
硬氪首发 | AI家庭智能硬件公司MOVA LINCO获数千万元融资,首款产品今年上线海外
硬氪首发 | AI家庭智能硬件公司MOVA LINCO获数千万元融资,首款产品今年上线海外威联机器人科技(深圳)有限公司(以下简称“MOVA LINCO”)近日完成数千万元天使融资。融资资金将主要用于AI算法底层技术研发、完善产品量产体系,以及全球化渠道布局和家庭AI生态的持续建设。
来自主题: AI资讯
8579 点击 2026-07-14 11:39
 搜索
搜索
威联机器人科技(深圳)有限公司(以下简称“MOVA LINCO”)近日完成数千万元天使融资。融资资金将主要用于AI算法底层技术研发、完善产品量产体系,以及全球化渠道布局和家庭AI生态的持续建设。

根据人社部启动了互联网企业云端招聘月活动的最新数据,今年暑假,超5000家互联网企业集中释放了超过20万个就业岗位。京东、腾讯、字节跳动、美团等头部企业合计贡献超4.6万个岗位,覆盖AI算法、大模型应用、高性能计算等前沿方向。

大模型开始进入理论计算机科学最核心的问题之一:算法设计。
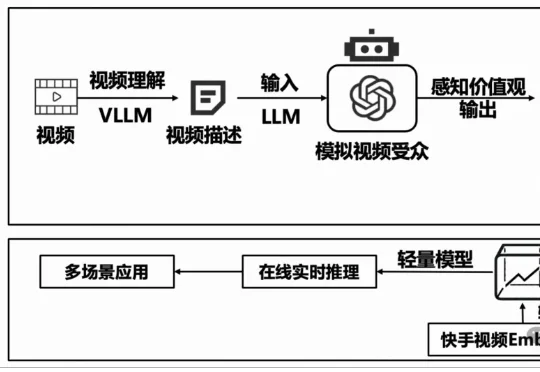
清华大学经济管理学院的陈柯均博士生、张佳音教授、徐心教授与快手消费策略算法部合作探索完成了一项联合实验:从视频传递的价值观的角度,去理解观看视频后用户的行为和心理变化。

刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。
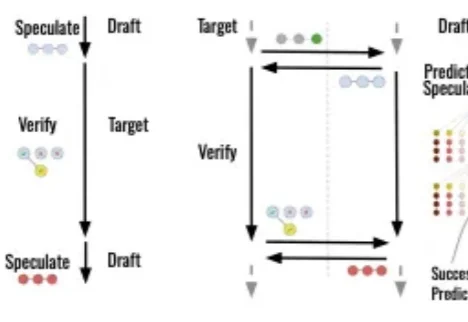
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。

所有用英伟达Blackwell B200的人,都在花冤枉钱??

作为一名 AI 领域的博士生,徐玉庄的经历比较特殊。本科毕业于国防科技大学,随后在部队工作了 5 年,接着在清华大学获得硕士学位,目前在哈尔滨工业大学读博。
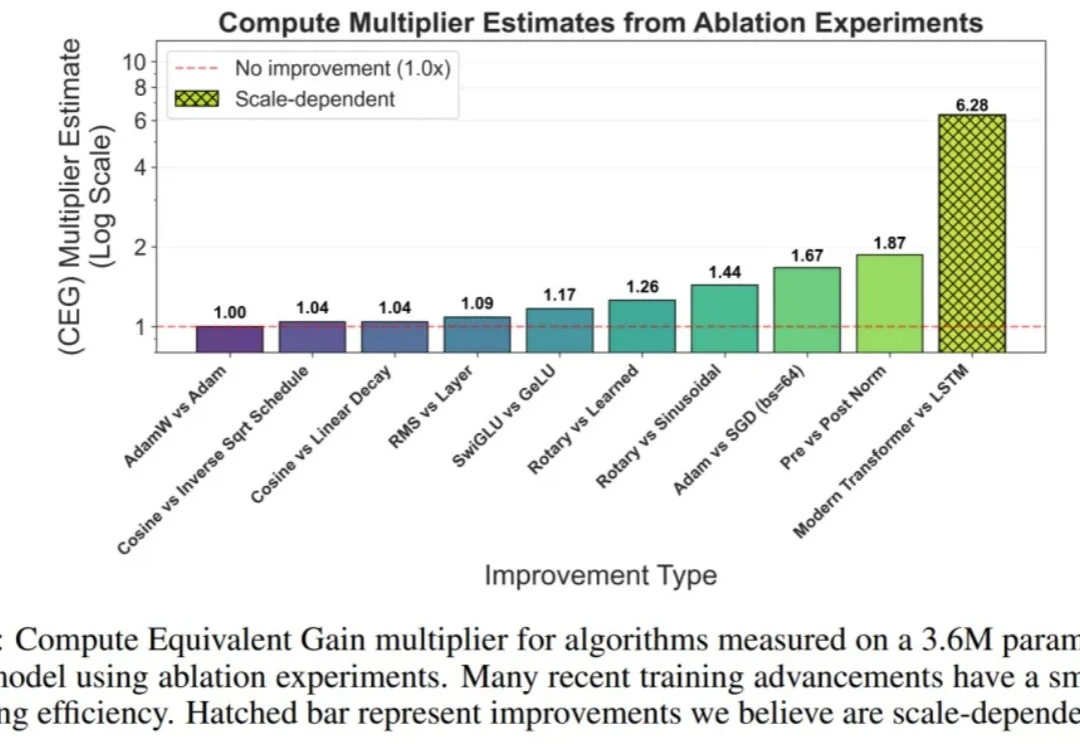
在过去十年中,AI 的进步主要由两股紧密相关的力量推动:迅速增长的计算预算,以及算法创新。