# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着生成式人工智能在医疗领域的加速渗透,越来越多的病历、影像报告及各类临床文本正逐步纳入 AI 参与生成的范畴。这一旨在提升医疗效率的技术革新背后,潜藏着威胁诊断安全性的深层隐患。
最近新加坡国立大学、哈佛大学、斯坦福大学等机构联合团队最新研究显示,当 AI 生成的临床文本被用作训练新一代 AI 模型时,一些罕见但是重要的病理信息会在数据迭代的过程中悄悄地消失,从而使得医疗 AI 整体诊断可靠性在群体上不断下降。
研究团队对临床文本生成、视觉-语言报告、医学图像合成这三个任务下的 80 多万条合成数据进行了系统的分析(如图 1 表示),首次证明了在没有强制性人工验证的情况下,多代自我训练循环会使病理多样性迅速消失,诊断可靠度急剧降低,并且医师评估也表明临床效用的退化。
最后研究团队提出了可以直接融入到目前临床工作流程中的缓解方法,在 AI 全面进入医疗之前给医生提供一条安全的操作路线。
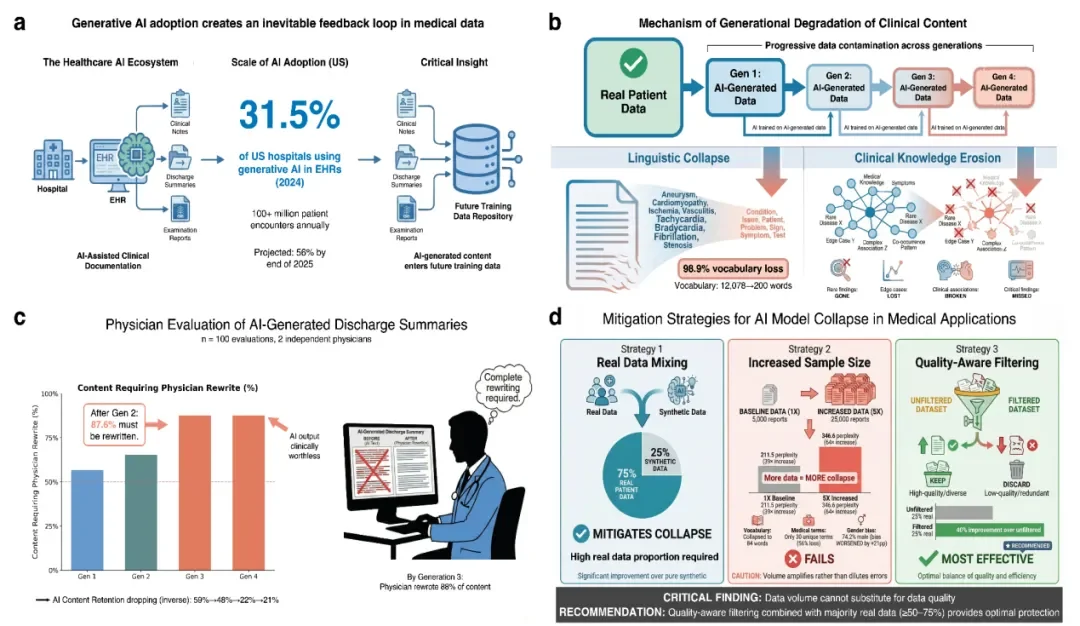
图 1 人工智能生成的数据污染造成的病理多样性丧失、诊断安全性降低的现象以及缓解方法
人工智能正在改变全球医疗文档系统,大型语言模型已经被广泛地应用到临床报告、出院小结、电子健康档案等方面,AI 辅助诊断已经得到广泛的应用。但是其中隐藏的风险是,原来依靠人工建立起来的医疗数据库正在被大量的 AI 生成内容所取代,而且不断保存在诊疗记录中,从而成为下一代 AI 训练的数据来源,形成了一个「生成-训练-再生成」的自循环结构。
在其它领域,自我训练循环被证明会造成「模型退化」,也就是输出的多样性以及保真度会降低。而医学领域的特殊性使得该问题的危害更加严重。医学诊断很大程度上依靠罕见病、非典型临床表现、临床分布尾部细微异常等信息的轻微流失都会造成系统性诊断盲区,增加漏诊风险,加重医疗不公,影响疾病监测。更严重的是,目前医疗 AI 评价标准大多只看表面的语言质量,而没有考虑诊断的准确性,导致这样的模型和临床应用出现退化很难被常规监测到。
研究团队对 216307 份放射学报告、790 份临床笔记、1000 份眼科病历和 9781 张胸部 X 线片进行了多任务实验,研究表明,AI 生成的数据污染造成模型性能退化甚至失效,并不是单一数据类型或者临床任务造成的,而是贯穿临床文本生成、视觉-语言放射学报告、医学图像合成这三个不同的真实临床任务,采用多种代表性模型架构开展实验并且各个任务都存在类似的退化逻辑,即自我训练循环造成病理多样性丧失、诊断可靠度降低,同时又被虚假的预测信心所掩盖。为评估研究结果的临床相关性,研究团队通过对人工智能生成输出进行结构化审查和编辑,并纳入了医师评估环节。
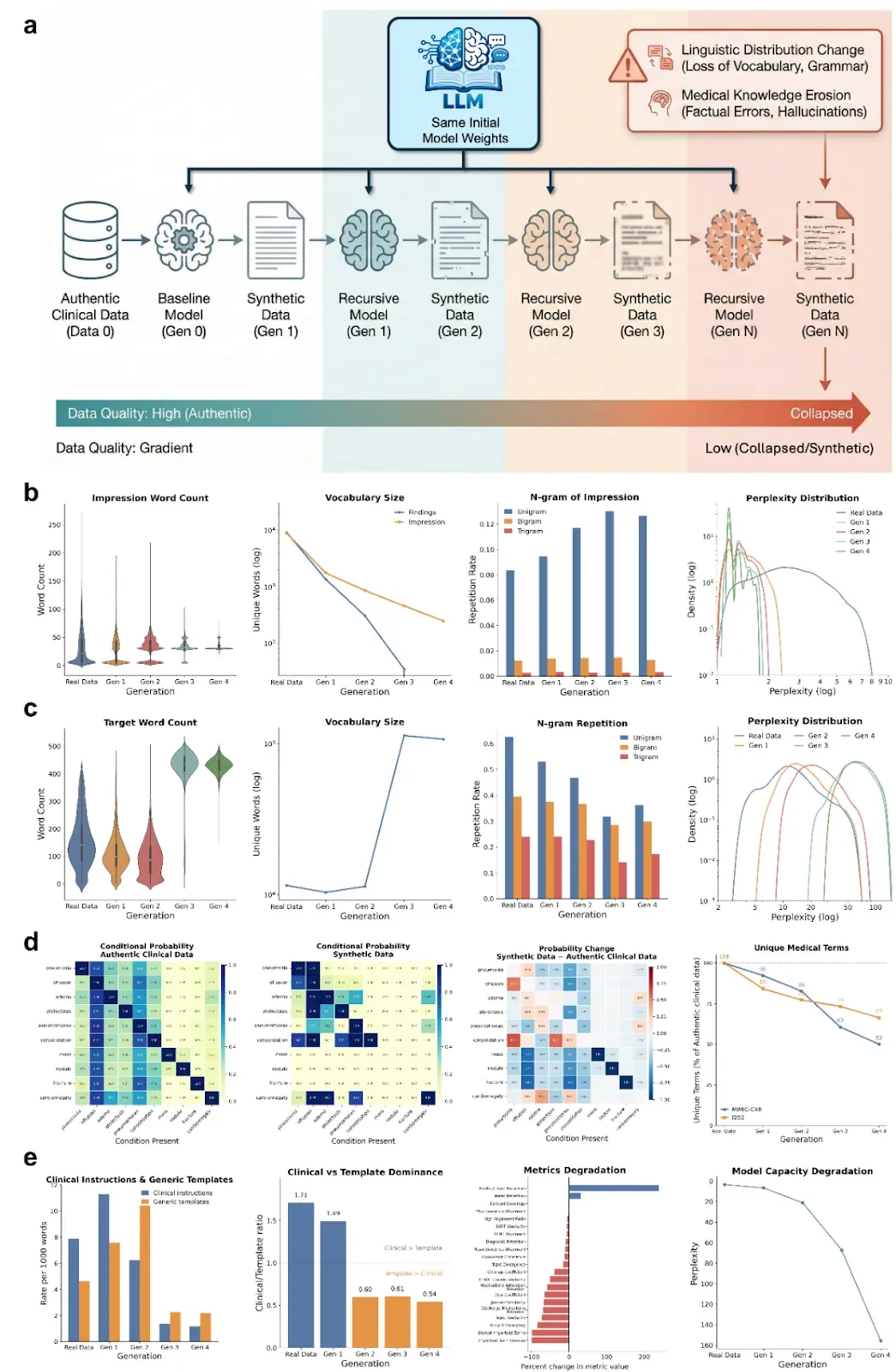 图 2 人工智能生成的数据污染导致临床笔记语言多样性丧失和临床知识退化
图 2 人工智能生成的数据污染导致临床笔记语言多样性丧失和临床知识退化
研究团队首先用多种临床文档和人工智能模型架构,研究用合成临床文本进行自我训练会不会造成语言模型性能下降。图 2 结果表明经过四代自我训练之后,模型就会出现灾难性的退化。放射学报告中印象部分的词汇量由原来的 12078 个减少到现在的 200 个左右,减少了 98.9%;独特医学术语减少 66%,报告公式化趋势明显。类似的结论也可以用在更广泛的临床文书上,例如 790 份 i2b2 临床数据库。随着 AI 模型对于自身产生的合成数据的信心越来越大,但它所具有的真实医疗语言的能力却降低了到原来的四分之一,这给医疗人工智能的部署带来严重的风险,虚假的信心会掩盖患者文书记录中的重大失误。
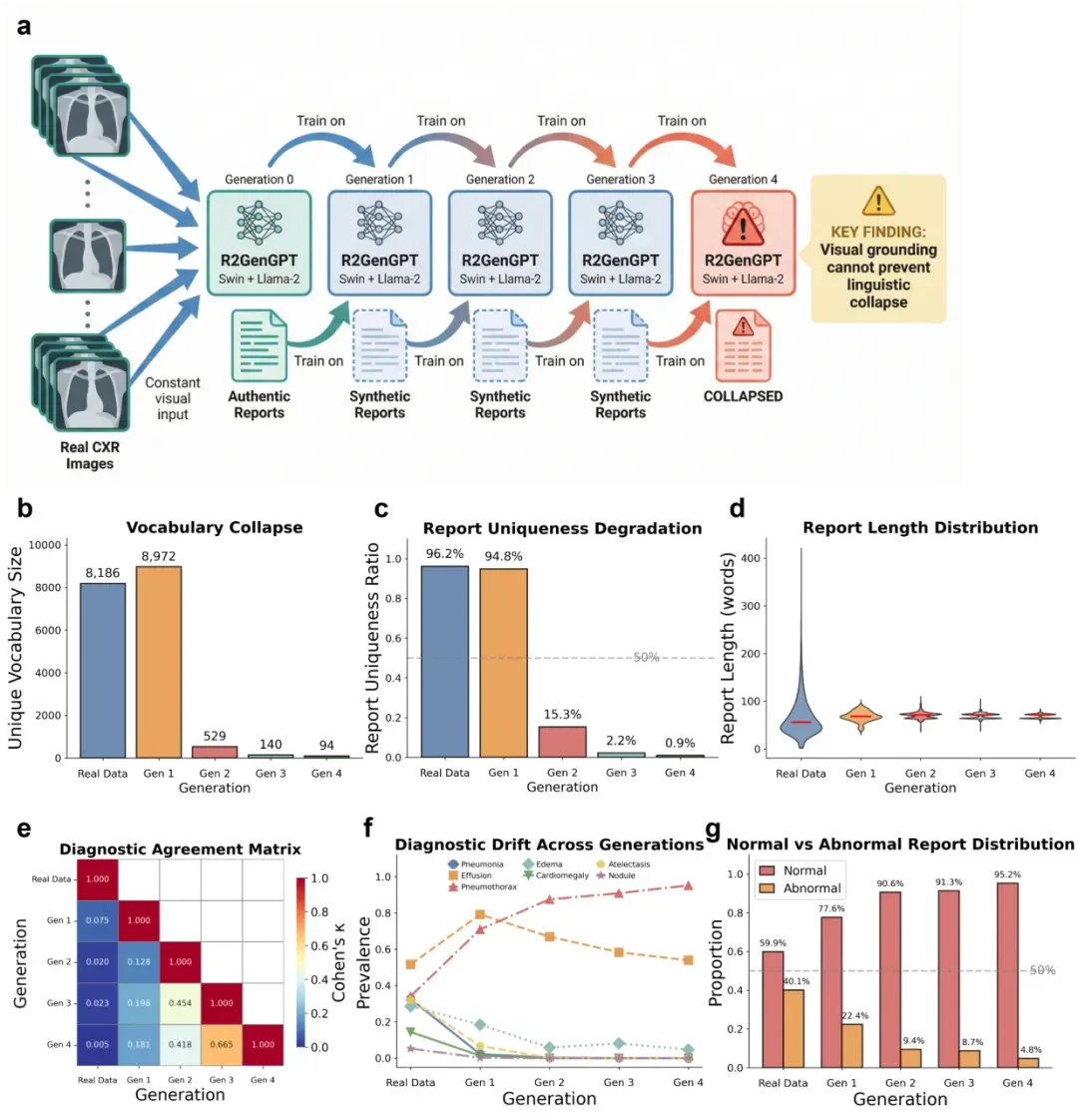
图 3 人工智能生成的数据污染造成基于视觉-语言模型的放射学报告生成出现语言多样性的丧失和临床知识的退化
人工智能在医学影像生成报告的时候,语言退化仍然会发生。研究使用了 Swin-Transformer、Llama-2 的视觉语言模型 R2GenGPT,用真实的胸部 X 线片做输入,只用合成报告来训练。图 3 结果说明即使有真实的图像,模型也会出现严重的退化,报告的唯一性从原来的 96.2% 下降到现在的 0.9%,词汇量从原来的 8186 个减少到现在的 94 个,减少了 98.9%。
更危险的是虚假的安心率急剧上升,当存在危及生命危险的病理情况时,「无急性发现」的错误比例从原来的 13.3% 上升到现在的 40.3%,但是模型本身的置信度很高,因此模型具有临床危险性的结果,不能满足患者的诊疗需求。
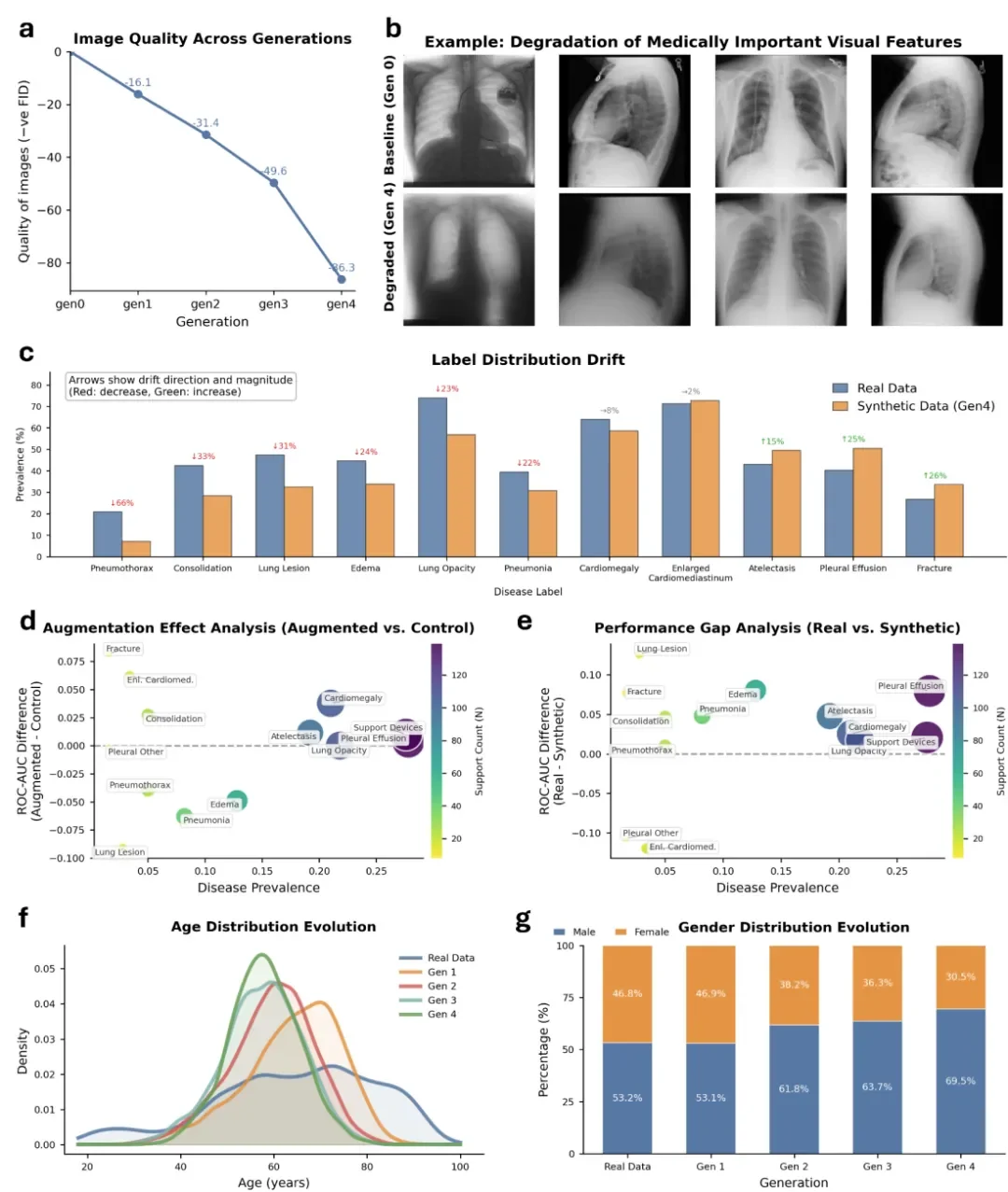
图 4 人工智能生成的数据污染给医学图像合成造成的视觉质量下降、病理表征失真和人口统计学偏差变大
除此之外,人工智能生成的合成医学影像也越来越广泛地被用来进行研究、产品研发等,用以扩充训练数据集、实现隐私保护型的数据共享。但是当这些合成影像被用来训练后续的人工智能模型的时候,生成出来的影像很难体现真实患者人群的多样性,为了探究影像生成会不会出现和文本模型一样的退化模式,研究团队在多轮自我训练循环中,用胸部 X 光片来训练人工智能影像生成模型。从实验结果(图 4)可知,由于人工智能合成的数据污染而产生的视觉退化、病理表征扭曲以及人口统计学偏倚等都会被加重。
为了评价研究结果的临床相关性,对人工智能生成出来的输出做了结构化的审查和编辑,并且加入了医师评价的过程证实临床效用的退化。另外,研究团队对三种应对 AI 数据污染导致模型退化的策略进行了系统的验证,分别为真实数据混合训练为基本方案,当真实数据占比达到 75% 时,可以较好地保持病理的多样性、语言的保真度,从而有效地减少人口统计学偏差;质量感知过滤是在有限真实数据的基础上提高利用效率的一种方式,可以作为增效补充,但是不能代替高比例真实数据的作用;单纯扩增合成数据不仅无效,还会加快模型退化、加重性别偏见,数据数量不能弥补质量缺陷。
研究团队认为应该把数据溯源作为医疗 AI 部署的政策强制要求,实行强制的人工检验制度。仅仅依靠自愿监督是不够的,随着临床 AI 应用规模的扩大,严格的机械验证的经济可行性会越来越低,如果没有制度性的限制,医疗系统就会存在污染未来患者数字生理数据的风险。如果缺少政策强制的溯源机制,那么生成式 AI 部署后就会影响到它本身的医疗数据生态系统,进而引发安全问题。
文章来自于“机器之心”,作者“刘钿渤”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
