# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从3000小时到整整20000小时。
真实世界数据里的Scaling Law,直接喂出了个最强VLA(Vision-Language-Action)基座模型!

这就是蚂蚁灵波今天开源的具身智能基座模型——LingBot-VLA。
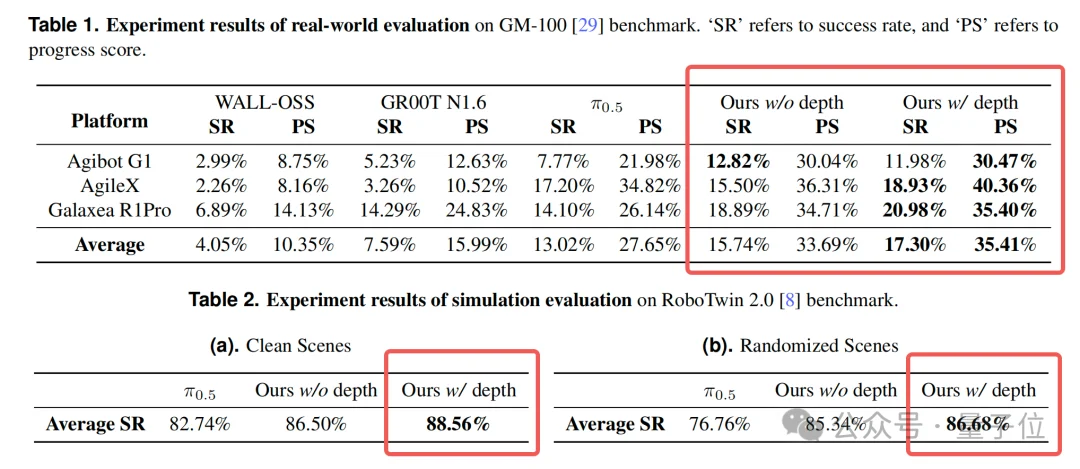
为什么说它是目前最强?先看数据。
从“20000小时”这个量上来看,LingBot-VLA已经解锁了迄今为止开源的最大规模真实机器人数据之一。
并且性能也是够打,在权威评测中也全面超越了此前公认最强Physical Intelligence的π0.5,以及英伟达GR00T N1.6等一众国际顶尖模型。
再看实际表现。
此前具身智能圈子一个很头疼的问题,就是一旦环境发生变化,VLA就不太好使了:
换了个机器人,Fail;
换了个摄像头,Fail;
换个桌子高度,Fail……
但在LingBot-VLA加持下的机器人,脑子一下子就变聪明了,学会了见招拆招。
例如面对复杂的收纳操作——把桌面物体放进包里并拉上拉链,机器人双手各司其职,动作一气呵成:

更复杂一点的餐具清洁整理——配合多种工具完成餐具清洗并归位,可以看到,机器人依旧是能精准拿捏各种各样的物体。
即便是像透明玻璃杯这样往往让机器人看不清的物体,它也能轻松hold住:

并且同样的任务,因为有了一个聪明的脑子,不论是放在AgileX、AgibotG1还是Galaxea三个不同的机器人身上,统统都能迎刃而解:

而纵观整项研究,除了数据性能和实际表现之外,更关键的一点是,LingBot-VLA还指明了一条通用具身智能发展路径:
从3000小时到20000小时,首次在真实世界场景中,系统性地验证了VLA模型性能会随着数据规模扩大而持续提升的Scaling Law。
并且是在20000小时之后,性能提升还没有失效的那种。
正如网友总结的那般:
更多真实数据 → 更高成功率 → 还未达到饱和。
一个大脑,多个身体,这就是规模化之道。
那么LingBot-VLA具体又是如何实现的?我们继续往下看。
在谈LingBot-VLA是怎么炼成的之前,我们还需要先了解一下机器人的困境。
之前像Physical Intelligence的π系列这样的顶尖VLA模型,一个很大的问题就是,它们预训练的数据大量依赖仿真环境。
仿真的好处是成本低、可并行,却与真实物理世界的质感存在难以弥合的鸿沟。
打个比方,一个机器人在仿真环境里能丝滑地叠衣服,但到了真实世界里可能连个衣角都抓不稳。
因此,蚂蚁灵波团队的选择是这样的:仿真的不好使,那就全部采用真实世界的机器人操作数据。
从2023年开始,他们联合星海图、松灵机器人等展开合作,在一间间真实的实验室里,通过遥控操作的方式,让机器人完成成千上万次抓取、放置、组装等动作。
数据规模从最初的3000小时,一路扩展到20000小时,全部源自物理世界。
并且这些数据并非来自单一机器人。
研究团队动用了9种不同品牌和构型的双臂机器人,包括AgileX、Agibot G1、Galaxea R1Pro/R1Lite、Realman Rs-02、Leju Kuavo 4 Pro、青龙机器人、ARX Lift2以及Bimanual Franka。

这意味着,模型从“小时候”开始就见识了不同机械臂的运动方式、不同摄像头的视角、不同夹爪的特性。
这种数据的异构性和丰富性,成了LingBot-VLA具有很强泛化能力的基础。
为了将这些海量视频数据转化为模型可学习的教材,团队还采用了一个巧妙的半自动标注流程:
最终,这20000小时、涵盖无数原子动作的多模态数据,构成了LingBot-VLA的养料。
除了海量真实数据之外,模型架构上的创新,也是LingBot-VLA的关键所在。
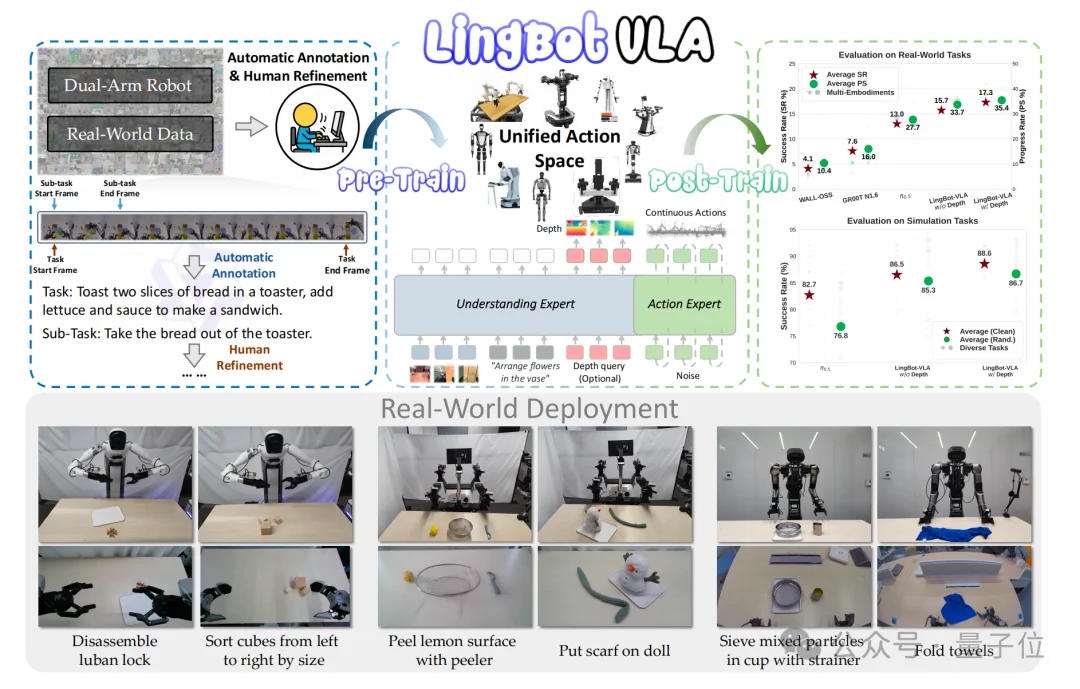
它采用了一种名为专家混合Transformer的架构,可以将其理解为为机器人设计了一套大脑与小脑协同工作的系统:
而且二者之间并非是各玩各的,它们通过一个共享的自注意力机制进行深度耦合,实现了在模型每一层的信息交互。
在动作生成技术上,LingBot-VLA还摒弃了传统的离散预测,引入了先进的流匹配模型。
简单来说,它不再预测“下一步关节应该转多少度”这样一个具体的点,而是学习整个动作变化的平滑流场。
这使得机器人产生的动作更加丝滑、连贯,更接近人类演示的自然度,对于需要精细控制的长序列任务至关重要。
除此之外,深度感知,是另一个技术上的点睛之笔。
为的就是让机器人不仅看得见,还能感知距离——引入了自研的LingBot-Depth深度估计模型提供的深度信息。
也就是昨天蚂蚁灵波开源的让机器人能看清透明和反光物体的新技术。
这种方法通过一种可学习的查询对齐技术,将深度信息蒸馏注入到VLA模型的视觉理解中。
相当于让机器人获得了对三维空间的直观感知能力,使其在面对“将芯片插入狭小卡槽”、“避免抓取时碰撞杯壁”等需要精确空间关系的任务时,表现大幅提升。
然而,要将20000小时高维度的视频和动作数据训练成一个模型,对算力是恐怖的消耗。
蚂蚁灵波团队对此的回应是:对训练基础设施进行系统级优化,打造了一个高性能开源代码库。
他们在分布式策略、算子级别和数据处理管道上进行了全方位革新:
效果是立竿见影的。
在8卡GPU的配置下,LingBot-VLA代码库实现了每秒每GPU 261个样本的吞吐量;与社区主流的OpenPI、StarVLA等框架相比,训练速度提升了1.5倍至2.8倍。
以往需要一个月完成的实验,现在可能只需一到两周就能搞定了。
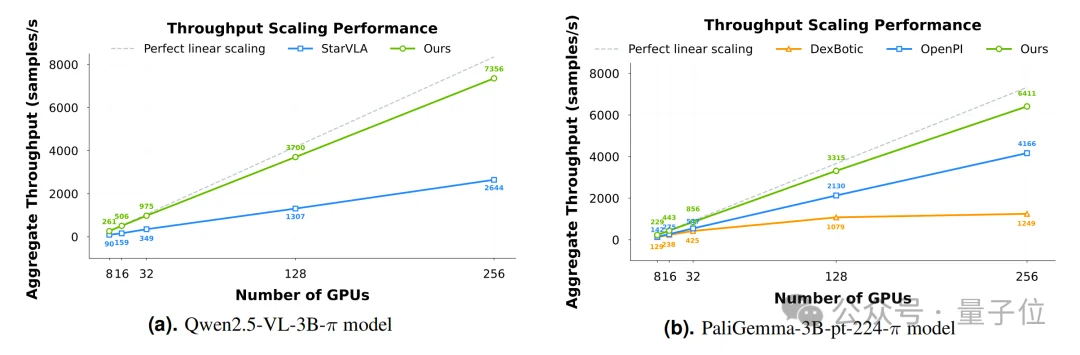
这不仅大大降低了科研创新的周期和成本,更重要的是,它让基于万小时级真实数据迭代VLA模型,从此变得可行。效率的提升,是解锁数据缩放定律的前提。
模型好不好,不能只在论文里说。
为此,蚂蚁灵波团队在权威的评测体系做了测试——GM-100基准。
这一测评集是由上海交通大学等机构联合研发,旨在为衡量机器人大脑(智能模型)与身体(物理执行)的协同能力,提供一个更系统、开放且可复现的评估基准。
它包含100个从易到难的精细操作任务,从简单的“抓取积木”,到复杂的“制作三明治”、“叠放衣服”。
评测在Agibot G1、AgileX和Galaxea R1Pro三种真实机器人平台上进行。
每个模型在每个任务上都要进行多轮测试,总计产生了22500次真实机器人测试录像。所有录像均已开源,确保了评测的完全可复现和透明。
在这场同台竞技中,LingBot-VLA迎来了三位重量级对手:π0.5、英伟达的GR00T N1.6,以及WALL-OSS。
所有模型都在相同的数据、相同的超参数下进行后训练,以确保公平比较。
在综合了任务成功率和进度得分两项核心指标后,LingBot-VLA(无深度版本)已在三项指标上全面领先WALL-OSS与GR00T N1.6。
而融合了深度信息的LingBot-VLA,则在三项指标上均显著超越了目前公认的强基准——π0.5。
例如,在AgileX平台上,LingBot-VLA(含深度)的平均任务成功率达到了18.93%,而π0.5为17.20%;在更具挑战性的Galaxea R1Pro平台上,优势同样明显(20.98% vs 14.10%)。

在仿真基准RoboTwin 2.0上,优势依旧明显。
在物体位置、背景、灯光高度随机化的复杂场景中,LingBot-VLA相比π0.5取得了近10个百分点的绝对成功率提升。

这证明其学到的能力是鲁棒的、可泛化的,而非对特定环境的过拟合。
更重要的是,研究团队通过控制预训练数据量(从3000小时到20000小时)进行的实验清晰表明:
随着真实世界数据量的增加,模型在下游各项任务上的性能呈现持续、稳定的提升,且尚未看到饱和迹象。
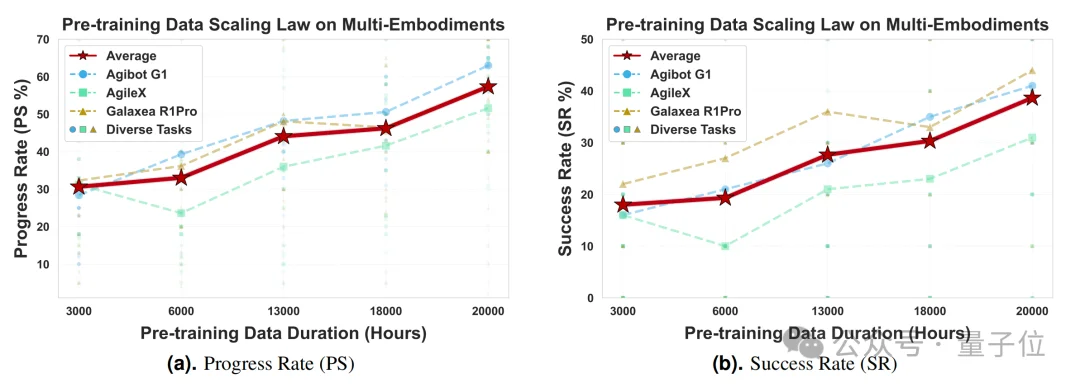
最后,来谈一谈蚂蚁灵波要做的事情。
与当前机器人行业存在的一个核心痛点息息相关,即场景碎片化与硬件非标化。
不同的机器人本体,关节构型、传感器配置、驱动方式千差万别。传统的解决方式是为每个场景、每种硬件定制开发算法,成本高、周期长、难以复制。
LingBot-VLA提供的是一种通用智能基座思路,也就是不做机器人的本体,但求做一个通用大脑:通过在海量异构真实数据上预训练,模型学会了跨越不同硬件平台的、本质性的操作逻辑和物理理解。
就像一个学会了“抓握”本质概念的人,无论给他筷子、夹子还是机械爪,他都能通过简单适应掌握使用方法。
LingBot-VLA展示的跨本体泛化能力正是如此。
模型在9种机器人数据上预训练后,在3种未见过的机器人平台上依然表现优异,证明了其能力并非绑定于特定硬件。
这为实现 “一次训练,多端部署” 的规模化落地愿景提供了坚实的技术基础。
为了降低行业的使用门槛,蚂蚁灵波团队不仅开源了模型和代码,还贡献了 “交钥匙”式的评估基准和高效后训练方案:
遥想2024年,π0的开源虽然引爆了全球VLA的研究热潮,但它主要基于仿真数据,在真机落地上存在局限。
而LingBot-VLA的价值在于,它首次提供了一个基于万小时级真机数据开源的全栈解决方案,推动行业从实验室演示迈向可规模化落地的新阶段。
如果说蚂蚁灵波LingBot-VLA是一个单点,那么它所影射的是蚂蚁集团在通往AGI探索的技术路径与行业愿景:
从基础大模型到多模态,再到如今的具身智能,蚂蚁的AGI拼图正在一块块补全。
这条路,注定是漫长且需要生态协作的。但当行业领先者开始体系化布局,并主动拆掉围墙,或许正如他们所期待的那样——那个属于通用人工智能的未来,会以更开放、更协作的方式,更早地到来。
或许在不久的将来,人们的生活就会变得像《连线》杂志所说的那样:
你的第一个机器人同事,大概率是个“中国人”。
项目主页:
https://technology.robbyant.com/lingbot-vla
GitHub:
https://github.com/robbyant/lingbot-vla
模型权重:
https://huggingface.co/robbyant/lingbot-vla
https://www.modelscope.cn/collections/Robbyant/LingBot-VLA
文章来自于“量子位”,作者 “金磊”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
