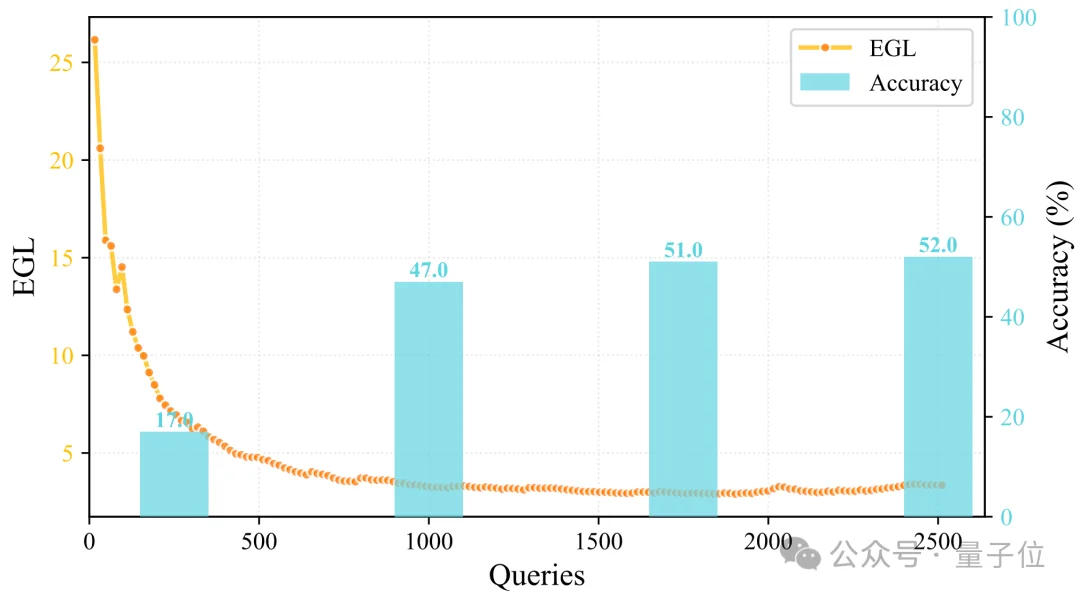
趋势上也有迹可循,下面这条曲线,前期增速很快,后面明显开始出现边际效应递减。
最终,工具数量稳定收敛在128个。
像是知道这些已经够用了一样。
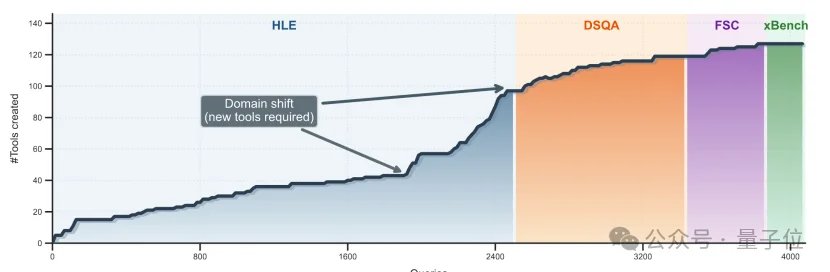
△按特定顺序的工具数量随处理的query数统计图
这点非常关键。说明前面的工具不是乱造的,而是真的具备可复用性。
所以在积累到128个工具时,Agent才会突然发现:旧工具已经可以覆盖绝大多数新任务,没必要继续扩张。
再看这张图更直观——两种策略下的Agent性能统计对比,ZS代表从零工具起手,WS代表前面说的按数据集顺序的知识迁移策略。
在WS策略下可以明显看到:旧工具越多,新工具越少。甚至在最后两个XBench阶段直接归零。
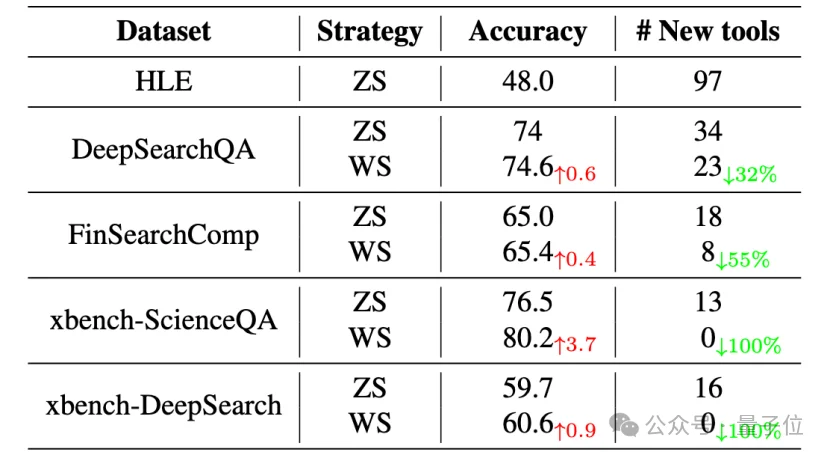
△不同策略下的Agent性能统计
下面这张图更有意思,这是这个Agent最爱用的50个工具。
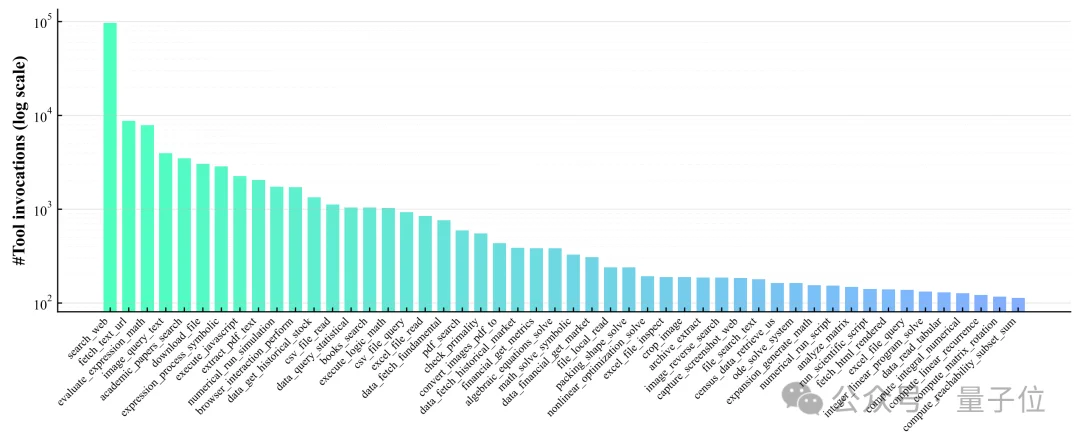
△工具使用频率统计图
排名第一的是「网页搜索」,断崖式第一。
后面跟着的也都很眼熟:内容获取、计算器、文件下载、学术论文搜索、PDF处理……
简直和人类的工作习惯一模一样啊,都是些通用的基础工具。而且复用率非常高,马太效应极其明显。
这么看来,它可能真不是为了造工具而造工具,而是真的像人一样,在工作过程中沉淀出了一套方法论,并且能在不同任务之间迁移。
实验结果也印证了这一点。
这只会自己造工具的Agent,在刚刚说的那五项Benchmark上,几乎全部一骑绝尘。
全方位碾压基于Gemini 3 Pro的Agent,在需要复杂检索与推理的任务中,甚至能高出十余个百分点。
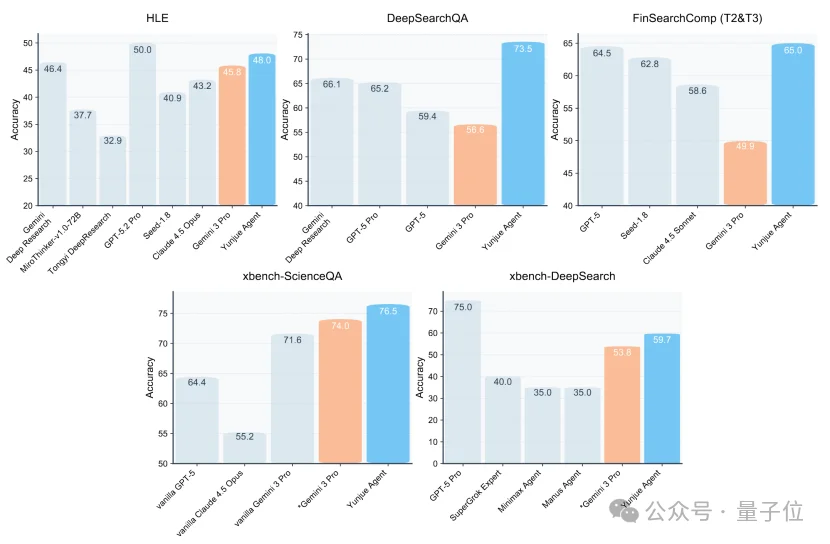
怎么做到的?
研究团队用了一种全新框架,叫原位自进化(In-situ Self-evolving Agent)。
第一眼没太看懂,但隐约感觉是个很性感的概念。
仔细研究了一下,发现行业其实一直在做自进化(Self-evolving Agent),但和原位自进化是两件事。
普通自进化,大都发生在训练阶段。高度依赖高质量外部监督信号,必须有专家提前选定进化领域,一个模型出题或标注好答案,再让新模型基于这些标注题目,开始最大化目标函数的进化。
这种模式呢,往往是基于一个长期目标做优化,可以从根本上重塑模型的大脑。
最常见的交付结果,就是现在各种模型厂商在做的:炼丹,发一款新模型上来炸场。
但缺点也很明显。
工程量巨大,反馈链路极长,因此只能在训练阶段完成。一旦上线,就没有「进化」这一说了。
而原位自进化,是一种发生在推理阶段的自进化。
不需要外部监督,也没有真值,光靠模型推理时的内部反馈,以及上一次交互中积累的经验,就能蒸馏出可复用的通用技能。
换句话说,只要上线,模型就能做到「边做边学」。
读到这里,肯定有读者要问了:
这难道就是AI行业一直苦苦追寻的明珠,自主学习吗?
只要训一次,后面就能在线上不断习得新能力,甚至抵达智能爆炸的奇点,实现ASI。
事实上,在2025年的云栖大会上,阿里CEO吴泳铭就曾指出:
ASI一定会到达,并且此前的一个关键节点,就是AI能够自进化。

但值得注意的是,行业在谈ASI的这种自进化时,更多还是指参数层面。
而原位自进化关注的是另外三件事:工作流、记忆、工具。
肯定不是那么「终极」的解决方案,但也更现实可行,马上就能开始干。
记得几周前参加大模型清华论剑时,也听到姚顺雨提过类似观点:
自主学习其实已经发生了,ChatGPT会根据对话过程不断拟合聊天风格,Claude的Agent代码库95%都是模型自己写的。
云玦科技的Agent,正是采用的这种现在就能落地的「原位自进化」,但他们走的路线比较特殊——工具优先。
团队认为,工作流路线,容易对少数任务过拟合,思路一旦固化,很难泛化;
而记忆路线,又绕不开LLM天然存在的幻觉问题,一旦Token上来,偏差会像雪球一样越滚越大。
从第一性原理出发,工具才是最符合直觉的进化载体。
首先,工具直接决定了Agent的能力边界。
人类基于地球资源制造的一切奇观,都是以新的生产工具为基础。AI也一样,积累再多上下文,没有铲子,也只能坐在金矿上发呆。
其次,工具执行天然自带高质量监督信号,不需要人类标注。
工作流好不好、记忆靠不靠谱,很主观;但工具能不能用,直接看代码报没报错就行。这就是所谓的二元判别信号(Binary Feedback)。
并且,通过形式化验证的代码,可以最大程度保证安全性,放心让Agent去执行API调用、数据库读写这些底层操作。
也不用担心会不会捡了芝麻丢西瓜。待工具基本收敛后,再去补齐工作流和记忆,依然来得及。
基于上述思考,团队以「工具优先」为理念,打造了一支可实现原位自进化的Agent军团。
由四个角色组成——
首先是管理者(Manager),负责统筹大局。
在收到用户需求后,它会分析任务、拆解目标,并与现有工具库对齐,看看有没有现成工具可用。
如果发现能力不足,管理者就会指挥工匠(Tool Developer),现场捏一个工具,并立刻在当前上下文中完成配置。
准备就绪后,执行者(Executor)会拿这些工具开始处理任务。
如果发现还是搞不定,它会暂停执行,向管理者汇报。
管理者收到信息后,重复前面的流程,继续补工具、补能力,直到任务能完整跑通为止。
任务完成后,交给整合者(Integrator),对执行历史和中间结果进行整合,生成最终回答。
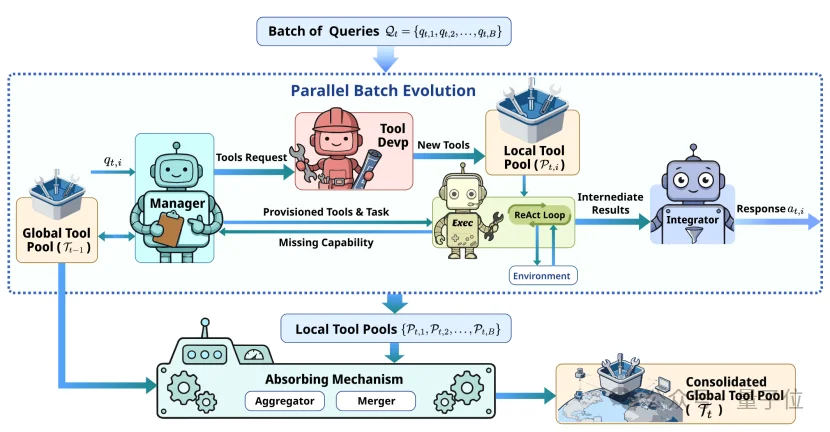
还有最后一步。
对话结束后,系统会对整个过程进行复盘,更新自己的工具库,并将迭代过程蒸馏、沉淀为可复用的方法论。
为了能更好地监测Agent的进化情况,团队还引入了个叫「测试时收敛」(Test-Time Convergence)的定量指标,作用和传统优化中的Training Loss类似,方便直观感受AI的学习情况。
听上去简直是个完美的解决方案,但在实际操作中遇到了问题。
如果严格按这条路线来,进化流程非常长,而且Agent必须一个任务跑完,才能进化一次,效率实在太低。
于是,团队引入了Parallel batch。
别一个一个跑了,直接把一批相似任务打包在一块,一起丢给Agent。
等着一整个Batch跑完后,Agent就能得到一个巨大的经验包,一次性喂饱知识库。
至此,一只能从零开始自我进化的Agent,诞生了。
无需任何事先训练,完全依靠工具的自进化来拓展能力,还在各种Benchmark上取得媲美SOTA的成绩。
最后再划个重点——
这套能媲美SOTA的自进化框架,还是开源的。包括上述实验的所有日志数据,评测脚本和结果,也都向社区开放。
又是一套可以直接落地部署的开源方案。
又是一项来自中国团队的研究。
这支团队来自云玦科技,这是前阿里巴巴集团副总裁彭超创办的AI公司,剑指可穿戴通用智能体。
而这篇论文的通讯作者,正是云玦科技的联合创始人兼CTO——齐炜祯。

齐炜祯曾任中关村人工智能研究院研究员、中关村学院大模型博士培养方向导师。现在虽然投身AI创业,但仍以兼职身份担任中关村学院的科研共建导师。
他是MTP架构(ProphetNet)的第一作者。这套多词元预测方法,在Meta研究机构FAIR 2024年的高影响力论文 Better & Faster Large Language Models via Multi-token Prediction中,齐炜祯第一作者研发的ProphetNet,被明确视为提出多Token预测架构的原创来源和定义出处。
工业界也在为这项研究背书,DeepSeek V3、Qwen-3-Next等多款主流大模型,当将其作为核心预训练方法。
量子位听说,DeepSeek今年年底即将发布的新架构论文,依然会引用这项工作,Qwen 3.5大概率也会继续沿用。
齐炜祯本科就读于中科大,最早学的是物理,后来转向计算机。
本科毕业后,他成为中科大与微软亚洲研究院的联培博士生,在这里积累了大量偏工程落地、以实际应用为导向的科研经验。
ProphetNet就是其中之一,除此之外,他还是Visual ChatGPT的核心作者。
该项目开源仅一周就收获了3万Star,开创性地定义了以LLM为中心的、调用多模态工具以完成复杂视觉任务的Agent范式。
在推理优化方面,他是业界首批提出KV Cache优化(EL-Attention)的学者,其核心思想与后来DeepSeek提出的MLA等高效推理部署算法高度一致。
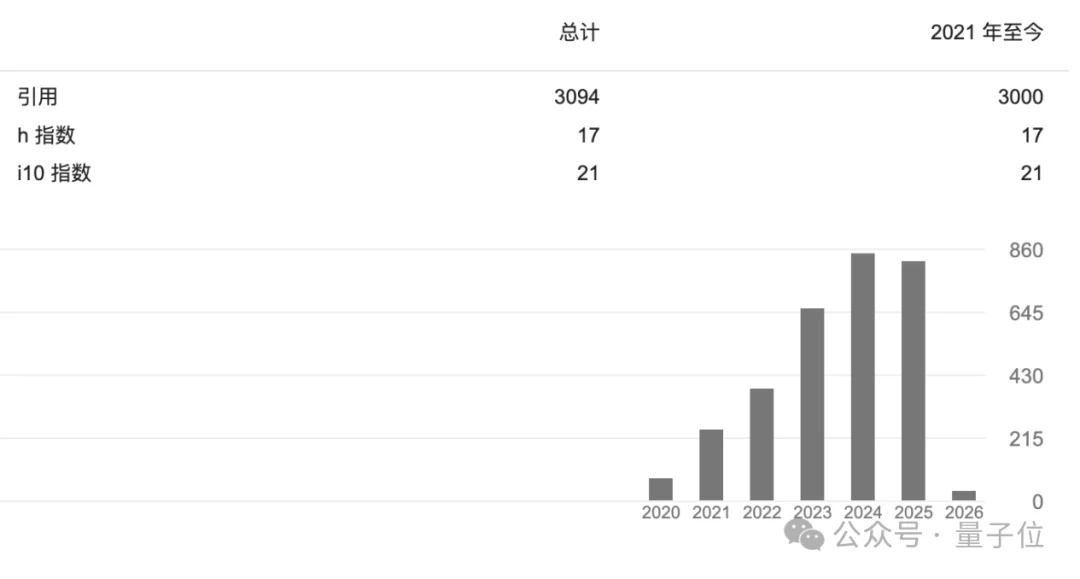
谷歌学术显示,齐炜祯的论文引用数已超过3000,h-index为17。
这篇论文的一作有两位,都是在云玦科技实习期间参与的这项工作。李昊天,哈工大博士生,杨释钧,中科大硕士生,他们在此之前都有多段大厂的实习经历。
还听说个有意思的事。
论文里的所有数据集和实验结果都是One take,完全靠同一个架构,一口气跑出来的。
这当然说明了这项工作的稳健性。但事实是,就算结果不好,也只能认栽。
团队只设定了15万元的研究经费,也就只够跑一次完整的推理实验。
也正因为如此,他们最开始也没法选择那些依赖大量人类标注、需要反复调参的方案。
只能赌一把。
赌原位自进化,赌「工具优先」,赌Agent能自己涌现出通用能力。
对于To C场景来说,AI始终面临着「开放性、可控性、经济性」的不可能三角。
LLM虽能处理开放性问题,但幻觉始终是硬伤,这在金融、医疗等场景下是不可容忍的。更别说,还要时刻面对防不胜防的提示词注入攻击。
成本同样是个大问题。完全依赖大参数模型的CoT推理,在To C服务动辄亿级日调用量的背景下,得烧出来个天文数字。
为了解决这个问题,垂直Agent应运而生。
提前把流程给设计好,工具也是固定的,以换取极低的成本和极高的安全性。
但代价也很明显:几乎没有自由度,Agent只能处理像「预定机票」这样的标准化需求。
可真实世界的人类需求,永远是高度发散的。就拿订机票这件看似没什么技术含量的事来说:
老板想订去巴黎的机票,但他护照快过期了,先帮我查一下签证加急流程,再决定要不要订。
这还只是一个例子,不同长尾场景下需要的新Context千差万别,不可能每个都能提前覆盖到。
而一旦用户意图超出了预设流程的边界,系统要么瘫痪,要么陷入死循环。
想要同时兼顾安全性、低成本,又能处理开放性需求,唯一的路,只能是让Agent在真实工作中学习。
这正是这篇论文给出的答案——「工具优先」的原位自进化。
能力边界的问题,可以交给工具集来解决;可控性,也能通过代码的执行反馈来约束。
甚至工作流也能自进化,通过模拟大量长尾场景,靠自我博弈与经验蒸馏,不断生成新的策略组合,探索各种工具组合路径。
而一旦某条路径被反复验证有效,它还会被「固化」为静态模板。遇到用户请求,Agent可以优先匹配这些模板,如果合适,直接填参数执行即可,无需再跑一遍昂贵的大模型推理。
关键是,这套能「越用越好用」的自进化架构,是开源的。
从工业角度来看,这个项目还和常规的AI开源项目不太一样。
事实上,今天虽然已经有很多开源模型,但开源阵营的整体声势,远没达到当年Linux在互联网时代那种级别。
没办法,Linux的飞轮太容易转起来了,只要代码不报错,通过审核就能合并上线。
所以,就算Linux最开始只有1000个社区成员,他们每天能贡献的代码量也是相当恐怖的;而Linux每一次进化,又会吸引更多开发者参与,这是典型的网络效应。
AI很难这么做,反馈路径太严格,对数据质量的要求极高。
这种时候,用户增长基本对模型能力没什么贡献,最多能反映出个宏观偏好,还会持续消耗昂贵的推理算力。
这也是为什么MiniMax CEO以及不少AI创业者都认为:AI产品的用户太多,未必是好事。
但这个问题,并非没有解法。
Skills的爆火已经证明——
开源始终是一座金矿,只是需要合适的工具去开采。
Skills是开始,原位自进化,走向Zero Skill,或许是下一步。
以DeepSeek为代表的一众开源模型,已经在全球范围内铺开了足够大的市场。
如果能用原位自进化,赋予其「越用越好用」的动态优势,再去和闭源模型正面掰手腕,甚至弯道超车——
不是不可能。
论文链接:
https://github.com/YunjueTech/Yunjue-Agent/blob/main/tech_report/YunjueAgentTechReport.pdf
GitHub链接:
https://github.com/YunjueTech/Yunjue-Agent/
文章来自于“量子位”,作者 “Jay”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
