# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
英伟达200亿美元「招安」Groq,推理芯片赛道一夜变天。但在大洋彼岸,一家北大系创业公司刚刚交出了自己的流片答卷。
NVIDIA GTC 2026前夕,AI推理赛道大雨欲来。
国内死磕「超大带宽流式推理」路线的北大系黑马——寒序科技,今日宣布完成数千万元融资。
蛰伏两年,寒序直接亮出硬货:
这场破除「内存墙」的国产算力突围战,正从纸面跃向流片。
大模型硬件的下半场,正迎来一场底层路线的剧烈「倒戈」。
下周,NVIDIA GTC 2026即将开幕。
作为全球AI算力的风向标,业内普遍预测:随着Agent(智能体)与具身智能的大规模落地,算力焦点的天平已彻底向「推理(Inference)」倾斜。
而在此前,业界盛传英伟达已通过约200亿美元的惊人估值级别,以技术授权与核心团队吸纳的方式,实质性绑定了北美明星推理芯片公司Groq。巨头为何对一家初创公司掷出天价?

核心逻辑在于:传统GPU在应对流式大模型推理时,正撞上难以逾越的「内存墙(Memory Wall)」与动态调度延迟。在实时生成的战场上,原本为并行计算而生的GPU,正显得有些「尾大不掉」。
就在英伟达试图在北美完成技术垄断、构筑推理算力护城河的当下,新智元独家获悉:国内专注超快流式推理芯片的创业黑马——「寒序科技」今日正式宣布完成数千万元融资。本轮投资方为启高资本、赛意产业基金,源合资本担任独家财务顾问。
在蛰伏两年后,这家源自北大的硬核团队直接交出了流片答卷,向业界证明:在「确定性流式处理」这条非共识的道路上,中国团队不仅跟得上,而且打得通。
要理解寒序科技的技术护城河,必须先拆解为何连英伟达都要焦虑。
现代GPU(如H100/Blackwell)是为并行计算而生的艺术品。为了兼容通用计算,它支持复杂的软件生态和多类型算子,内部包含极其复杂的动态调度、乱序执行、多级Cache层级以及Warp调度机制。
在「训练阶段(Training)」,这种吞吐量优先的架构通过大规模数据并行,展现了统治级的实力。
但在「推理阶段(Inference)」,风向变了。
大模型生成Token的过程是串行的、流式的。每生成一个Token,本质上都需要执行一次矩阵向量乘(GEMV):
y = Wx
其中W为权重矩阵(Weight Matrix),x为激活向量(Activation Vector)。
这意味着推理阶段并不是「算力受限」问题,而是典型的「带宽受限计算(Bandwidth-bound Computing)」。在Decode(生成)阶段,GPU庞大的浮点运算单元(ALU)大部分时间都在空转,苦苦等待从显存中搬运权重的指令。这种「高射炮打蚊子」的错配,导致了极大的算力闲置与延迟波动。
英伟达的「阳谋」昭然若揭:既然GPU架构在小Batch推理上存在天生缺陷,那就通过资本手段「收编」像Groq这样走LPU(Language Processing Unit)路线的公司,从而在黑盒内部完成对推理架构的补完。
寒序科技(SpinPU-E Series)走的是一条与GPU截然不同、却与Groq核心理念高度共鸣的道路:片上存储权重的流式高带宽架构彻底摒弃硬件调度,采用片上存储权重的流式高带宽架构。
参照张量流式处理器(TSP)的底层原则,寒序科技在产品定义上实现了极致的重构。这种架构在内部被形象地称为「生产线模式」,而非GPU的「计件工厂模式」。
1. 算法指导的流式「确定性」
传统处理器依赖多级缓存和复杂的调度逻辑来处理不规则任务,这在大模型看来是多余的负担。寒序通过神经网络前向传播算法指导的Decode专用性、确定性数据流动规划,实现了超高吞吐的精确调度与处理。
这意味着,数据在芯片内部每一纳秒的位置都是预先确定的,消除了任何因动态争抢资源带来的延迟抖动。
2. 面向算子的数据通路
寒序将芯片内部空间划分为针对Transformer模型优化的特定功能块:片上权重存储、GEMV计算单元、向量运算单元。这种设计让权重读取与计算形成完美流水线,真正做到了「数据到达即计算」。
3. 带宽即生命线
在大模型推理中,决定吞吐量的不是FLOPS,而是带宽利用率。公式如下:
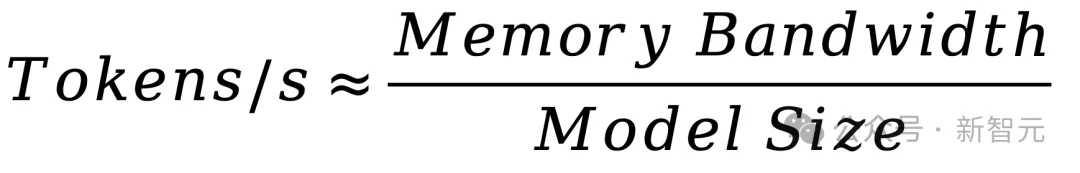
寒序科技的核心竞争力,就在于将这个公式的分子(带宽)推向了物理极限。
对于芯片初创公司而言,从PPT架构图到硅片回片,中间横亘着被称为「死亡之谷」的流片验证期。
知情人士向新智元透露,寒序科技首颗芯片样片的「回片测试」结果远超预期,核心功能与技术逻辑被全面验证。其中最关键的一项硬指标:其「单位面积带宽」达到了100 GB/s/mm²。
这是一个足以让业界侧目的数字。在流式推理架构中,这一指标几乎可以直接映射为推理速度。
在「得带宽者得天下」的推理赛道,这不仅是一个数据,更是一道分水岭。它使得大模型在高吞吐流式输出时,能够真正满足未来AI Agent对低延迟的苛刻要求。
Groq虽然快,但它有一个致命的弱点:存不下。
Groq采用纯SRAM方案,虽然速度极致,但SRAM的密度极低。要运行一个70B规模的模型,往往需要数百张卡集群,其成本和功耗让许多中小企业望而却步。
寒序科技的野心不止于复刻Groq,而是要进化它。
据悉,寒序科技在即将流片的下一代芯片中,首创了「片上MRAM + SRAM」的混合存储架构。
这种「北大系」擅长的底层技术融合,让寒序在保持「确定性流式架构」优势的同时,大幅提升了单片的模型容量存储密度。其目标性能直指2000 Tokens/s的极限。
这是什么概念?
目前市面上最快的对话模型推理速度通常在30-50 Tokens/s。如果寒序的2000 Tokens/s方案量产,意味着:
资料显示,寒序科技成立于2023年8月,核心创始团队源自「北京大学磁学中心」。
这是一个典型的「科学家+工程师」组合。他们在底层新型存储器(MRAM)与存算架构融合领域,拥有深厚的学术积累和工程落地经验。这解释了为什么他们能驾驭这种极其考验硬件底层控制逻辑的异构设计。
有接近本轮融资的投资人对新智元表示:「我们看好寒序,是因为他们没有在GPU的旧地图上寻找新大陆,而是直接重构了推理时代的『底层指令集』。」
寒序选择在GTC 2026前夕释放融资与技术进展信息,显然有着更深层的考量。在算力霸权日益集中的今天,国内需要一种不依赖海外高端HBM供应、能够通过架构创新实现性能弯道超车的方案。
回看GTC的历史,每一代架构都在定义一个时代:
英伟达虽然强大,但没有任何一个王朝能通过一种架构统治所有场景。在大模型从「博学」走向「行动(Agentic AI)」的过程中,对速度、能效比和实时性的要求,正在为像寒序科技这样的垂直创新者留出巨大的窗口。
寒序科技的这笔融资,只是一个开始。随着Agent系统、多模态模型和具身智能的爆发,AI不再只是单轮对话,而是需要持续的规划与环境反馈。
推理,才是AGI的「最后一公里」。
寒序科技已经在这一硬核战场上落下了关键的一子。
下周的圣何塞,老黄或许会拿出更强的Blackwell变体,但在大洋彼岸,国产算力的黑马们,正在用全新的架构逻辑,截击巨头的阳谋。
您认为在推理芯片赛道,国内企业通过「非通用架构」能否实现对NVIDIA的突围?欢迎在评论区留下您的洞见。
关于寒序科技:成立于2023年,致力于开发超大带宽、确定性流式大模型推理芯片,目前已完成四轮融资。其核心技术路径旨在解决大模型推理中的「内存墙」难题,为实时AI应用提供颠覆性基础设施。
文章来自于“新智元”,作者 “桃子 好困”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
