# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
南京大学与北京大学提出MorphAny3D,无需训练即可让三维生成模型实现跨类别平滑变形。通过创新注意力机制融合源与目标特征,精准控制结构与时序,轻松完成复杂变形,效果远超传统方法。
三维变形旨在实现源物体到目标物体的平滑过渡。尽管二维图像生成模型已推动图像变形技术取得显著进展,但三维变形因其空间结构的复杂性,仍面临以下瓶颈:
(1)跨类匹配难题:传统的基于匹配的三维变形方法极其依赖源与目标之间的密集对应关系。在处理跨类别物体(如「大象变挖掘机」)时,这种匹配机制往往失效,导致变形过程中结构扭曲甚至崩溃,如图1-(a) 所示。
(2)时序一致性缺失:另一种直观思路是先利用二维变形生成序列,再通过三维生成模型进行「升维」。然而,该方法缺乏帧间约束,难以保证变形的时序一致性,如图1-(b) 所示。

图1:不同变形方案的定性对比图,为控制变形进度的变形权重。
当前,三维生成领域进展迅速,特别是Trellis[1]通过将三维资产编码为结构化隐变量(Structured Latent, SLAT),实现了高质量且多样的图生3D能力。
由此引发思考:能否将SLAT引入三维变形,以充分利用其强大的三维生成先验?
MorphAny3D正是基于此动机,通过深入挖掘SLAT在注意力机制中的融合规律,构建了一系列免训练的高效组件,实现了平滑且合理的跨类别三维变形。
针对这一难题,来自南京大学PCA-Lab的孙晓琨,在张振宇副教授的指导下在CVPR 2026最新工作中提出了免训练三维变形框架MorphAny3D。

项目主页:https://xiaokunsun.github.io/MorphAny3D.github.io
论文链接:https://arxiv.org/pdf/2601.00204
代码链接:https://github.com/XiaokunSun/MorphAny3D
该方法通过在三维生成大模型的注意力机制中巧妙融合原物体与目标物体的特征,成功激活了三维生成先验在变形领域的潜力,实现了高质量的跨类别三维形变。
此外,MorphAny3D具备强大的泛化性,支持解耦变形、双目标变形及三维风格化等多种应用,且可无缝迁移至同类架构的三维生成模型中。代码现已开源!
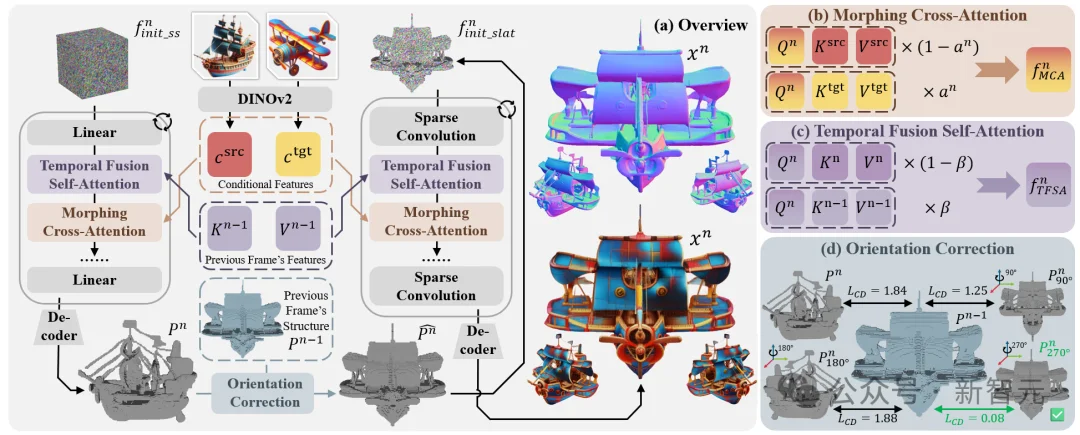
图2:MorphAny3D框架图。
图2-(a) 展示了MorphAny3D的框架。基于作者在交叉/自注意力模块中观察到的SLAT融合规律,作者引入了变形交叉注意力模块(Morphing Cross-Attention, MCA, 图2-(b))和时序融合自注意力模块(Temporal-Fused Self-Attention, TFSA, 图2-(c))以提升变形的合理性与时序连贯性。此外,作者还提出了一种位姿修正策略(Orientation Correction, OC, 图2-(d)),该策略基于对Trellis生成结果位姿分布的统计分析,旨在抑制突发的位姿跳变。

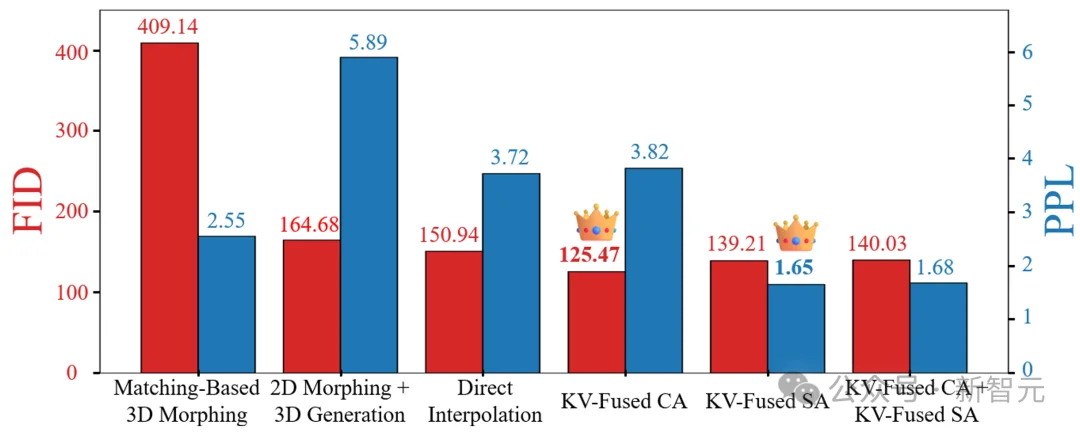
图3:不同变形方案的定量对比图。
SLAT在注意力机制中的融合规律
研究初期,作者尝试了最直接的融合方案:直接对源物体与目标物体的图像条件(Image Conditions)和初始噪声进行插值。观察图1-(c) 可知,该策略效果并不理想,图3中的定量指标FID [2](越低代表合理性越好)与PPL [3](越低代表平滑性越好)也印证了这一点。
为寻求更优解,作者尝试将先前变形工作[3,4]中验证有效的注意力键值融合策略迁移至SLAT中。该策略表示为:
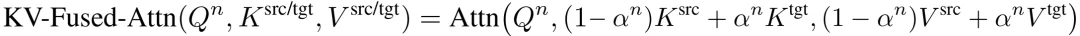
其中代表变形第帧的查询(Query),而和则是分别来自源物体和目标物体的键(Key)和值(Value),为控制变形进度的变形权重。在交叉注意力模块(Cross-Attention)中,键和值来自于引导生成的图像条件;在自注意力模块(Self-Attention)中,键和值则来自于隐特征本身。
作者对比了仅在交叉注意力模块融合(KV-Fused CA)、仅在自注意力模块融合(KV-Fused SA)以及两者同时应用的效果(请看图1-(d, e, f) 和图3),得出以下结论:
由此可见,比起简单的特征插值,更深度的键值融合虽然初步释放了SLAT在变形领域的潜力,但若要实现真正连续且合理的跨类别变形,仍需更进一步的改进。
为此,作者在注意力键值融合基础上进行了针对性修改,从而彻底释放了SLAT的性能潜能。
变形交叉注意力模块(Morphing Cross-Attention, MCA)
如前所述,KV-Fused CA 虽然提升了变形的结构合理性,但不可避免地引入了局部伪影。作者推测,问题的根源在于源图像与目标图像在「逐块(patch-wise)」特征融合过程中产生的语义混乱。具体而言,交叉注意力中的键(Key)和值(Value)源自逐块的DINOv2特征,然而在空间中对齐的源和目标图像特征不一定有相同的语义。这种直接的加权求和,往往导致生成模型接收到语义冲突的引导信息,进而生成扭曲结构。为了验证这一猜想,作者分析了不同机制下头部 SLAT(由红星标记)的注意力图,如图4所示。
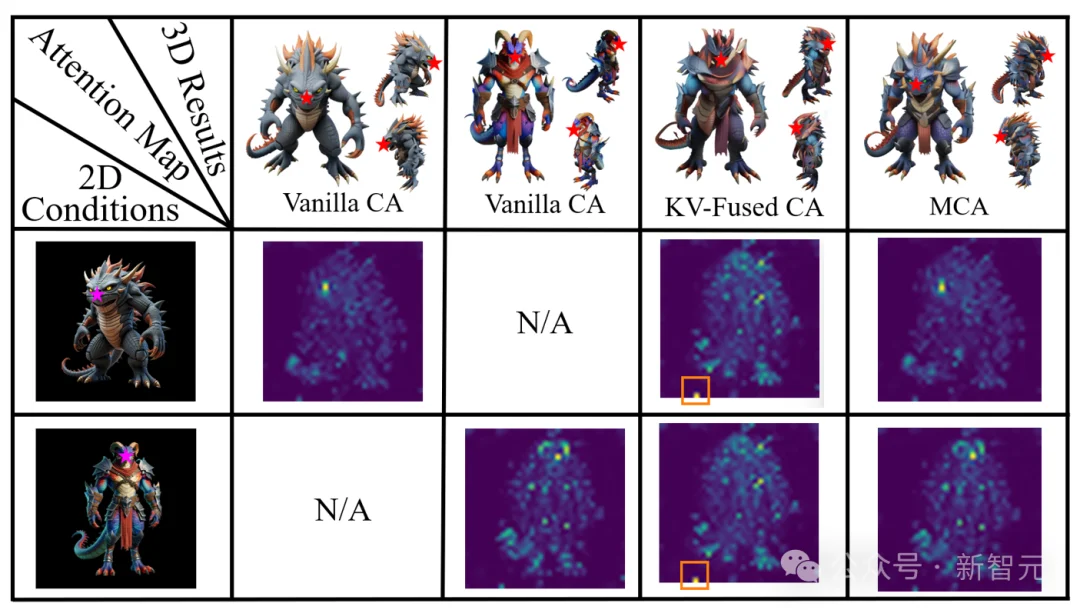
图4:不同交叉注意力机制下的注意力图。红星标记的是头部SLAT,粉红星标记的是对应的头部图像条件。橙色框高亮了KV-Fused CA的不正确的注意力焦点。而MCA保留了正确的、语义一致的注意力,进而避免了如图2-(d) 所示的KV-Fused CA的局部扭曲结构。
观察图4的第二、三列可以发现,原生的交叉注意力在处理头部SLAT时,能精准关注到对应的图像条件(红星标记),证明其具备隐式建立 2D 条件与 3D 隐特征语义对应关系的能力。然而,第四列的KV-Fused CA却错误地聚焦到了背景区域(见橙色框),导致语义不匹配的特征误导了生成过程,最终引发局部畸变。
为此,作者提出变形交叉注意力模块(Morphing Cross-Attention, MCA)。与KV-Fused CA预先融合键值不同,MCA采取了「先独立计算,再加权融合输出」的策略:
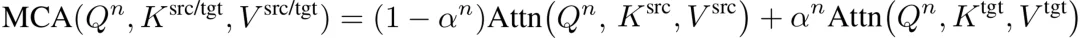
如图4最后一列所示,MCA 通过独立处理源特征和目标特征,保持了对语义一致区域的准确关注,从而避免了在 KV-Fused CA 中观察到的伪影。虽然 MCA 的改动看似只是调整了计算与融合的次序,但其核心价值在于:继承了原生注意力机制「精准聚焦」的特性,保证了条件特征的语义一致性,为高质量的三维跨类变形提供了一种简洁且高效的解法。
时序融合自注意力模块(Temporal-Fused Self-Attention, TFSA)
尽管 MCA 保证了结构与语义的合理性,但由于帧间缺乏显式的时序依赖,变形序列的平滑度仍有提升空间。
为此,作者提出了时序融合自注意力模块(Temporal-Fused Self-Attention, TFSA)。
与KV-Fused SA直接在注意力计算前融合键值不同,TFSA 采用了一种后向的时序约束策略。在生成第帧时,TFSA 将当前帧和前一帧的键和值的注意力输出融合:
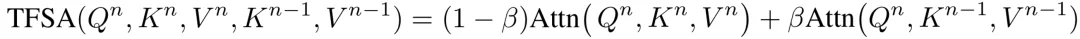
其中 用于控制前一帧记忆对当前帧的影响程度。与KV-Fused SA不同,TFSA融合的是已生成的相邻变形帧特征,这既增强了序列的平滑性,又避免了因全局特征聚合而破坏语义合理性,实现了时序稳定性与空间结构一致性的平衡。
朝向纠正策略(Orientation Correction, OC)
此外作者还观察到在变形过程中物体朝向有时会突然变化,如图5-(a) 所示。即便 TFSA 能够提升时序一致性,但也难以应对这种大幅度的位姿突变。为了解决该问题,作者分析了大量MCA和TFSA下生成的变形序列的朝向突变案例,作者总结出两个特征:朝向跳变主要集中在变形的中间阶段。
此时,源与目标图像条件处于「模棱两可」的过渡态(如图5-(b) 所示),生成模型容易受到干扰。此外朝向的强烈变化高度集中在偏航角(Yaw)的90°、180°、270°,而俯仰角(Pitch)和翻滚角(Roll)则基本保持稳定,如图5-(c) 所示。这表明朝向跳变并非随机噪声,而是源于系统性的偏差。作者推测其根源在于 Trellis 模型习得的生成姿态先验。
通过分析1000个Trellis生成样本的位姿分布,如图5-(d) 所示,作者发现尽管绝大多数样本保持标准姿态,但非标准姿态精确地聚类在上述偏航角上,从而证实了朝向跳变与 Trellis学习到的姿态分布之间的强耦合性。
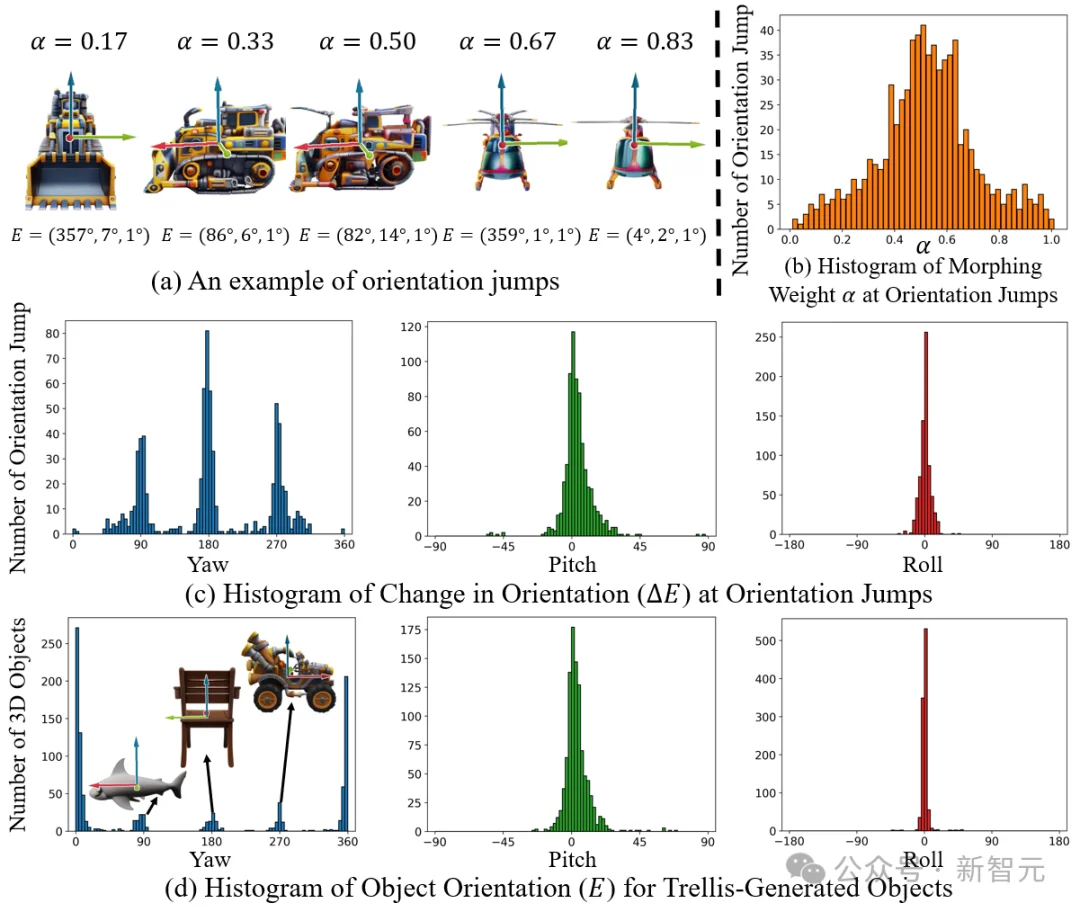
图5:(a) 朝向突变示例,(b) 朝向突变发生时的变形权重分布图,(c) 朝向突变时朝向变化分布图,(d) Trellis生成结果的朝向分布图。
基于这些观察,作者提出朝向纠正策略(Orientation Correction, OC)。其核心流程如下:
在生成第帧稀疏结构后,首先创建四个偏航角旋转候选项,随后计算各候选项与前一帧结构的倒角距离,选择最小的候选项作为修正后的结构。
由于朝向跳变主要发生在变形中段,该策略通过利用早期阶段的稳定姿态,有效地约束了后续生成的物体位姿。当物体朝向未发生跳变时,未经旋转的原始结构因其倒角距离最小而被保留,从而在实现纠偏的同时,确保了变形过程的自然与平滑。
作者将MorphAny3D与四类基准方法对比:(1) 基于匹配的3D/SLAT变形(3DInterp和SLATInterp);(2) 经Trellis升维至3D的2D变形(DiffMorpher[3]和FreeMorph[5]);(3) 直接插值(DirectInterp);(4) MorphFlow[6]。评测指标包括:(a) 衡量合理性的FID;(b) 评估平滑度与时序均匀性的PPL/PDV;(c) 基于VLM的审美得分(AS);(d) 调查问卷获取的用户偏好(UP)。
如表1的定量结果所示,MorphAny3D达到了最先进的性能,在FID、PDV、AS和UP中获得了最好的分数,在PPL中获得了第二好的分数。基于匹配的MorphFlow通过线性插值实现更为平滑的变形,但结构合理性极差,如极高的FID所证明的那样。
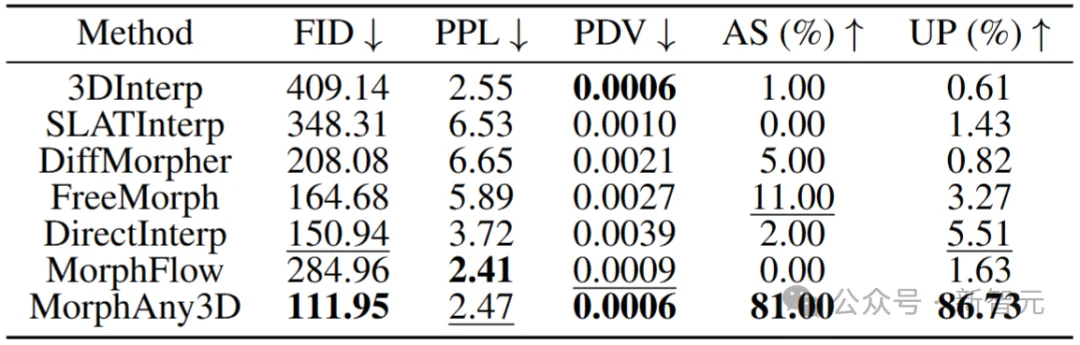
表1:定量结果对比
正如图6定性结果所示,MorphAny3D在各类场景中均能生成平滑且高质量的 3D 变形序列,效果优于所有基准方法。
基于匹配的三维变形方法(3DInterp, SLATInterp, MorphFlow)虽能产生平滑过渡,但往往视觉上不合理。先2D变形后3D升维的方法(DiffMorpher, FreeMorph)尽管利用强大的2D先验确保了结构的合理性,但缺乏3D时序一致性,导致变形序列产生跳变。
DirectInterp的特征融合方式并不适用于 SLAT,导致变形效果不佳。相比之下,MorphAny3D充分释放了SLAT中三维生成先验的潜能,产生了时序平滑、语义明确且视觉逼真的变形效果。
例如,在图6中间的「大象到挖掘机」的变形案例中,该方法能隐式地对齐象鼻与挖掘机吊臂,生成了一个能够合理融合两种概念的混合物体。

图6:定性结果对比
除了基础的三维变形,MorphAny3D凭借其灵活的组件设计,在三维生成领域展现出了广泛的应用潜力:
(1)结构-细节解耦三维变形(Decoupled 3D Morphing):如图7-(a) 所示,通过在Trellis的不同生成阶段有选择地应用上述组件,用户可以实现全局几何结构与局部表面细节的独立解耦控制,从而精准把控变形效果。
(2)双目标三维变形(Dual-Target 3D Morphing):如图7-(b) 所示,通过为生成流程中的不同阶段指定不同的目标物体,MorphAny3D 能够合成具有混合特征的中间过渡形态,实现创新的双目标变形效果。
(3)三维风格迁移(3D Style Transfer):如图 7-(c) 所示,该框架支持保留源物体的核心全局几何结构,同时仅对局部细节进行变形与风格化处理,为三维艺术创作提供了高效的解决方案。

图7:MorphAny3D应用效果图。
此外,得益于MorphAny3D 「无需额外训练(Training-free)」的架构优势,该方法具备极佳的泛化性能,能够无缝适配其他基于SLAT表示的三维生成大模型。如图8所示,MorphAny3D 已成功迁移至Hi3DGen[7]、Text-to-3D Trellis以及最新的Trellis.2[9],并均呈现出高质量的变形效果。

图7:MorphAny3D泛化效果图。
参考资料:
[1] Xiang J, Lv Z, Xu S, et al. Structured 3d latents for scalable and versatile 3d generation[C]. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2025: 21469-21480.
[2] Heusel M, Ramsauer H, Unterthiner T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[J]. Advances in neural information processing systems, 2017, 30.
[3] Zhang K, Zhou Y, Xu X, et al. Diffmorpher: Unleashing the capability of diffusion models for image morphing[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 7912-7921.
[4] Yang S, Lan Y, Chen H, et al. Textured 3d regenerative morphing with 3d diffusion prior[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025: 15159-15170.
[5] Cao Y, Si C, Wang J, et al. Freemorph: Tuning-free generalized image morphing with diffusion model[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025: 18111-18120.
[6] Tsai C J, Sun C, Chen H T. Multiview regenerative morphing with dual flows[C]. European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 492-509.
[7] Ye C, Wu Y, Lu Z, et al. Hi3dgen: High-fidelity 3d geometry generation from images via normal bridging[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025: 25050-25061.
[8] Xiang J, Chen X, Xu S, et al. Native and compact structured latents for 3d generation[J]. arXiv preprint arXiv:2512.14692, 2025.
文章来自于“新智元”,作者 “LRST”。


