# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
模型量化是模型压缩与加速中的一项关键技术,其将模型权重与激活值量化至低 bit,以允许模型占用更少的内存开销并加快推理速度。对于具有海量参数的大语言模型而言,模型量化显得更加重要。例如,GPT-3 模型的 175B 参数当使用 FP16 格式加载时,需消耗 350GB 的内存,需要至少 5 张 80GB 的 A100 GPU。
但若是可以将 GPT-3 模型的权重压缩至 3bit,则可以实现单张 A100-80GB 完成所有模型权重的加载。
现有的大语言模型后训练量化算法依赖于手工制定量化参数,优于缺乏相应的优化过程,导致面对低 bit 量化时,现有的方法都表现出显著的性能下降。尽管量化感知训练在确定最佳量化配置方面是有效的,但它需要引入大量额外的训练开销和训练数据。尤其是大语言模型本身的计算量进一步阻碍了量化感知训练在大预言模型量化上的应用。
这引出一个问题:我们能否在保持后训练量化的时间和数据效率的同时,达到量化感知训练的性能?
为了解决大语言模型后训练量化中的量化参数优化问题,来自上海人工智能实验室、香港大学、香港中文大学的研究者们提出了《OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models》。该算法同时支持大语言模型中的权重与激活值的量化,且覆盖多种量化 bit 位设置。

arXiv 论文地址:https://arxiv.org/abs/2308.13137
OpenReview 论文地址:https://openreview.net/forum?id=8Wuvhh0LYW
代码地址:https://github.com/OpenGVLab/OmniQuant

如上图所示,OmniQuant 是一种针对大语言模型(LLM)的可微分量化技术,同时支持仅权重量化和权重激活值同时量化。并且,其在实现高性能量化模型的同时,保持了后训练量化的训练时间高效性和数据高效性。例如,OmniQuant 可在单卡 A100-40GB 上,在 1-16 小时内完成对 LLaMA-7B ~ LLaMA70B 模型量化参数的更新。
为了达到这个目标,OmniQuant 采用了一个 Block-wise 量化误差最小化框架。同时,OmniQuant 设计了两种新颖的策略来增加可学习的量化参数,包括可学习的权重裁剪(Learnable Weight Clipping,LWC),以减轻量化权重的难度,以及一个可学习的等价转换(Learnable Equivalent Transformation, LET),进一步将量化的挑战从激活值转移到权重。
此外,OmniQuant 引入的所有可学习参数在量化完成后可以被融合消除,量化模型可以基于现有工具完成在多平台的部署,包括 GPU、Android、IOS 等等。
Block-wise 量化误差最小化
OmniQuant 提出了一个新的优化流程,该流程采用 Block-wise 量化误差最小化,并且以可微分的方式优化额外的量化参数。其中,优化目标公式化如下:
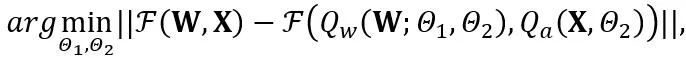
其中 F 代表 LLM 中一个变换器块的映射函数,W 和 X 分别是全精度权重和激活,![]() 和
和![]() 分别代表权重和激活量化器,
分别代表权重和激活量化器,![]() 和
和![]() 分别是可学习的权重裁剪(LWC)和可学习的等价转换(LET)中的量化参数。OmniQuant 安装 Block-wise 量化按顺序量化一个 Transformer Block 中的参数,然后再移动到下一个。
分别是可学习的权重裁剪(LWC)和可学习的等价转换(LET)中的量化参数。OmniQuant 安装 Block-wise 量化按顺序量化一个 Transformer Block 中的参数,然后再移动到下一个。
可学习的权重裁剪 (LWC)
等价转换在模型权重和激活值之间进行量级迁移。OmniQuant 采用的可学习等价转换使得在参数优化过程中会使得模型权重的分布随着训练不断地发生改变。此前直接学习权重裁剪阈值的方法 [1,2] 只适用于权重分布不发生剧烈改变的情况,否则会难以收敛。基于此问题,与以往方法直接学习权重裁剪阈值不同,LWC 通过以下方式优化裁剪强度:
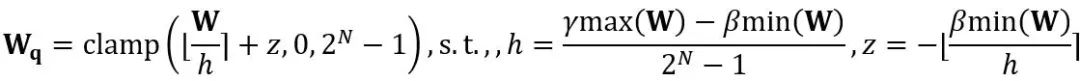
其中 ⌊⋅⌉ 表示取整操作。N 是目标位数![]() 。和 W 分别表示量化后和全精度的权重。h 是权重的归一化因子,z 是零点值。裁剪(clamp)操作限制量化值在 N 位整数的范围内,即
。和 W 分别表示量化后和全精度的权重。h 是权重的归一化因子,z 是零点值。裁剪(clamp)操作限制量化值在 N 位整数的范围内,即![]() 。在上式中,
。在上式中,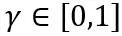 和
和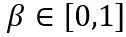 分别是权重上界和下界的可学习裁剪强度。因此,在优化目标函数中
分别是权重上界和下界的可学习裁剪强度。因此,在优化目标函数中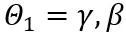 。
。
可学习的等价转换 (LET)
除了通过优化裁剪阈值来实现更适合量化的权重的 LWC 之外,OmniQuant 通过 LET 进一步降低激活值的量化难度。考虑到 LLM 激活值中的异常值是存在于特定通道,以前的方法如 SmoothQuant [3], Outlier Supression+[4] 通过数学上的等价转换将量化的难度从激活值转移到权重。
然而,手工选择或者贪心搜索得到的等价转换参数会限制量化模型的性能。得益于 Block-wise 量化误差最小化的引入,OmniQuant 的 LET 可以以一种可微分的方式确定最优的等价转换参数。受 Outlier Suppression+~\citep {outlier-plus} 的启发,采用了通道级的缩放和通道级的移位来操纵激活分布,为激活值中的异常值问题提供了一个有效的解决方案。具体来说,OmniQuant 探索了线性层和注意力操作中的等价转换。
线性层中的等价转换:线性层接受输入的令牌序列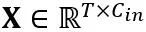 ,其中 T 是令牌长度,是权重矩阵
,其中 T 是令牌长度,是权重矩阵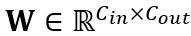 和偏置向量
和偏置向量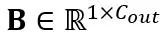 的乘积。数学上等效的线性层表达为:
的乘积。数学上等效的线性层表达为:
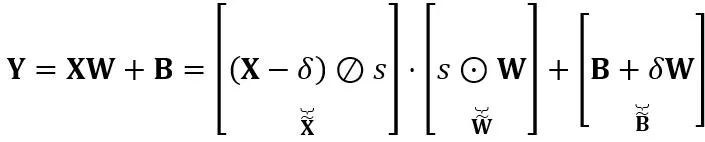
其中 Y 代表输出,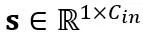 和
和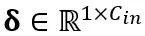 分别是通道级的缩放和移位参数,
分别是通道级的缩放和移位参数,![]() 和
和![]() 分别是等效激活、权重和偏置,⊘ 和 ⊙ 代表元素级的除法和乘法。通过上式等价转换,激活值被转换为更易于量化的形式,代价是增加了权重的量化难度。从这个意义上说,LWC 可以提高由 LET 实现的模型量化性能,因为它使权重更易于量化。最后,OmniQuant 对转换后的激活和权重进行量化,如下所示
分别是等效激活、权重和偏置,⊘ 和 ⊙ 代表元素级的除法和乘法。通过上式等价转换,激活值被转换为更易于量化的形式,代价是增加了权重的量化难度。从这个意义上说,LWC 可以提高由 LET 实现的模型量化性能,因为它使权重更易于量化。最后,OmniQuant 对转换后的激活和权重进行量化,如下所示
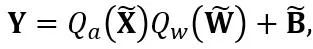
其中 Q_a 是普通的 MinMax 量化器,Q_w 是带有可学习权重裁剪(即所提出的 LWC)的 MinMax 量化器。
注意力操作中的等价转换:除了线性层之外,注意力操作也占据了 LLM 的大部分计算。此外,LLM 的自回归推理模式需要为每个 token 存储键值(KV)缓存,这对于长序列来说导致了巨大的内存需求。因此,OmniQuant 也考虑将自主力计算中的 Q/K/V 矩阵量化为低位。具体来说,自注意力矩阵中的可学习等效变换可以写为:
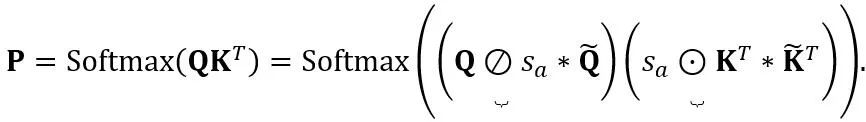
其中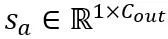 缩放因子。自注意力计算中的量化计算表达为
缩放因子。自注意力计算中的量化计算表达为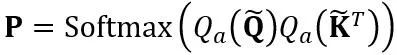 。在这里 OmniQuant 也使用 MinMax 量化方案作为
。在这里 OmniQuant 也使用 MinMax 量化方案作为![]() 来量化
来量化![]() 矩阵。所以,最终优化目标函数中的
矩阵。所以,最终优化目标函数中的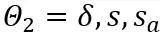 。
。
伪代码

OmniQuant 的伪算法如上图所示。注意,LWC 与 LET 引入的额外参数在模型量化完后都可以被消除,即 OmniQuant 不会给量化模型引入任何额外开销,因此其可直接适配于现有的量化部署工具。
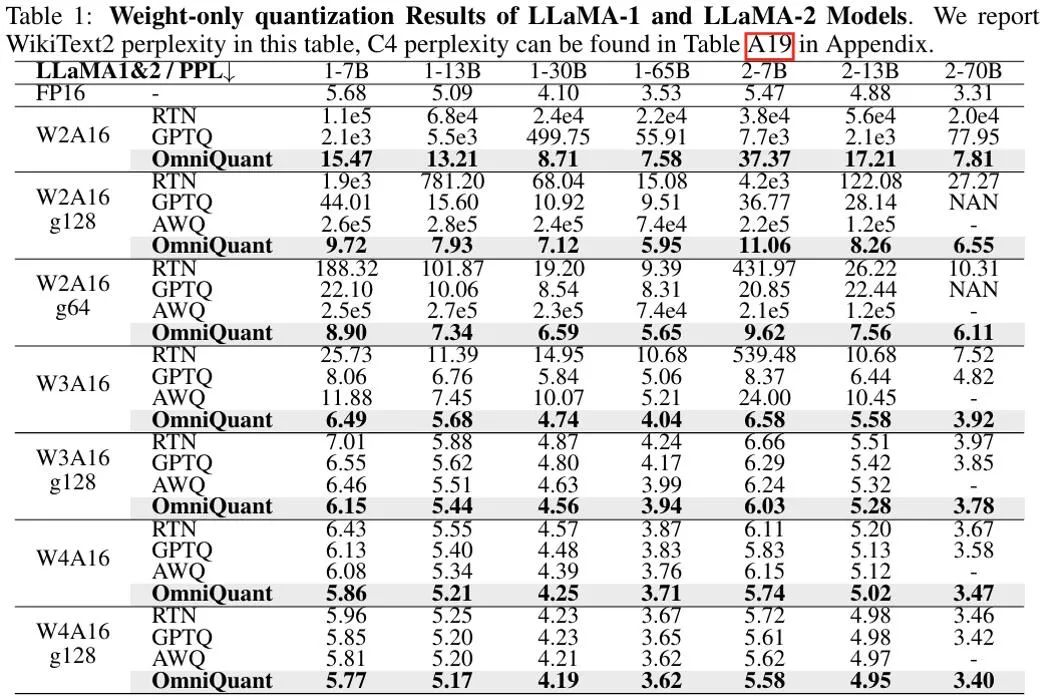
上图显示了 OmniQuant 在 LLaMA 模型上仅权重量化结果的实验结果,更多 OPT 模型结果详见原文。可以看出,OmniQuant 在各种 LLM 模型(OPT、LLaMA-1、LLaMA-2)以及多样化的量化配置(包括 W2A16、W2A16g128、W2A16g64、W3A16、W3A16g128、W4A16 和 W4A16g128)中,始终优于以前的 LLM 仅权重量化方法。同时,这些实验表明了 OmniQuant 的通用性,能够适应多种量化配置。例如,尽管 AWQ [5] 在分组量化方面特别有效,但 OmniQuant 在通道级和分组级量化中均显示出更优的性能。此外,随着量化比特位数的减少,OmniQuant 的性能优势变得更加明显。
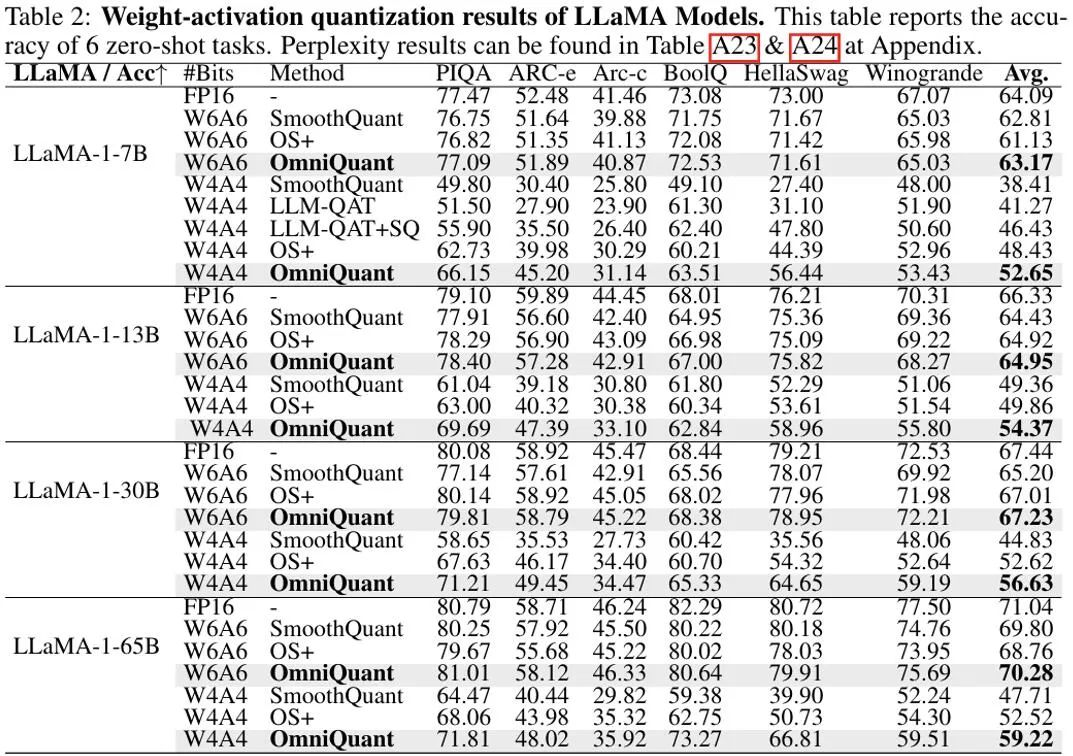
在权重和激活值都量化的设置中中,实验主要关注点在于 W6A6 和 W4A4 量化。实验设置中排除了 W8A8 量化,因为与全精度模型相比,此前的 SmoothQuant 几乎可以实现无损的 W8A8 模型量化。上图显示了 OmniQuant 在 LLaMA 模型上权重激活值都量化结果的实验结果。值得注意的是,在 W4A4 量化的不同模型中,OmniQuant 显著提高了平均准确率,增幅在 + 4.99% ∼ +11.80% 之间。特别是在 LLaMA-7B 模型中,OmniQuant 甚至以 + 6.22% 的显著差距超越了最近的量化感知训练方法 LLM-QAT [6]。这一改进证明了引入额外可学习参数的有效性,这比量化感知训练所采用的全局权重调整更为有益。
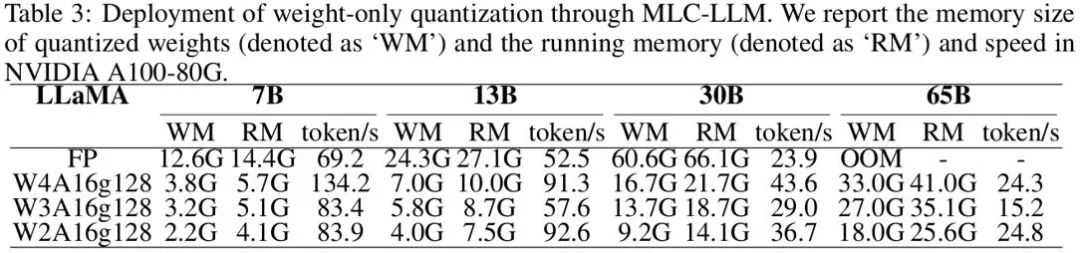
同时,使用 OmniQuant 量化的模型可以在 MLC-LLM [7] 上实现无缝部署。上图展示了 LLaMA 系列量化模型在 NVIDIA A100-80G 上的内存需求和推理速度。
Weights Memory (WM) 代表量化权重存储,而 Running Memory (RM) 表示推理过程中的内存,后者更高是因为保留了某些激活值。推理速度是通过生成 512 个令牌来衡量的。显而易见,与 16 位全精度模型相比,量化模型显著减少了内存使用。而且,W4A16g128 和 W2A16g128 量化几乎使推理速度翻倍。
值得注意的是,MLC-LLM [7] 也支持 OmniQuant 量化模型在其余平台的部署,包括 Android 手机和 IOS 手机。如上图所示,近期的应用 Private LLM 即是利用 OmniQuant 算法来完成 LLM 在 iPhone、iPad,macOS 等多平台的内存高效部署。
OmniQuant 是一种将量化推进到到低比特格式的先进大语言模型量化算法。OmniQuant 的核心原则是保留原始的全精度权重的同时添加可学习的量化参数。它利用可学习的权重才接和等价变换来优化权重和激活值的量化兼容性。在融合梯度更新的同时,OmniQuant 保持了与现有的 PTQ 方法相当的训练时间效率和数据效率。此外,OmniQuant 还确保了硬件兼容性,因为其添加的可训练参数可以被融合到原模型中不带来任何额外开销。
Reference
[1] Pact: Parameterized clipping activation for quantized neural networks.
[2] LSQ: Learned step size quantization.
[3] Smoothquant: Accurate and efficient post-training quantization for large language models.
[4] Outlier suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling.
[5] Awq: Activation-aware weight quantization for llm compression and acceleration.
[6] Llm-qat: Data-free quantization aware training for large language models.
[7] MLC-LLM:https://github.com/mlc-ai/mlc-llm
文章来自于微信公众号 “机器之心”,作者 “邵文琪”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
