# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
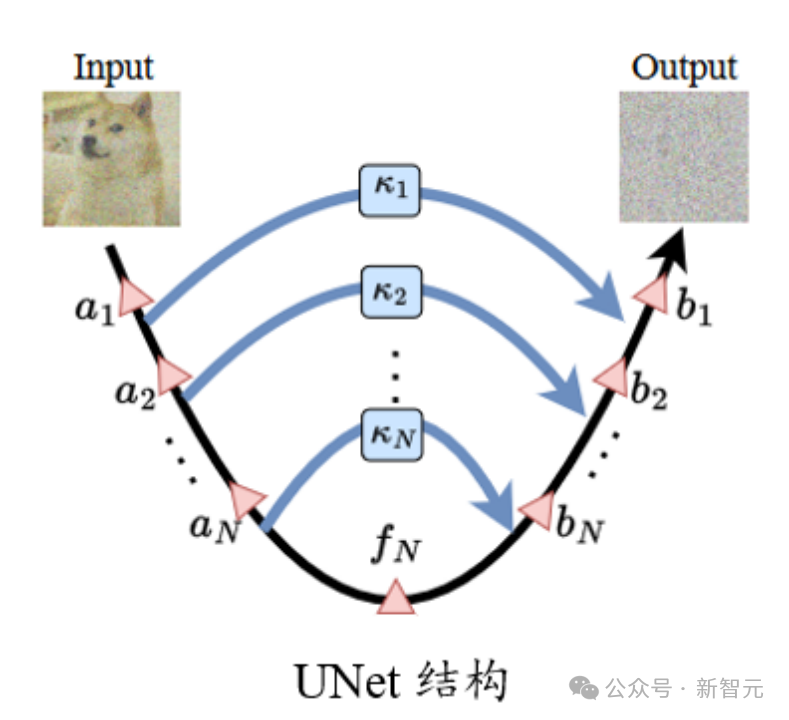
在标准的UNet结构中,long skip connection上的scaling系数![]() 一般为1。
一般为1。
然而,在一些著名的扩散模型工作中,比如Imagen, Score-based generative model,以及SR3等等,它们都设置了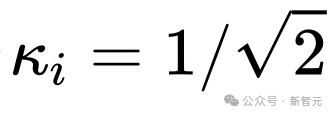 ,并发现这样的设置可以有效加速扩散模型的训练。
,并发现这样的设置可以有效加速扩散模型的训练。
首先,这种经验上的展示,让我们并搞不清楚到底这种设置发挥了什么作用?
另外,我们也不清楚是否只能设置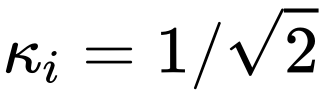 ,还是说可以使用其他的常数?
,还是说可以使用其他的常数?
不同位置的skip connection的「地位」一样吗,为什么使用一样的常数?
对此,作者有非常多的问号……

一般来说,和ResNet以及Transformer结构相比,UNet在实际使用中「深度」并不深,不太容易出现其他「深」神经网络结构常见的梯度消失等优化问题。
另外,由于UNet结构的特殊性,浅层的特征通过long skip connection与深层的位置相连接,从而进一步避免了梯度消失等问题。
那么反过来想,这样的结构如果稍不注意,会不会导致梯度过猛、参数(特征)由于更新导致震荡的问题?
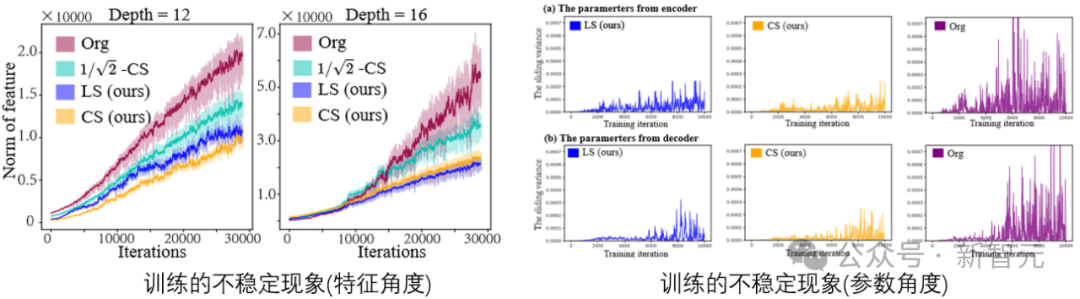
通过对扩散模型任务在训练过程中特征和参数的可视化,可以发现,确实存在不稳定现象。
参数(特征)的不稳定,影响了梯度,接着又反过来影响参数更新。最终这个过程对性能有较大的不良干扰的风险。因此需要想办法去控制这种不稳定性。
进一步的,对于扩散模型。UNet的输入是一个带噪图像,如果要求模型能从中准确预测出加入的噪声,这需要模型对输入有很强的抵御额外扰动的鲁棒性。

论文:https://arxiv.org/abs/2310.13545
代码:https://github.com/sail-sg/ScaleLong
研究人员发现上述这些问题,可以在Long skip connection上进行Scaling来进行统一地缓解。
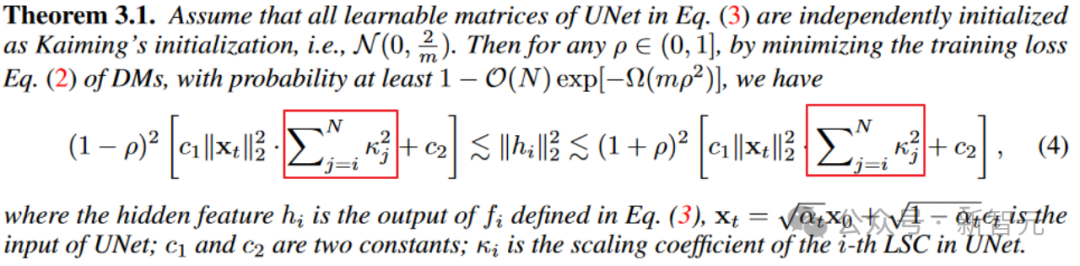
从定理3.1来看,中间层特征的震荡范围(上下界的宽度)正相关于scaling系数的平方和。适当的scaling系数有助于缓解特征不稳定。
不过需要注意的是,如果直接让scaling系数设置为0,确实最佳地缓解了震荡。(手动狗头)
但是UNet退化为无skip的情况的话,不稳定问题是解决了,但是表征能力也没了。这是模型稳定性和表征能力的trade-off。

类似地,从参数梯度的角度。定理3.3也揭示了scaling系数对梯度量级的控制。
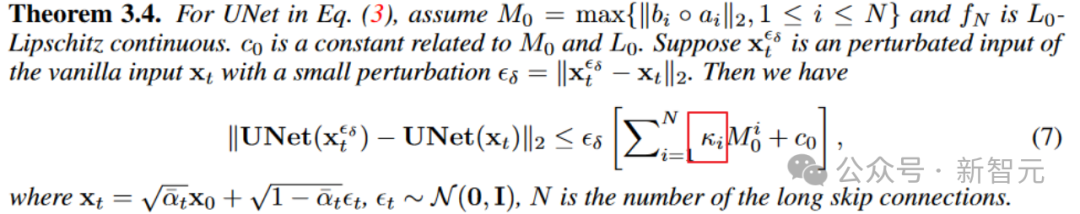
进一步地,定理3.4还揭示了long skip connection上的scaling还可以影响模型对输入扰动的鲁棒上界,提升扩散模型对输入扰动的稳定性。
通过上述的分析,我们清楚了Long skip connection上进行scaling对稳定模型训练的重要性,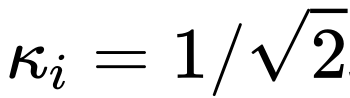 也适用于上述的分析。
也适用于上述的分析。
接下来,我们将分析怎么样的scaling可以有更好的性能,毕竟上述分析只能说明scaling有好处,但不能确定怎么样的scaling最好或者较好。
一种简单的方式是为long skip connection引入可学习的模块来自适应地调整scaling,这种方法称为Learnable Scaling (LS) Method。我们采用类似SENet的结构,即如下所示(此处考虑的是代码整理得非常好的U-ViT结构,赞!)
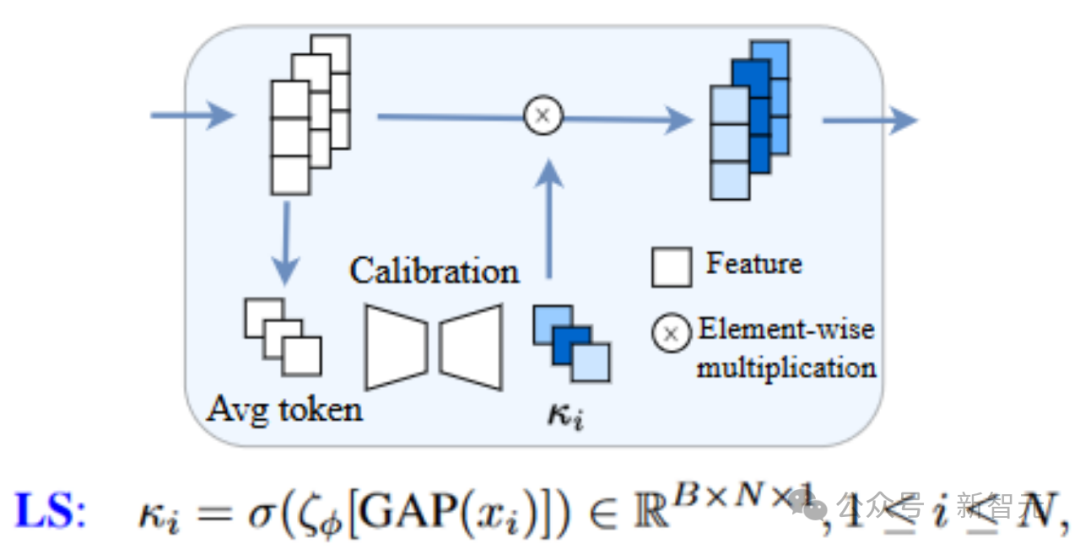
从本文的结果来看,LS确实可以有效地稳定扩散模型的训练!进一步地,我们尝试可视化LS中学习到的系数。
如下图所示,我们会发现这些系数呈现出一种指数下降的趋势(注意这里第一个long skip connection是指连接UNet首尾两端的connection),且第一个系数几乎接近于1,这个现象也很amazing!
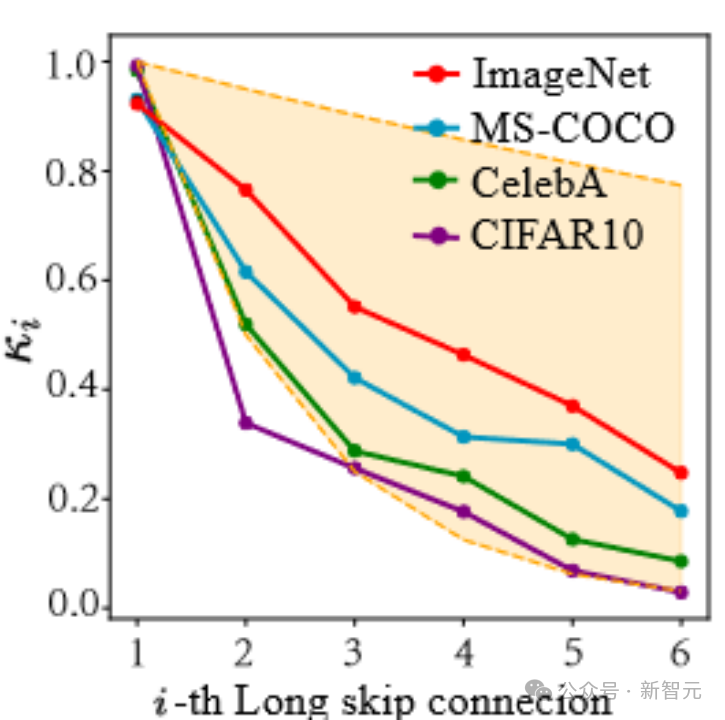
基于这一系列观察(更多的细节请查阅论文),我们进一步提出了Constant Scaling (CS) Method,即无需可学习参数的:
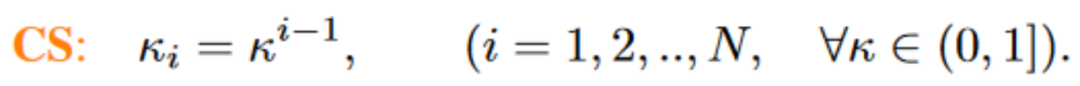
CS策略和最初的使用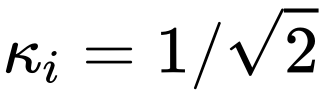 的scaling操作一样无需额外参数,从而几乎没有太多的额外计算消耗。
的scaling操作一样无需额外参数,从而几乎没有太多的额外计算消耗。
虽然CS在大多数时候没有LS在稳定训练上表现好,不过对于已有的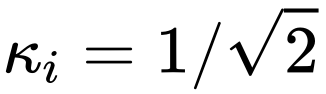 策略来说,还是值得一试。
策略来说,还是值得一试。
上述CS和LS的实现均非常简洁,仅仅需要若干行代码即可。针对各(hua)式(li)各(hu)样(shao)的UNet结构可能需要对齐一下特征维度。(手动狗头+1)
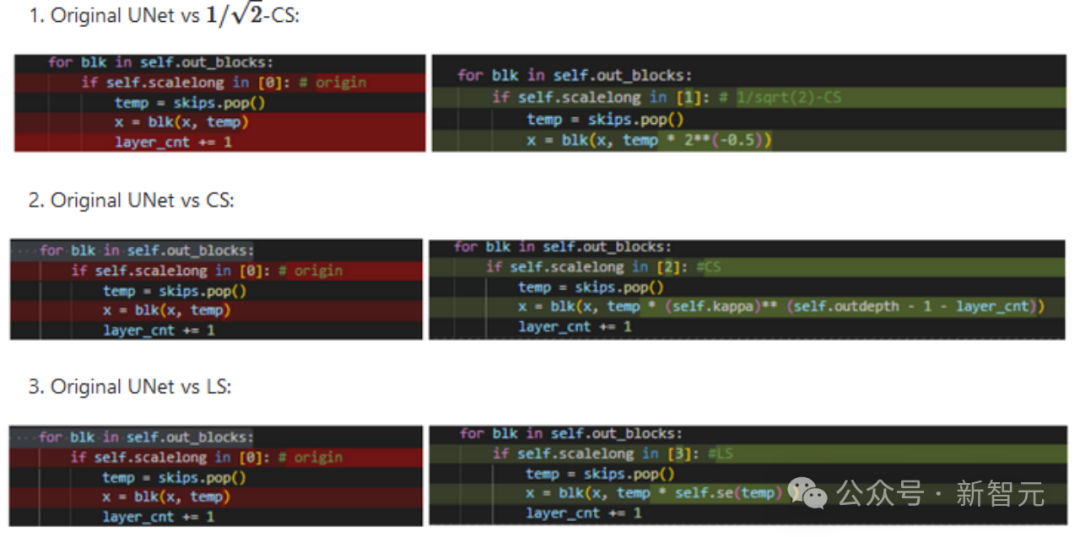
最近,一些后续工作,比如FreeU、SCEdit等工作也揭示了skip connection上scaling的重要性,欢迎大家试用和推广。
参考资料:
https://arxiv.org/abs/2310.13545
文章来自于微信公众号 “新智元”



