# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文是北京大学彭宇新教授团队在文本生成视频领域的最新研究成果,相关论文已被 CVPR 2026 接收。

想象一下,当你让 AI 生成一段「牛奶倒入咖啡产生丝滑旋涡」的视频时,却发现 AI 根本无法生成出你想要的「丝滑旋涡」。虽然如今的 Sora、Wan 等视频生成模型已经能做出如电影般华丽的画面,但它们往往只是「画皮难画骨」—— 因为 AI 并不真正懂得现实世界的物理定律,导致生成的视频经常出现违背常识的「穿帮」镜头。
在物理世界中,液体的流动遵循着复杂的纳维 - 斯托克斯(Navier-Stokes)方程,而刚体的运动则有着严谨的轨迹规律。实现视频生成从「视觉真实」向「物理真实」的跨越,是当前 AIGC 领域的重大挑战。
针对这一难题,北京大学彭宇新教授团队提出了给扩散模型装上「物理引擎」的新方案 ——NS-Diff。该研究将物理约束与强化学习相结合,通过物理动力学检测器和物理条件注入模块,让 AI 像人类一样在生成画面的同时,脑子里还紧绷着一根「物理定律」的弦。
实验表明,NS-Diff 将视频中的运动急动度(jerk)误差降低了 43%,流体发散度降低了 33%,使 AI 生成的每一帧画面不仅好看,而且遵循物理规律。这一成果表明将经典物理约束融入视频生成大模型,是解决视频生成中物理失真问题的有效途径。
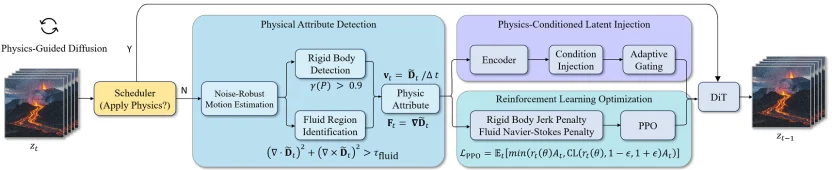
图 1. 物理引导的视频生成强化学习框架 NS-Diff
本文提出了一种物理引导的视频生成强化学习框架 NS-Diff,将物理约束融入视频扩散过程中,以提升生成视频的物理真实感。其主要贡献包括:(1)噪声鲁棒的物理动力学检测器:设计了可在含噪潜在帧中精准分析运动信息的检测器,实现对刚体与流体区域的有效区分。(2)物理条件潜在注入模块:将速度场、形变梯度等关键物理信息编码,并通过交叉注意力机制注入 DiT 去噪器,从而实现对生成过程的物理引导。(3)强化学习优化模块:引入强化学习,通过策略梯度对流体施加简化的纳维 - 斯托克斯约束,对刚体施加最小化急动度(Jerk)原则,确保了视频生成中动态过程的物理合理性。具体如下:
1. 噪声鲁棒的物理动力学检测器
实现物理引导去噪的关键在于高噪声环境下对运动和材料属性的精准估计。由于去噪过程在隐空间(latent space)中运行,直接在 RGB 帧上使用 ARFlow 是不可行的。为此,本文设计了一种结合隐空间解码的运动估计方案,具体流程如下:


2. 物理条件潜在注入

3. 物理引导的强化学习优化

4. 物理引导的自适应激活

1. 实验设置
本文在 PhysVideoBench 以及 UCF-101(包含 13,320 个真实世界人类动作视频)和 WebVid-10M(包含 1000 万个带有文本描述的互联网视频)。本文从物理合理性和视觉质量两个角度对本文方法进行评估。

2. 对比实验结果
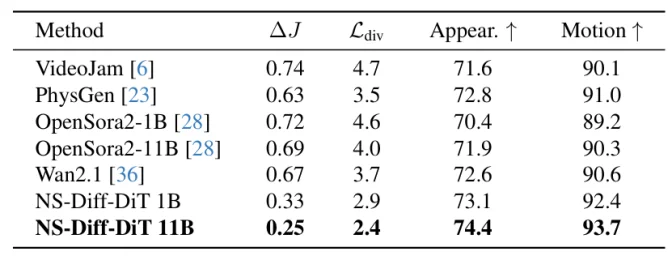
表 1. PhysVideoBench 数据集结果
在 PhysVideoBench 上,NS-Diff 在所有指标上均实现了最佳性能。通过潜空间注入(Latent Injection)以及 Jerk / 散度损失(Jerk/divergence losses)引入物理先验,提升了运动的真实性,尤其是在刚体和流体区域。相比于在给定用户外力情况下模拟刚体动力学的 PhysGen,NS-Diff 在不需要预定义外力或模拟的情况下实现了更好的泛化能力,同时保持了更高的保真度和更低的散度误差。实验表明,本文的方法将 Jerk 误差降低了 43%,流体散度降低了 33%,并使 FVD 提升了 22.7%,实现了更高的物理合理性和视觉质量。
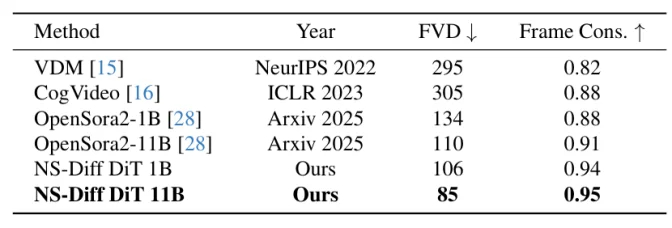
表 2. UCF-101 数据集结果
在 UCF-101 基准测试中,本文的 NS-Diff 模型表现出色。具体而言,NS-Diff DiT 1B 版本的 FVD 为 106,帧一致性(Frame Consistency)达到 0.94;而 NS-Diff DiT 11B 版本则进一步将 FVD 降低至 85,帧一致性提升至 0.95。这表明本文的方法不仅提升了运动的物理准确度,还显著增强了生成视频的时间连贯性。
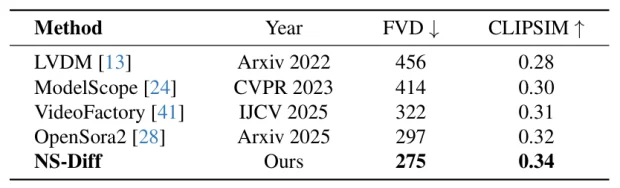
表 3. WebVid-10M 数据集结果
为了评估物理引导学习框架在受限基准测试之外的开放世界场景中的泛化能力,本文在 WebVid-10M 数据集上进行了文本生成视频(Text-to-Video)合成测试。实验旨在测试物理约束(刚体 / 流体动力学)在面对包含新颖物体交互和环境的未知文本描述时,是否仍能保持合理性。本方法在运动质量(FVD)和文图对齐(CLIPSIM)两个指标上均优于 VideoFactory。

图 2. 可视化对比结果
图 2 展示了 NS-Diff 与 ModelScope、PhysGen、Wan2.1 以及 OpenSora2 的视觉效果对比。结果分析表明,本文方法生成的视频在刚体和流体运动方面表现得更加真实,显著减少了诸如物体无故出现或消失、以及非自然的拆分或合并等不符合物理规律的伪影。此外,本文方法还大幅提升了帧间一致性,在处理篮球投篮、火山熔岩流、玻璃破碎等物理密集型场景时,能够比对比模型展现出更高的时间连贯性和运动可信度。
本文提出了一种基于强化学习的物理引导视频扩散框架 NS-Diff。该框架通过抗噪物理动力学检测器,实现了对视频潜空间中刚体与流体区域的精准识别。利用物理条件潜空间注入技术,速度场、变形梯度及材料掩码被有效整合至去噪流程中。此外,本文方法通过强化学习优化机制,将纳维 - 斯托克斯方程与最小急动度(Minimum-Jerk)原则转化为训练约束,强制模型遵循物理运动规律。实验结果表明,NS-Diff 在 PhysVideoBench、UCF-101 等多个基准数据集上超过现有方法,在显著降低物理运动误差的同时,确保了视觉生成质量。研究表明,将经典物理约束深度融合于生成模型,是解决视频生成中物理失真问题的有效途径。
文章来自于“机器之心”,作者 “北京大学彭宇新教授团队”。



