# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。
然而,本研究揭示了一个反直觉的现实:当前的任意顺序生成,反而通过「规避不确定性」收窄了模型的推理边界。
基于此,本文提出了一种回归极简的方法——JustGRPO。实验表明,在 RL 阶段让模型自回归生成,并直接用标准的 GRPO 进行训练,即可超越当前各类针对 dLLM 设计的 RL 算法表现。更重要的是,这种训练方式在提升推理表现的同时,并未牺牲 dLLM 引以为傲的并行解码能力。

为了探究「灵活性是否等同于推理潜力」,本文引入了 Pass@k 作为核心衡量指标。该指标量化了在 k 次采样中至少生成一个正确答案的概率,能够有效反映模型解空间的覆盖广度以及 RL 训练可激发的推理潜力上限(Yue et al., 2025)。
对比实验涵盖了两种主要的解码模式:
实验结果揭示了一个值得深思的趋势:虽然任意顺序在 k=1 时表现尚可,但随着采样次数 k 的增加,AR 顺序的 Pass@k 曲线不仅攀升速率更快,且最终达到的上限显著更高。这表明,在涉及复杂推理时,AR 顺序实际上可帮助模型覆盖更广阔的正确解空间。
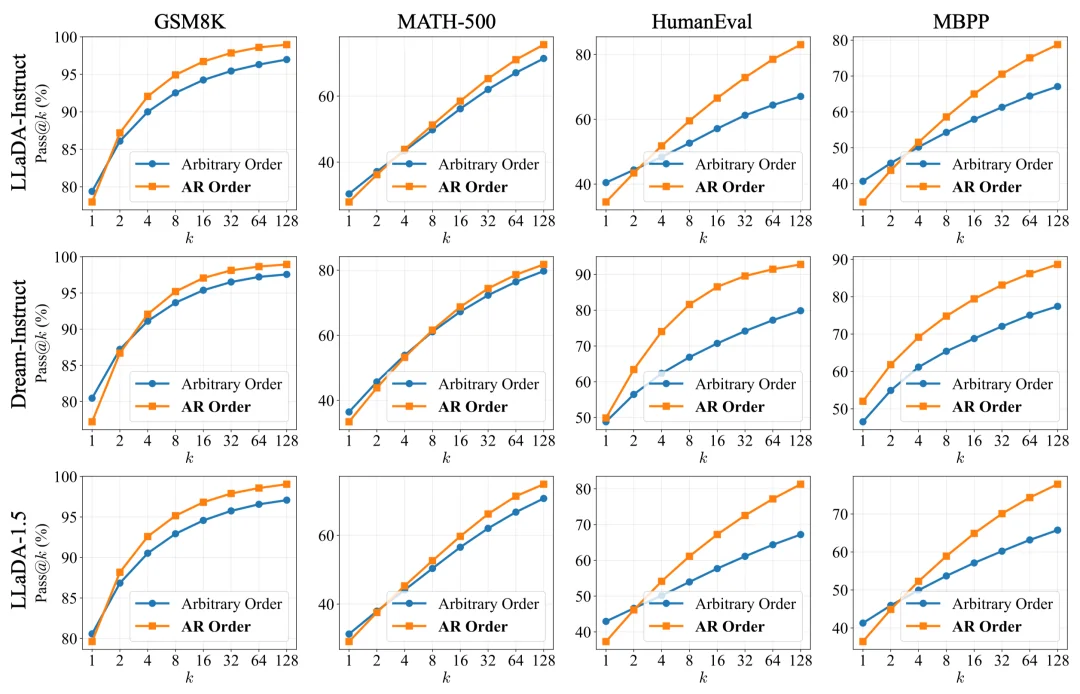
图:限制 dLLM 使用标准的 AR 顺序,反而比灵活的任意顺序拥有更高的推理上限。
为何看似受限的 AR 顺序反而更具潜力?这与两种顺序如何处理不确定性有关。
在自回归模式下,模型被迫直面第一个未知 Token;而在任意顺序模式下,模型则有跳过(bypass)当前不确定 Token、优先填充后续更确定的内容的「特权」。
统计显示,被频繁跳过的往往是诸如「Therefore」、「Thus」、「To」等逻辑衔接词(下图左):
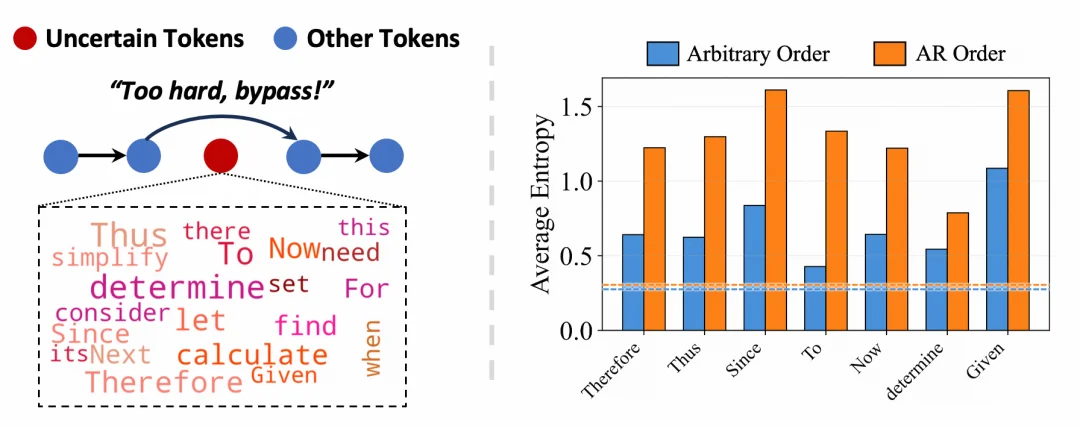
图左:任意顺序下,模型倾向于跳过不确定token而先填后续token,且这些被跳过的token往往是一些逻辑衔接词;图右:这些逻辑衔接词解码时的entropy显著低于自回归顺序(虚线代表average token entropy)。以上结果为LLaDA-Instruct在MATH-500数据集的结果。
已有工作(Wang et al., 2025)表明,这些逻辑衔接词往往起到通往不同推理路径的功能,且将这些词保持高熵状态对模型探索丰富的解空间至关重要。而在任意顺序下,这些衔接词被解码时的熵(Entropy)显著低于自回归顺序(上图右)。
我们将这种现象称为「熵降级」(Entropy Degradation)。形象地说,模型利用了任意顺序的灵活性进行了一种「局部贪婪优化」:它跳过了艰难的推理决策点,试图通过先生成后续上下文来「凑」出逻辑连接。虽然这在单次生成中可能有效,但却牺牲了对多样化推理路径的有效探索。
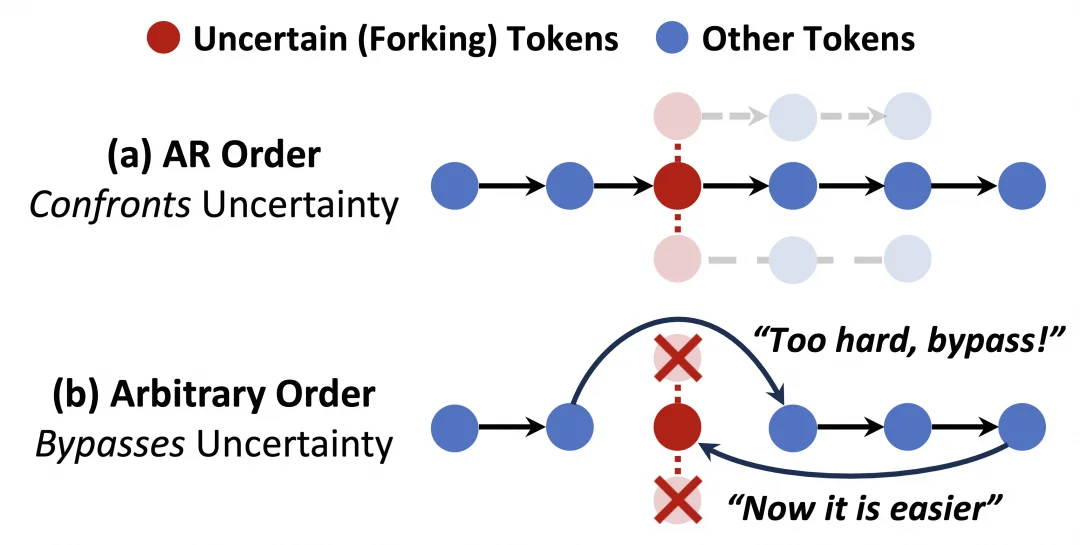
图:任意顺序生成倾向于绕过高熵的逻辑连接词,导致解空间过早坍缩。
既然「任意顺序」反而可能限制推理路径的探索,本文提出了一种回归极简的方法——JustGRPO。不同于现有 RL 算法,JustGRPO 不再试图用各种近似处理以显式保留任意顺序特性,而是选择了一条更为彻底的路径:
在 RL 训练阶段,直接摒弃对任意顺序的执念,强制扩散语言模型采用自回归(AR)顺序生成。这样不仅保持了更广阔的推理路径,同时也让我们得以直接复用成熟的 GRPO 算法进行优化。这种「生成轨迹的确定性」也自然使得强化学习时的信用分配(Credit Assignment)更加清晰,有助于模型更有效地学习鲁棒的联合分布。
值得一提的是:「训练时的约束」≠「推理时的退化」。
自回归的约束仅存在于训练阶段。它的目的是为了让模型更有效地进行 RL 阶段的探索与信用分配,模型本身的双向注意力机制并未被破坏。一旦训练完成,我们依然可以在推理阶段无损地应用并行解码,在享受 AR 训练带来的更优推理表现的同时,保留扩散模型引以为傲的生成速度。
在数学推理和代码生成这两类通用的推理任务上,JustGRPO 均有优秀的表现:
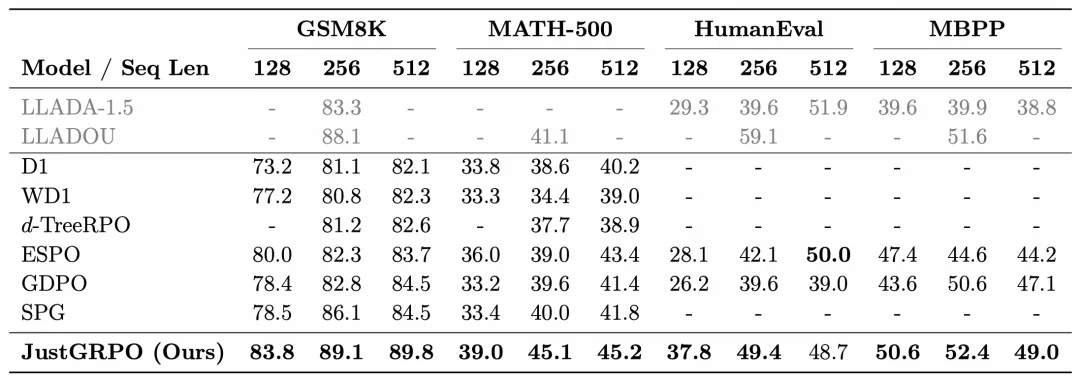
表:JustGRPO在多个基准测试中超越了现有的 dLLM 强化学习方法,基座模型:LLaDA-Instruct。注:LLaDA-1.5使用了大规模私有数据集训练、LLaDOU在训练中引入了额外模块,因此未列入对比。
一个可能的担忧是:用 AR 方式训练是否会让 dLLM 退化,失去其并行优势?实验结果恰恰相反。使用现成的 training-free 并行采样器(Ben-Hamu et al., 2025),JustGRPO 训练后的模型在并行解码下表现更佳。例如在 MBPP 数据集上,当每步并行解码 5 个 Token 时,JustGRPO 相比基座模型(LLaDA-Instruct)的准确率优势从单步的 10.6% 扩大到了 25.5%。
这表明训练后的模型学到了更鲁棒的联合分布,使其更能适应并行采样过程中的近似误差。
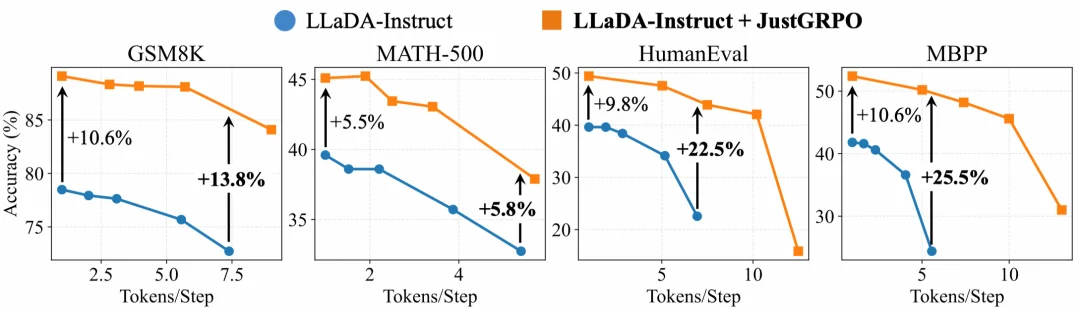
图:JustGRPO 训练后的模型在并行解码时表现出更好的速度-精度权衡。
这篇工作挑战了该领域的一个普遍假设,即「必须在 RL 中保留任意顺序灵活性」。事实证明,通过限制训练时的生成顺序,迫使模型直面逻辑分叉点的高不确定性,反而能更有效地激发 dLLMs 的推理潜能。
JustGRPO 以一种极简的方式,实现了推理能力的大幅提升,同时未牺牲扩散模型标志性的推理速度。也希望借此工作启发社区重新审视「任意顺序生成」在通用推理任务中的真实价值。
文章来自于微信公众号 “机器之心”,作者: “机器之心”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
