# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“绝不是简单的抠图。”
ControlNet作者最新推出的一项研究受到了一波高度关注——
给一句prompt,用Stable Diffusion可以直接生成单个或多个透明图层(PNG)!
例如来一句:
头发凌乱的女性,在卧室里。
Woman with messy hair, in the bedroom.

可以看到,AI不仅生成了符合prompt的完整图像,就连背景和人物也能分开。
而且把人物PNG图像放大细看,发丝那叫一个根根分明。

再看一个例子:
燃烧的柴火,在一张桌子上,在乡下。
Burning firewood, on a table, in the countryside.

同样,放大“燃烧的火柴”的PNG,就连火焰周边的黑烟都能分离出来:

这就是ControlNet作者提出的新方法——LayerDiffusion,允许大规模预训练的潜在扩散模型(Latent Diffusion Model)生成透明图像。

值得再强调一遍的是,LayerDiffusion绝不是抠图那么简单,重点在于生成。
正如网友所说:
这是现在动画、视频制作最核心的工序之一。这一步能够过,可以说SD一致性就不再是问题了。
还有网友以为类似这样的工作并不难,只是“顺便加个alpha通道”的事,但令他意外的是:
结果这么久才有出来的。

那么LayerDiffusion到底是如何实现的呢?
LayerDiffusion的核心,是一种叫做潜在透明度(latent transparency)的方法。
简单来说,它可以允许在不破坏预训练潜在扩散模型(如Stable Diffusion)的潜在分布的前提下,为模型添加透明度。
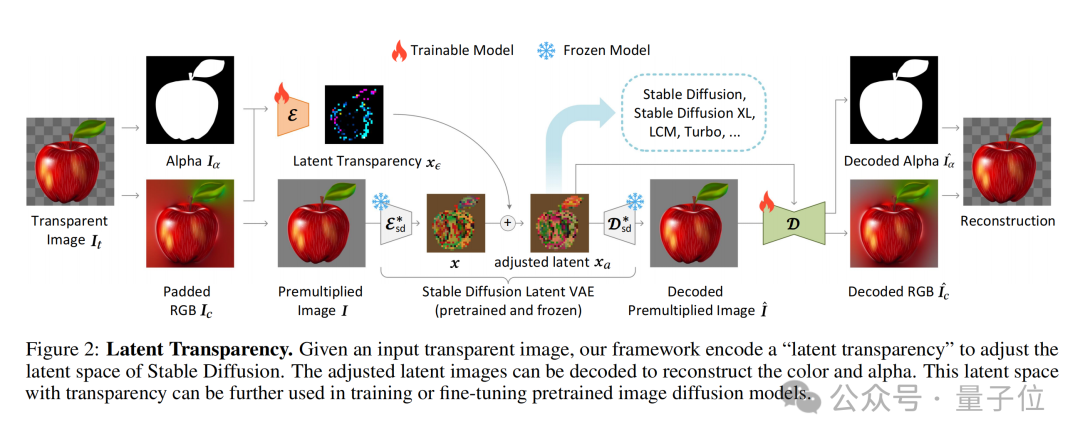
在具体实现上,可以理解为在潜在图像上添加一个精心设计过的小扰动(offset),这种扰动被编码为一个额外的通道,与RGB通道一起构成完整的潜在图像。
为了实现透明度的编码和解码,作者训练了两个独立的神经网络模型:一个是潜在透明度编码器(latent transparency encoder),另一个是潜在透明度解码器(latent transparency decoder)。
编码器接收原始图像的RGB通道和alpha通道作为输入,将透明度信息转换为潜在空间中的一个偏移量。
而解码器则接收调整后的潜在图像和重建的RGB图像,从潜在空间中提取出透明度信息,以重建原始的透明图像。
为了确保添加的潜在透明度不会破坏预训练模型的潜在分布,作者提出了一种“无害性”(harmlessness)度量。
这个度量通过比较原始预训练模型的解码器对调整后潜在图像的解码结果与原始图像的差异,来评估潜在透明度的影响。
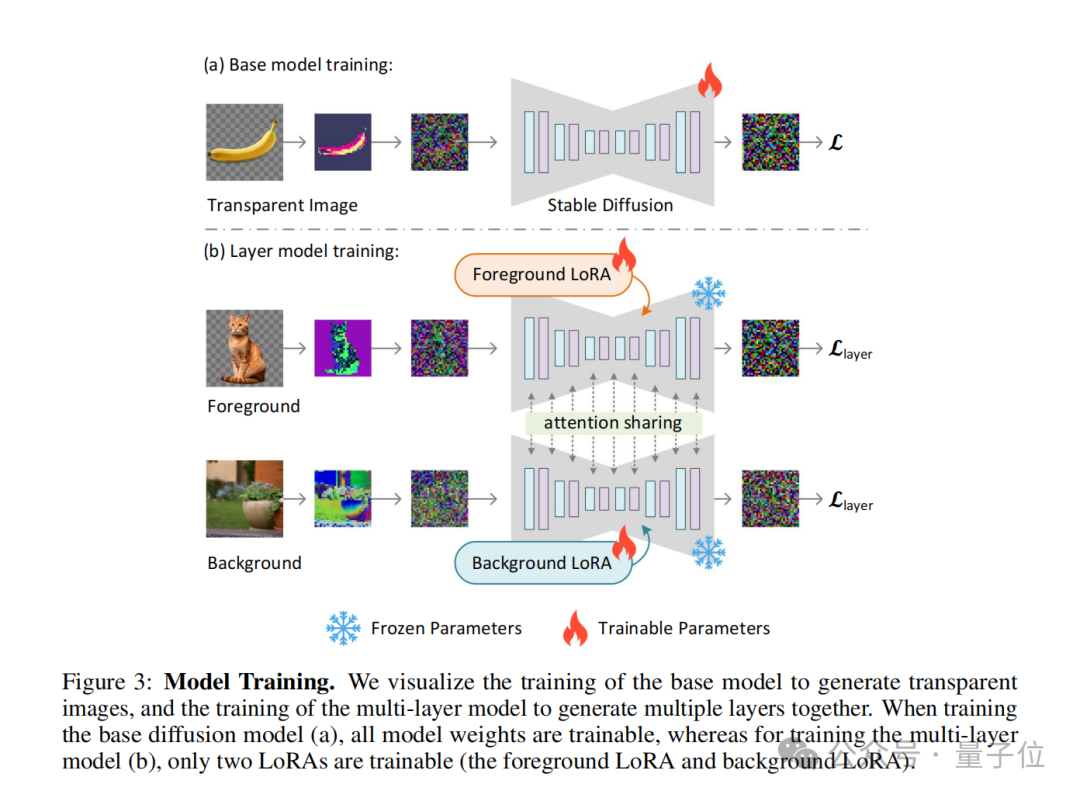
在训练过程中,作者还使用了一种联合损失函数(joint loss function),它结合了重建损失(reconstruction loss)、身份损失(identity loss)和判别器损失(discriminator loss)。
它们的作用分别是:
通过这种方法,任何潜在扩散模型都可以被转换为透明图像生成器,只需对其进行微调以适应调整后的潜在空间。

潜在透明度的概念还可以扩展到生成多个透明图层,以及与其他条件控制系统结合,实现更复杂的图像生成任务,如前景/背景条件生成、联合图层生成、图层内容的结构控制等。



值得一提的是,作者还展示了如何把ControlNet引入进来,丰富LayerDiffusion的功能:

至于LayerDiffusion与传统抠图上的区别,我们可以简单归整为以下几点。
原生生成 vs. 后处理
LayerDiffusion是一种原生的透明图像生成方法,它直接在生成过程中考虑并编码透明度信息。这意味着模型在生成图像的同时就创建了透明度通道(alpha channel),从而产生了具有透明度的图像。
传统的抠图方法通常涉及先生成或获取一个图像,然后通过图像编辑技术(如色键、边缘检测、用户指定的遮罩等)来分离前景和背景。这种方法通常需要额外的步骤来处理透明度,并且可能在复杂背景或边缘处产生不自然的过渡。
潜在空间操作 vs. 像素空间操作
LayerDiffusion在潜在空间(latent space)中进行操作,这是一个中间表示,它允许模型学习并生成更复杂的图像特征。通过在潜在空间中编码透明度,模型可以在生成过程中自然地处理透明度,而不需要在像素级别上进行复杂的计算。
传统的抠图技术通常在像素空间中进行,这可能涉及到对原始图像的直接编辑,如颜色替换、边缘平滑等。这些方法可能在处理半透明效果(如火焰、烟雾)或复杂边缘时遇到困难。
数据集和训练
LayerDiffusion使用了一个大规模的数据集进行训练,这个数据集包含了透明图像对,使得模型能够学习到生成高质量透明图像所需的复杂分布。
传统的抠图方法可能依赖于较小的数据集或者特定的训练集,这可能限制了它们处理多样化场景的能力。
灵活性和控制
LayerDiffusion提供了更高的灵活性和控制能力,因为它允许用户通过文本提示(text prompts)来指导图像的生成,并且可以生成多个图层,这些图层可以被混合和组合以创建复杂的场景。
传统的抠图方法可能在控制方面更为有限,尤其是在处理复杂的图像内容和透明度时。
质量比较
用户研究显示,LayerDiffusion生成的透明图像在大多数情况下(97%)被用户偏好,这表明其生成的透明内容在视觉上与商业透明资产相当,甚至可能更优。
传统的抠图方法可能在某些情况下无法达到同样的质量,尤其是在处理具有挑战性的透明度和边缘时。
总而言之,LayerDiffusion提供的是一种更先进且灵活的方法来生成和处理透明图像。
它在生成过程中直接编码透明度,并且能够产生高质量的结果,这在传统的抠图方法中是很难实现的。
正如我们刚才提到的,这项研究的作者之一,正是大名鼎鼎的ControlNet的发明人——张吕敏。
他本科就毕业于苏州大学,大一的时候就发表了与AI绘画相关的论文,本科期间更是发了10篇顶会一作。
目前张吕敏在斯坦福大学攻读博士,但他为人可以说是非常低调,连Google Scholar都没有注册。
就目前来看,LayerDiffusion在GitHub中并没有开源,但即便如此也挡不住大家的关注,已经斩获660星。
毕竟张吕敏也被网友调侃为“时间管理大师”,对LayerDiffusion感兴趣的小伙伴可以提前mark一波了。
参考链接:
[1]https://arxiv.org/abs/2402.17113
[2]https://twitter.com/op7418/status/1762729887490806159
[3]https://github.com/layerdiffusion/LayerDiffusion
文章来自于微信公众号“量子位”(ID: QbitAI),作者 “金磊”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
