# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就是说,这几天还有哪档晚会节目是没有机器人现身的吗?
光是过年全家乐的央视除夕春晚,就有好几家具身智能公司的机器人宣布将亮相。
大厂小厂密集入局,资本追逐、媒体传播……具身机器人几乎成了继AI大模型后,下一轮科技叙事的中心。

具身机器人行业也确实处在一个非常有意思的坐标点上:
一边是繁花似锦的视觉盛宴,各种高难度动作频频刷屏,让大众因为“看见”而开始对具身智能的未来深信不疑。
另一边,充满了行业对“真实价值”的迫切期待,大家开始关心,这些机器人什么时候能真正走进工厂、处理琐碎,释放出实实在在的生产力。
这种期待,其实折射出具身智能正在经历的一场范式演进。
机器人要真正成为生产力,核心含金量终究要落在“自主性”上。目前的“人工辅助”或“单步遥操”在技术验证阶段是合理路径,也有助于积累数据与经验。
但如果一个机器人在执行过程中频繁停顿、修正缓慢,人类就不得不高频次介入,打断自动化流程。
如果每台机器人都需要一个人类兜底,那……(不讲不讲.gif)
只有一个人能同时监管十台甚至一百台、一千台机器人的时候,只有每台具身机器人都能在长时间任务中持续决策、持续修正、持续执行的时候,大家密切关注的具身智能才不是一种空谈。

所以不难理解为什么小米的第一个具身VLA大模型,抓住的是具身机器人间歇停顿这个问题。
在4.7B参数规模下,Xiaomi-Robotics-0实现80ms推理延迟、30Hz实时控制频率,在消费级显卡(4090)上就能跑得飞起。
在LIBERO、CALVIN、SimplerEnv等仿真+真实环境的主流基准上,Xiaomi-Robotics-0均刷新SOTA。
And,最重要的事情说三遍:
这模型是开源的,开源的,开源的。
为了实现上述效果,小米在Xiaomi-Robotics-0上做了三项核心技术创新,分别落在架构设计、预训练策略与后训练机制上。
三部分共同指向一个目标,让机器人既能理解复杂环境,又能连续、稳定、精准地执行动作。
首先是架构层面的大动刀。
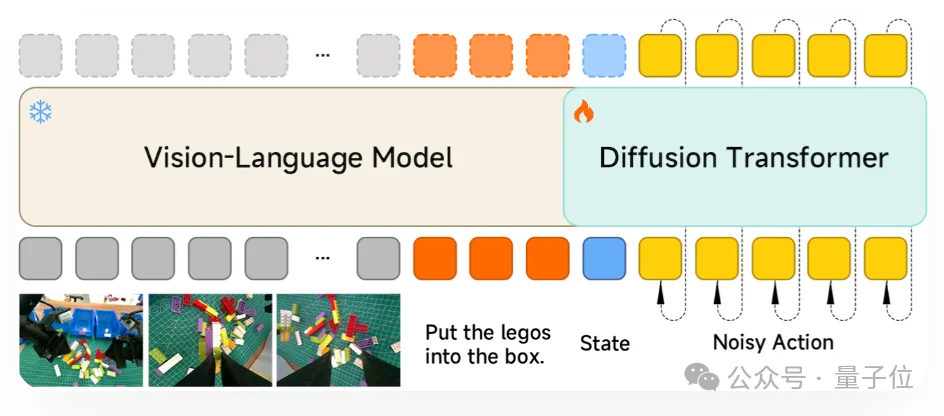
小米采用了目前主流的MoT(Mixture-of-Transformers)架构,但巧妙地将工作细分成了“大脑”和“小脑”。
大脑部分是VLM(视觉语言模型),负责全局的看、听、理解和决策;小脑部分则引入了只有16层的DiT(Diffusion Transformer)架构。
这个设计的高明之处在于,大脑输出的KV cache会传递给小脑,由小脑专门负责输出连续的动作块,这就改变了动作生成的粒度。
传统离散token方式会对连续动作进行离散化编码,精度容易被截断,轨迹会有细微不连续。
DiT配合流匹配技术,可以直接生成连续动作向量,动作更平滑灵巧。
同时,通过引入flow matching流匹配训练机制,Xiaomi-Robotics-0在训练阶段直接学习连续动作分布之间的概率流映射,推理阶段所需采样步数从传统扩散模型(如DDPM)通常需要的数十至数百步,压缩至五步。推理链路显著缩短,为低延迟实时控制提供了基础。
由于DiT与底层VLM同为Transformer结构,可以直接复用VLM的KV Cache,减少重复计算。
从整体架构看,大脑与小脑之间通过KV缓存松耦合连接,既保证理解能力,又控制了计算量。
这种松耦合的设计大幅降低了推理延迟,让机器人的动作不仅平滑灵巧,反应速度也达到了毫秒级——4.7B总参数的模型,推理延迟80ms,支持30Hz控制频率,在消费级显卡(RTX 4090)上可以实时丝滑运行。
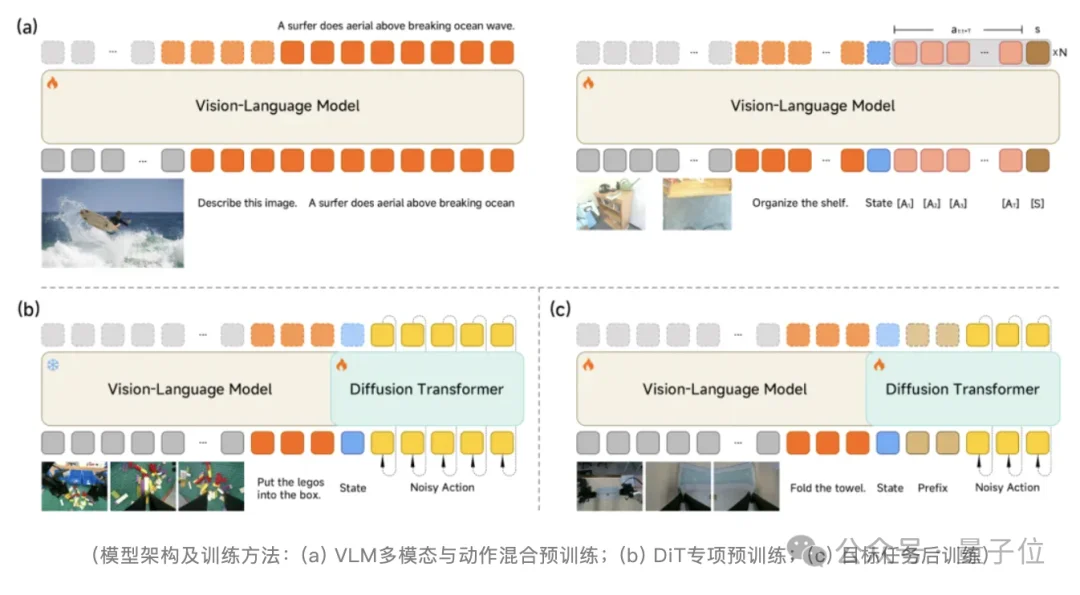
小米在Xiaomi-Robotics-0的第二项创新中,解决了一个具身模型长期存在的“顾此失彼”难题。
很多模型在学了大量的机器人动作数据后,原本强大的视觉理解能力(VL能力)会迅速退化,结果只会干活,脑子不会思考了。
为了确保模型不变傻,小米在预训练阶段采用了两阶段特训。
第一阶段,通过Choice Policy与跨平台机器人轨迹数据,让VLM在理解图像与指令的同时,能够粗粒度预测动作块。
这一步的核心是对齐视觉特征空间与动作空间,让模型在“看见什么”与“如何动”之间建立映射。
与此同时,在预训练中混合视觉语言数据,避免VLM遗忘原有的视觉推理能力,建立起一种“看到这个画面,就该有这种手感”的直觉。
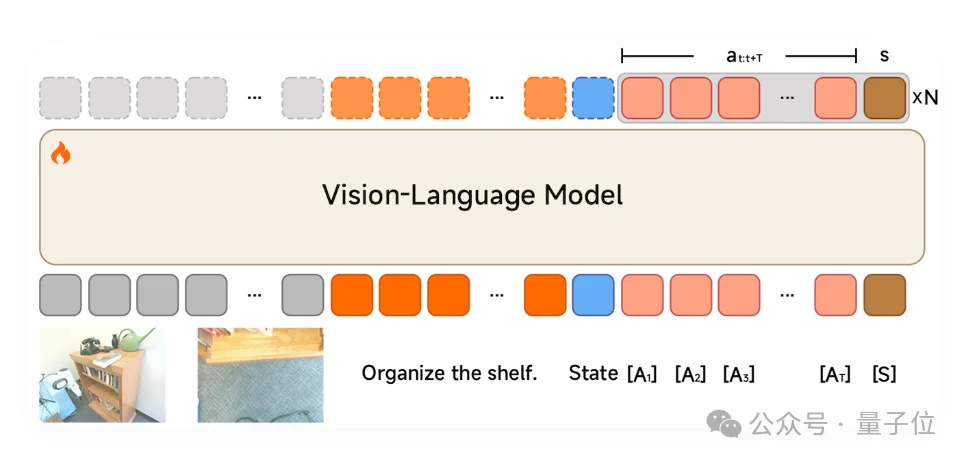
在进入第二阶段精细化动作训练时,小米会有意识地保护模型原有的多模态通识能力。
具体来说,在第二阶段冻结VLM,单独训练DiT进行流匹配精细化生成。此时VLM只负责提供稳定的多模态理解,小脑专注于连续动作轨迹的高精度生成。
这种分工确保模型在引入动作能力后依然保持强大的视觉语言能力,那么机器人在执行任务时就既能读懂复杂指令,又能规划连续动作。
对长程任务与人机交互来说,这种能力是居家旅行必备基础。
第三项创新则直指“动作跑偏”这个顽疾,Xiaomi-Robotics-0团队在后训练阶段引入了一种改良版异步方案。
传统异步执行会把上一次动作作为输入前缀,让动作衔接平滑,却容易产生动作惯性。模型过度依赖历史动作,忽视当前视觉信息,环境变化时修正滞后。
小米创新性地在后训练阶段引入了Λ-shape attention(Lambda形掩码机制)。
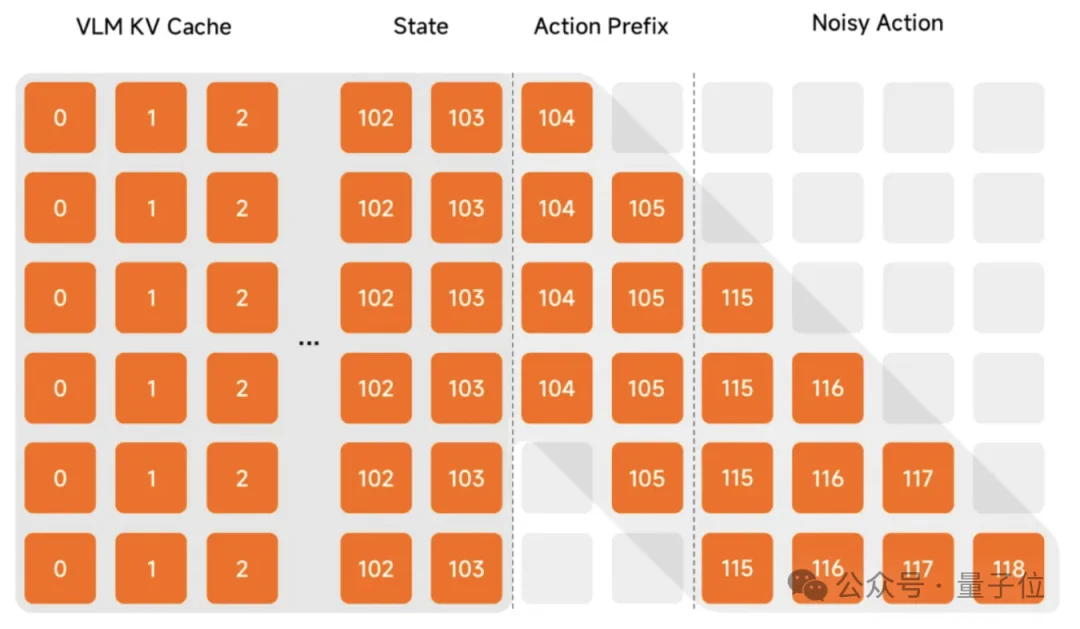
我们可以把它理解为给机器人装了一个带后视镜的瞄准镜:
动作块中紧邻前缀的动作会回看先前动作,确保前后衔接不抖动;远离前缀的部分则强迫眼睛死死盯着当下的视觉反馈,确保动作根据环境实时修正。
这种机制让模型在保证动作连续性的同时,强制重新审视环境,在真实任务中实现“连贯且可修正”,实现了既丝滑又精准的理想状态。
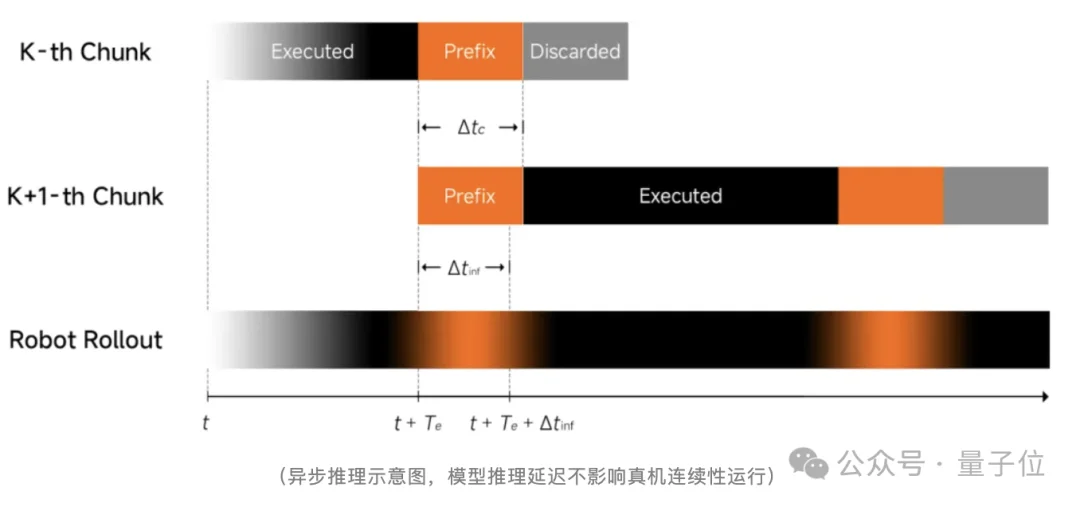
这套改良异步机制,让模型同时实现动作流畅+精度保持+吞吐领先。
在三重技术创新的加持下,Xiaomi-Robotics-0展现出了极为硬核的测评结果。
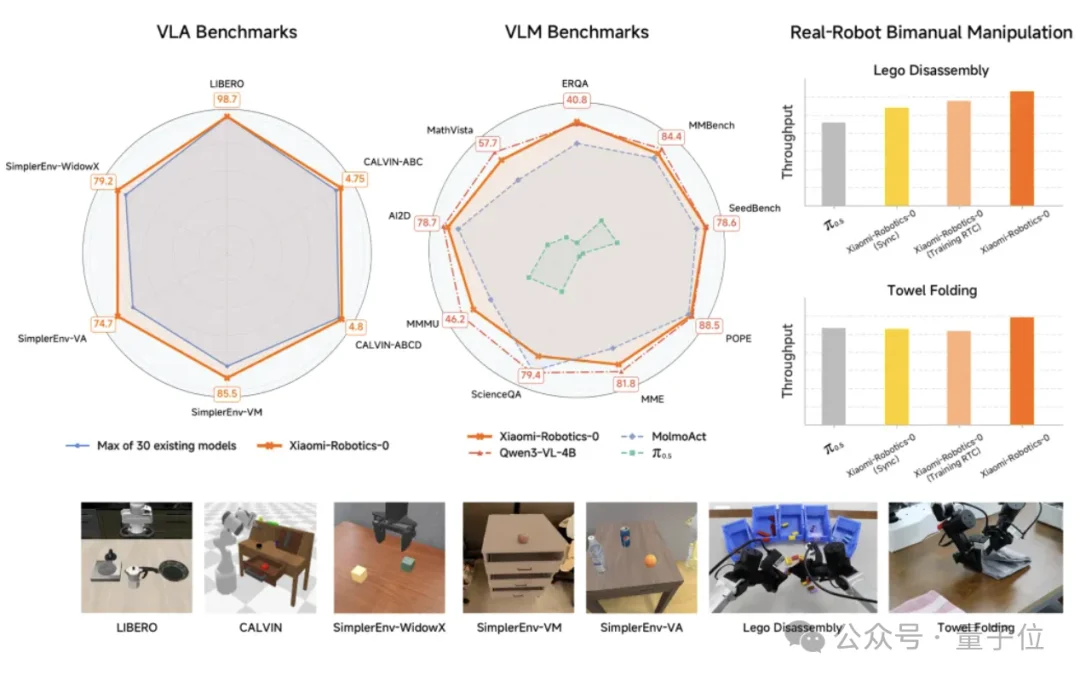
首先,我们来看Xiaomi-Robotics-0在VLA仿真benchmark上的成绩。
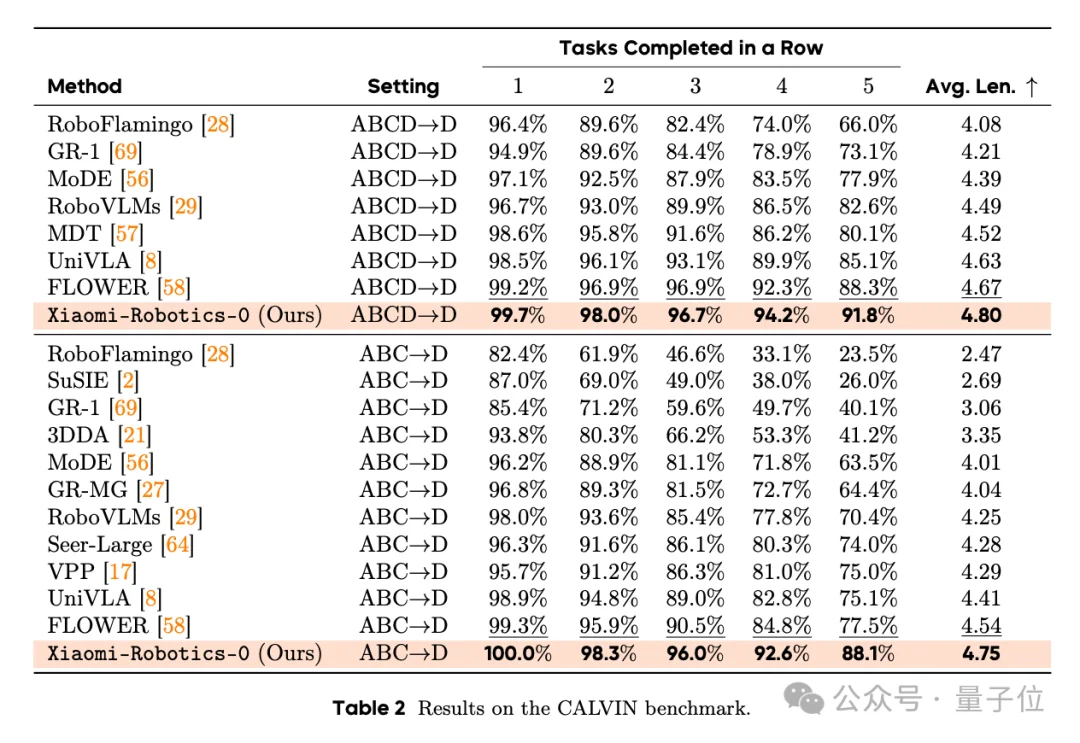
在具身智能最看重的VLA仿真benchmark中,小米几乎是全场横扫。
在LIBERO、CALVIN、SimplerEnv等六个仿真环境中,Xiaomi-Robotics-0全面超过现有的包括π0、π0.5、OpenVLA、RT-1、RT-2等头部模型在内的约30个模型。
(注:详见论文https://xiaomi-robotics-0.github.io/assets/paper.pdf)
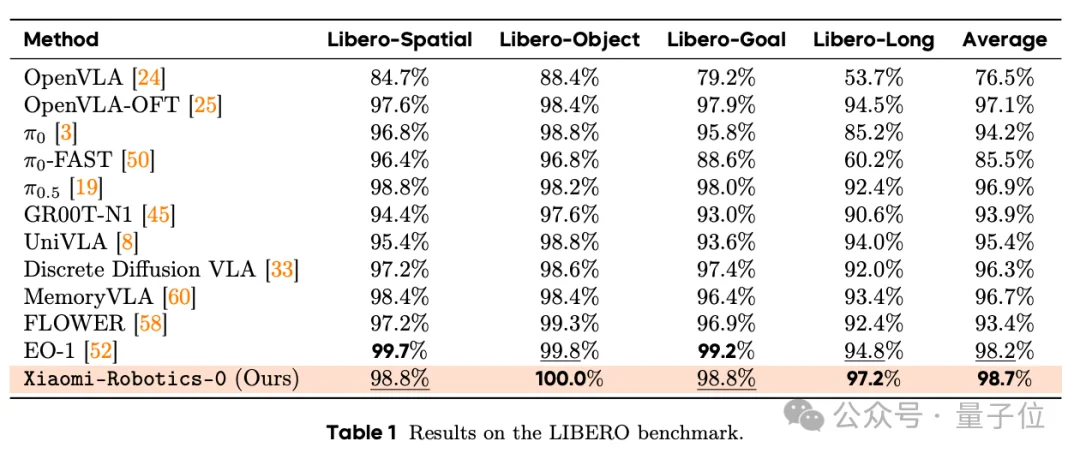
无论是考察多任务泛化能力的LIBERO,还是考察长程操作稳定性的CALVIN,Xiaomi-Robotics-0都刷新了纪录,其成功率超过了公认的开源标杆π0.5。
尤其是在Libero-Object任务上,Xiaomi-Robotics-0达到了100%成功率,并以98.7%的平均成绩位列Libero测试机前列。
接着来看Xiaomi-Robotics-0在MathVista、ScienceQA等针对视觉理解和数学推理的VLM benchmark中的表现。
在MMBench、MME、POPE、SeedBench、AI2D、M3MU、ScienceQA、MathVista、ERQA等九个测试集中,Xiaomi-Robotics-0的大多数指标都高于对比模型。
模型在引入动作能力后仍保持高分,这证明它没有通过牺牲理解能力来换取控制能力。

当然,对于具身智能来说,物理世界中的真实任务表现显然更具说服力。
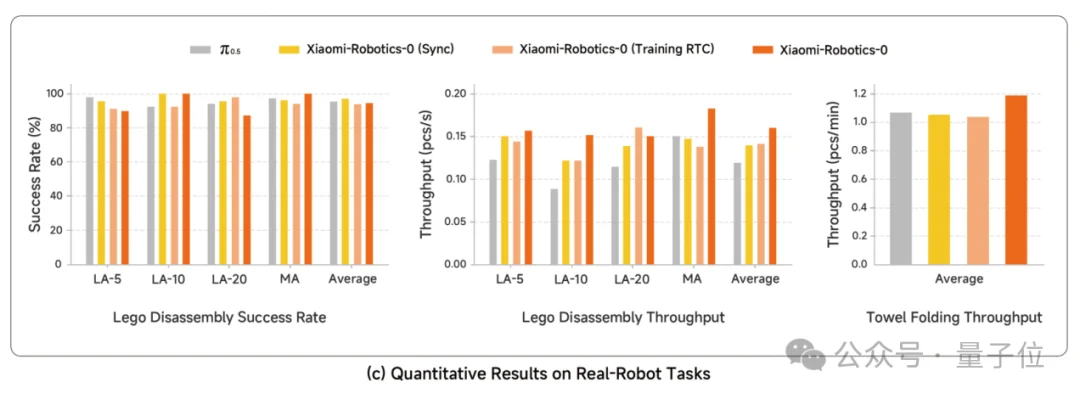
“叠毛巾”是现实世界需要,又对具身机器人有高要求的任务——机器人需要处理非结构化的软体。
Xiaomi-Robotics-0测试了6张不同毛巾,连续作业30分钟,均保持高成功率与高吞吐。

而“拆卸乐高”这种需要极致微操和高频反馈的任务,它需要先将乐高组件拆卸成积木块,再根据颜色将每个积木放入相应的存储箱中。
模型也展现出了极高的完成度:在MA与LA-10场景达到100%成功率,吞吐量领先约25%。

结合三类测试集的表现数据来看,Xiaomi-Robotics-0打通了仿真-视觉理解-真实机器人操作的闭环,已经是一个非常成熟的一体化VLA模型了。
综合来看,Xiaomi-Robotics-0在目前的具身智能模型梯队里,绝对是一个不折不扣的A+级选手。
由此引出一个一定要弄清楚的问题,即:
小米发力具身智能领域,到底是想做什么?
目前市面上的机器人落地,大约可以划分为两大派系。
一类是黑科技表演派。
它们主攻硬件能力,擅长翻跟头、跳舞,展示极高的动态平衡能力,动作复杂,视觉效果震撼,适合舞台与视频传播。
另一类则是务实进厂派。
强调工业落地,它们更关注稳定性、吞吐量与可部署性,以及重视对复杂环境的适应性。

结合小米近期的一系列动作——就在几天前,小米刚刚开源了触觉驱动的精细抓取微调模型TacRefineNet——我想,小米在具身技术方面的路线已经不难猜了。
TacRefineNet是一个纯触觉驱动的精细抓取微调模型,它依赖11×9压阻式触觉阵列,触点间距1.1mm,通过多模态融合,实现毫米级位姿微调。
它无需视觉、无需物体三维模型,Zero-shot就能部署于真实产线。

就目前小米公开的具身技术成果来看,Xiaomi-Robotics-0提供快速响应与连续控制,TacRefineNet提供末端精细调整。两者结合,构成“眼-脑-手”协同体系。
这直接切中工业场景中最难的非结构化环境作业难题。
进厂干活嘛,只有脑子干不了活不行,能做精细的事儿但不懂得怎么干活也不行。
所以,现在基本可以断定,小米在两大派系选择了走务实路线。
最后想强调一下,无论是TacRefineNet还是Xiaomi-Robotics-0,小米都选择了开源。
所有架构细节、算法方案都全盘托出。
从技术角度看,这次开源让行业看清了“低延迟+高智能”在消费级硬件上运行的可行路径,打破了“具身大模型必然面临思维卡顿”的思维定式。
从行业视角来看,这意味着广大的中小开发者不需要再从零开始烧钱去训练昂贵的基座模型。
大家完全可以站在小米这样的开源先行者的肩膀上,去开发各种细分的垂直应用。

具身机器人属于重资产、长周期赛道。
开源行为降低门槛,提升透明度,推动技术讨论从营销转向工程细节。而且在这个阶段开源高质量的基础模型,无疑是隐形承担了行业基础设施建设者的角色。
这不仅是企业行为,更是产业行为。
在机器人这样一个需要长期投入的领域,这种开放姿态释放出的信号十分明确。小米这一波,确实展现了科技大厂应有的担当。
技术主页:
https://xiaomi-robotics-0.github.io
GitHub:
https://github.com/XiaomiRobotics/Xiaomi-Robotics-0
抱抱脸模型权重:
https://huggingface.co/XiaomiRobotics
文章来自于“量子位”,作者 “衡宇”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
