# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型持续学习,又有新进展!
来自斯坦福、英伟达等研究机构的最新研究,针对解决开放的科学问题,提出全新思路——
Test-Time Training to Discover (TTT-Discover)。

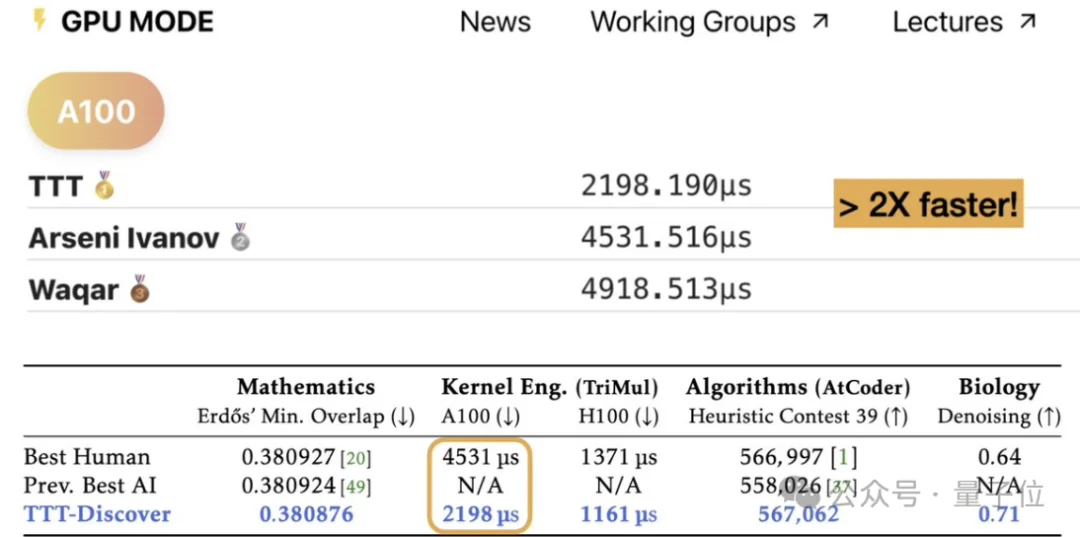
其基于开源模型gpt-oss-120b,在多个领域达到SOTA,优于人类专家与闭源前沿模型。
该方法不再沿用“测试时缩放”(Test-time Scaling)只通过Prompt调度冻结模型的做法。
而是在测试阶段,针对单个具体问题,引入强化学习(RL)对模型权重进行更新。
这种“测试时训练”使模型能够从该问题的失败尝试中实时获取经验,更新参数,实现模型能力的定向进化。
总的来说,这篇论文的核心思路是在测试时进行强化学习 (Reinforcement Learning at Test Time) ,并主要体现在两点:
1.学习目标(Learning Objective)
不同于传统强化学习侧重于提升所有任务的“平均奖励”以实现泛化,TTT-Discover采用熵目标函数(Entropic Objective)。
它通过调整权重倾向于奖励最高的动作(而非整条轨迹)。
这里的核心目标是产生一个极优解(One Great Solution),而非多个平庸解。
2.搜索程序(Search Subroutine)
引入受PUCT启发的重用机制,在缓冲区中维护历史尝试,优先扩展最具潜力(奖励最高)的状态,同时兼顾探索。
之所以这样设计是因为,对于科学发现来说,其目标是在特定问题中找到一个超越已有知识(训练数据)的最佳方案,而非在已知数据分布中寻找规律以实现泛化。
基于这一认识,就需要AI在具体的测试中不断尝试,在失败经验中学习,找到(获得)属于该问题的特定数据分布。
这里涉及到一个关键的逻辑:如果没有现成的训练数据,大模型该练什么?
TTT-Discover的实现方式是:模型通过不断生成动作并接收环境反馈,将成千上万次的尝试(包括大量的失败记录)存入缓冲区。
这些由模型自身搜索产生的尝试,构成了针对该特定问题的“私有数据集”。 这种“边实战边产出数据”的机制,彻底解决了分布外(OOD)问题无数据可练的困境。
当前,这类测试时学习的思路一般是通过测试时搜索 (Test-time Search),即通过提示 (Prompting) 一个冻结的大语言模型 (LLM) 进行多次尝试,类似于人类试图“盲猜”作业的解法。
但问题在于,这类方法虽能将尝试存入缓冲区并利用启发式规则生成新提示,但LLM本身权重并未更新,模型自身的能力并没有提升。
由此,为了实现持续学习,TTT-Discover基于测试时训练,更新权重,并针对单个问题,以找到最好的解决方案。
在具体的算法层面,为了产生更好的解,TTT-Discover搜索和学习过程均利用策略生成动作,并由问题描述诱导出环境转移函数。

在每一个步骤中,TTT-Discover循环执行以下操作:
然而,在具体实现中,传统的强化学习方法仍存在明显局限:
一方面,目标函数优化的是平均性能,对是否刷新最优解并不敏感,而科学发现关注的是最大值突破。
另一方面,每次尝试都从头开始,导致有效时界过短,限制了单次轨迹深度。
同时重用已有解可等价地延长时界,而发现类问题并不要求对固定初始状态分布保持鲁棒。
此外,在探索与利用的平衡中,策略既容易收敛到保守但稳妥的高奖励动作,又可能在状态重用时因朴素优先级排序而丧失多样性,抑制潜在突破。
针对以上问题,研究引入了熵目标函数(Entropic Objective)与PUCT启发的状态选择机制。
通过熵目标函数,训练目标被显式地引导去偏好奖励最大的动作,而非平均奖励最高的轨迹。
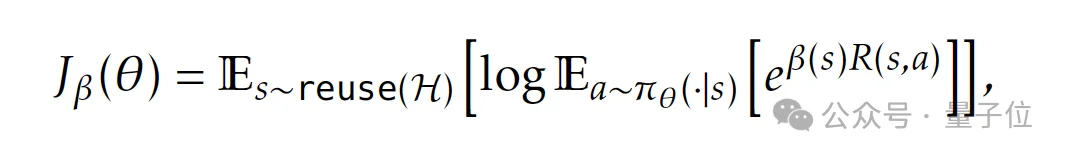
同时,研究还引入KL惩罚项对优势函数进行塑形,在强化高优势动作的同时,维持必要的探索能力。
在初始状态选择上,则采用受PUCT启发的评分函数:
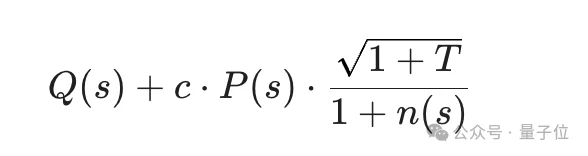
与以往工作使用平均值不同,这里在Q(s)中采用子节点的最大奖励:关注的是“从该状态出发能走到多好”,而不是平均表现。
先验项P(s)则编码了一条直觉——高奖励状态更可能孕育高奖励的后继状态。
由此,模型可以在利用(Exploitation)与探索(Exploration)之间建立更科学的平衡:通过高奖励导向快速逼近性能极限,同时利用探索奖励防止陷入局部最优。
具体来说,模型在每一步训练中都会经历一个“从已知到未知”的循环:
先从缓冲区中选出最有潜力的起点,生成并评估新的尝试,随后立即根据结果更新权重,使模型在随后的尝试中表现得更聪明。
在实验阶段,研究基于开源模型gpt-oss-120b,通过Tinker API运行,单个问题的测试成本约为数百美元。值得一提的是,正如开头展示的,在kernel内核编写任务中,TTT-Discover的速度比当前最佳人类实现快约2倍*。
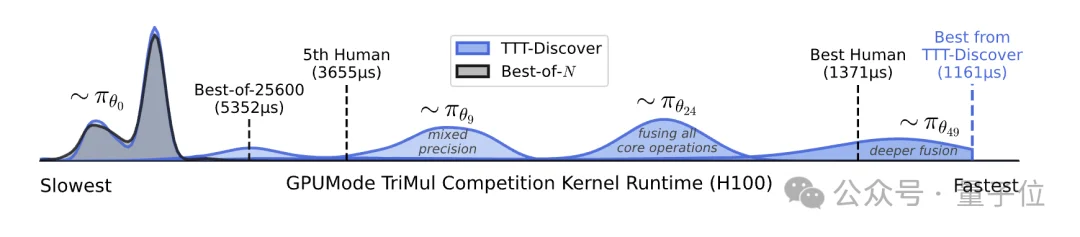
总体来看,TTT-Discover表明:在测试阶段引入针对性学习而非单纯依赖搜索,可以使中等规模的开源模型在解决复杂的分布外(OOD)科学问题时展现出卓越能力。
不过,需要指出的是,TTT-Discover目前主要适用于连续(可验证)奖励场景,后续工作还需将进一步拓展至稀疏奖励、二元奖励以及不可验证领域的问题。
论文的一作和共一是Mert Yuksekgonul和Daniel Koceja。
Mert Yuksekgonul目前在斯坦福大学计算机科学系攻读博士学位,导师为Carlos Guestrin与James Zou。

Daniel Koceja现于Stanford Artificial Intelligence Laboratory(SAIL) 担任全职研究员,接受Yu Sun的指导。

Yu Sun则为本论文的通讯作者,他现在为斯坦福大学博士后,同时担任英伟达研究员。
他博士毕业于UC Berkeley,师从Alexei Efros与Moritz Hardt。

Yu Sun的研究方向是持续学习(continual learning),重点关注测试时训练(test-time training),并自2019年起持续推进相关研究。

参考链接
[1]https://github.com/test-time-training/discover
[2]https://www.alphaxiv.org/abs/2601.16175
[3]https://openreview.net/profile?id=~Yu_Sun1
文章来自于“量子位”,作者 “henry”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
