# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Stability AI在发布了Stable Diffusion 3之后,今天公布了详细的技术报告。
论文深入分析了Stable Diffusion 3的核心技术——改进版的Diffusion模型和一个基于DiT的文生图全新架构!

报告地址:
https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
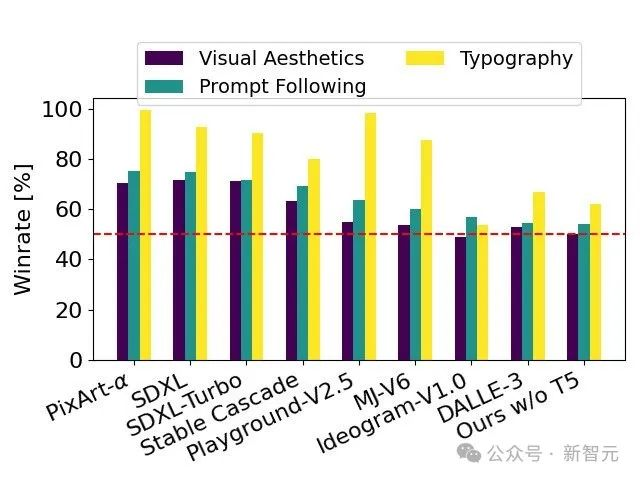
通过人类评价测试,Stable Diffusion 3在字体设计和对提示的精准响应方面,超过了DALL·E 3、Midjourney v6和Ideogram v1。
Stability AI新开发的多模态扩散Transformer(MMDiT)架构,采用了分别针对图像和语言表示的独立权重集,与SD 3的早期版本相比,显著提升了对文本的理解和文字的拼写能力。

在人类反馈的基础之上,技术报告将SD 3于大量开源模型SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α,以及闭源模型DALL·E 3、Midjourney v6 和 Ideogram v1进行了详细的对比评估。
评估员根据与给定提示的一致性、文本的清晰度以及图像的整体美观度选择了每个模型的最佳输出:

测试结果显示,无论是在遵循提示的准确性、文本的清晰呈现还是图像的视觉美感方面,Stable Diffusion 3都达到或超过了当前文生图生成技术的最高水平。
完全没有针对硬件进行过优化的SD 3模型具有8B参数,能够在24GB显存的RTX 4090消费级GPU上运行,并且在使用50个采样步骤的情况下,生成1024x1024分辨率的图像需耗时34秒。
此外,Stable Diffusion 3在发布时将提供多个版本,参数范围从8亿到80亿,从而能以进一步降低使用的硬件门槛。

在文生图的过程中,模型需同时处理文本和图像这两种不同的信息。所以作者将这个新框架称之为MMDiT。
在文本到图像生成的过程中,模型需同时处理文本和图像这两种不同的信息类型。这就是作者将这种新技术称为MMDiT(多模态Diffusion Transformer的简称)的原因。
与Stable Diffusion之前的版本一样,SD 3采用了预训练模型来提取适合的文本和图像的表达形式。
具体而言,他们利用了三种不同的文本编码器——两个CLIP模型和一个T5 ——来处理文本信息,同时使用了一个更为先进的自编码模型来处理图像信息。
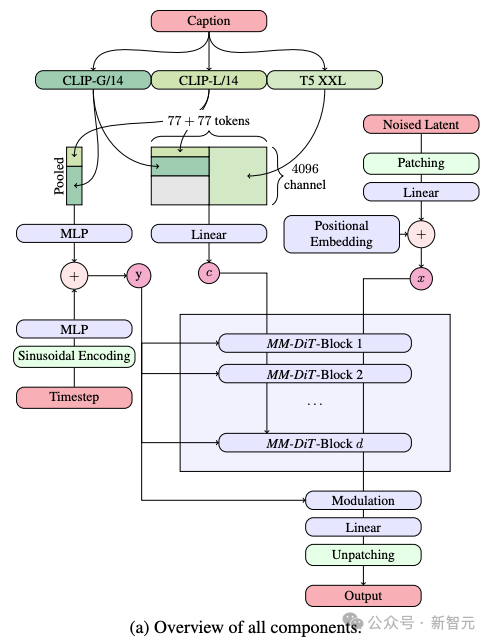
SD 3的架构是在Diffusion Transformer(DiT)的基础上建立的。由于文本和图像信息的差异,SD 3为这两种信息各自设置了独立的权重。
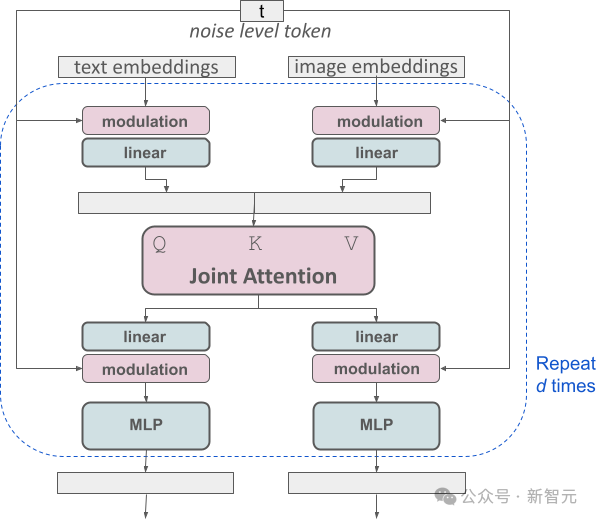
这种设计相当于为每种信息类型配备了两个独立的Transformer,但在执行注意力机制时,会将两种信息的数据序列合并,这样就可以在各自的领域内独立工作的同时,能保持够相互参考和融合。
通过这种独特的构架,图像和文本信息之间可以相互流动和交互,从而在生成的结果中提高对内容的整体理解和视觉表现。
而且,这种架构未来还可以轻松扩展到其他包括视频在内的多种模态。

得益于SD 3在遵循提示方面的进步,模型能够精确生成集中于多种不同主题和特性的图像,同时在图像风格上也保持了极高的灵活性。

除了推出的全新Diffusion Transformer构架之外,SD 3对于Diffusion模型也进行了重大的改进。
SD 3采用了Rectified Flow(RF)策略,将训练数据和噪声沿着直线轨迹连接起来。
这种方法让模型的推理路径更加直接,因此可以通过更少的步骤完成样本的生成。
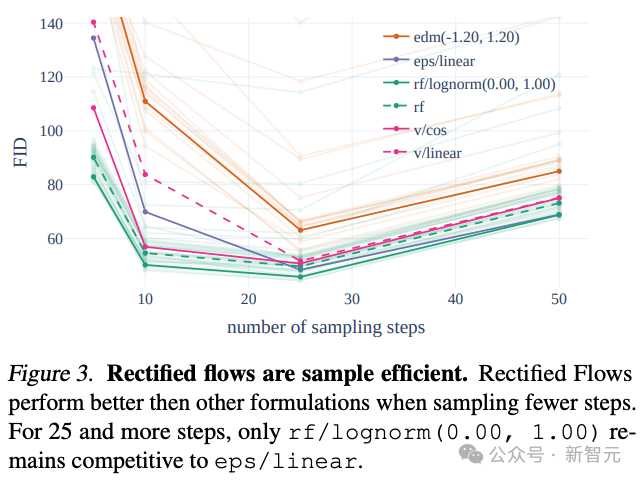
作者在训练流程中引入了一种创新的轨迹采样计划,特别增加了对轨迹中间部分的权重,这些部分的预测任务更具挑战性。
通过与其他60种扩散轨迹(例如 LDM、EDM 和 ADM)进行比较,作者发现尽管之前的RF方法在少步骤采样中表现更佳,但随着采样步骤增多,性能会慢慢下降。
为了避免这种情况的出现,作者提出的加权RF方法,就能够持续提升模型性能。
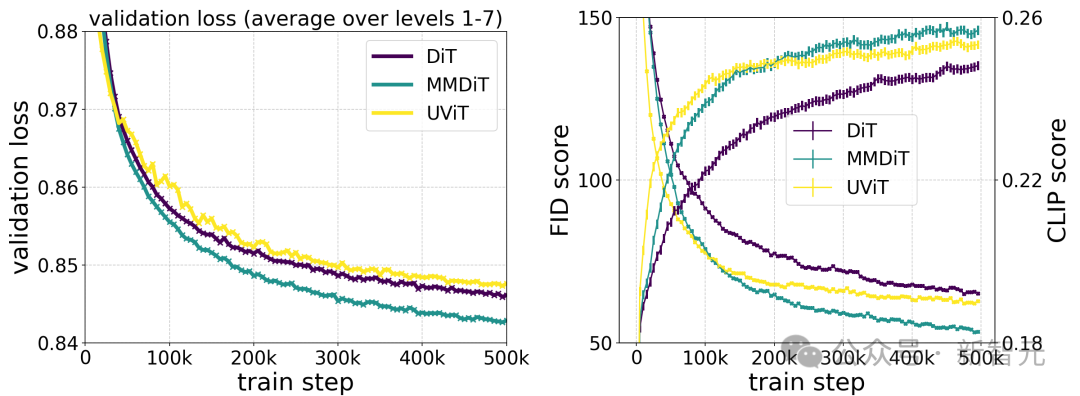
Stability AI训练了多个不同规模的模型,从 15 个模块、450M参数到38个模块、8B参数,发现模型大小和训练步骤都能平滑地降低验证损失。
为了验证这是否意味着模型输出有实质性的改进,他们还评估了自动图像对齐指标和人类偏好评分。
结果表明,这些评估指标与验证损失强相关,说明验证损失是衡量模型整体性能的有效指标。
此外,这种扩展趋势没有达到饱和点,让我们对未来能够进一步提升模型性能持乐观态度。
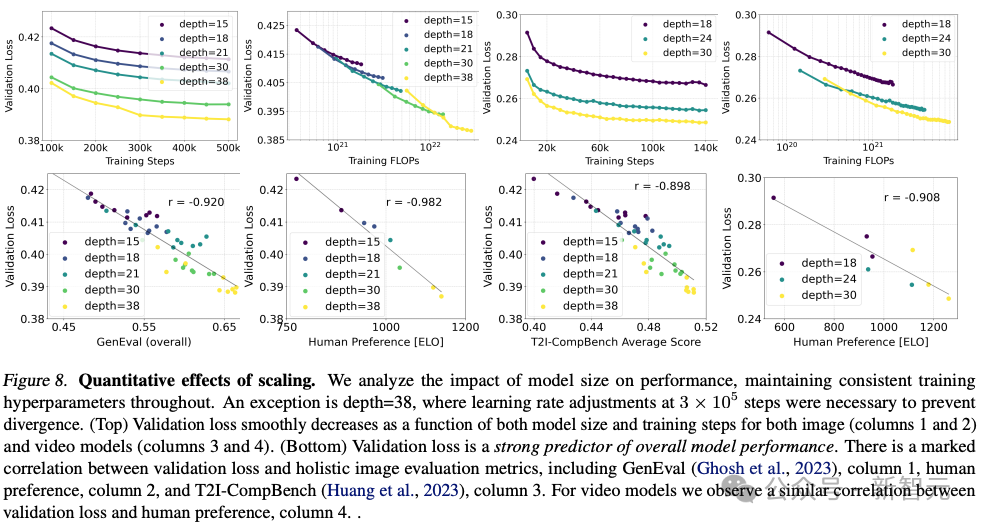
作者在256 *256像素分辨率下,在4096的批大小下,用不同参数数对模型进行了500k步训练。

上图说明了长时间训练较大模型对样本质量的影响。
上表显示了GenEval的结果。当使用作者提出的训练方法并提高训练图像的分辨率时,最大的模型在大多数类别中都表现出色,在总分上超过了 DALL·E 3。
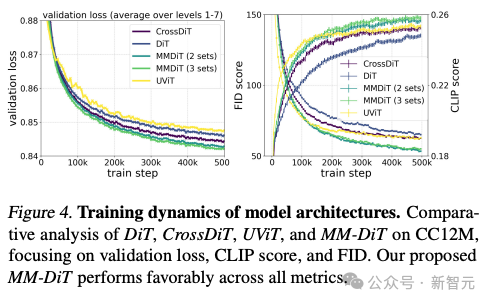
根据作者对不同构架模型的测试对比,MMDiT效果非常好,超过了DiT,Cross DiT,UViT,MM-DiT。
通过在推理阶段去除占用大量内存的4.7B参数的T5文本编码器,SD 3的内存需求得到了大幅降低,而性能损失微乎其微。
去除这个文本编码器不会影响图像的视觉美感(不使用T5的胜率为 50%),只会略微降低文本的准确遵循能力(胜率为46%)。
然而,为了充分发挥SD 3在生成文字的能力,作者还是建议使用T5编码器。
因为作者发现在没有它的情况下,排版生成文字的性能会有更大的下降(胜率为 38%)。

网友们对Stability AI不断撩拨用户但是不让用的行为显得有些不耐烦了,纷纷催促赶快上线让大家使用。
看了技术报考后,网友说看来现在生图圈子要成第一个开源碾压闭源的赛道了!
参考资料:
https://stability.ai/news/stable-diffusion-3-research-paper
文章来自于微信公众号 “新智元”




