# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Anthropic 研究科学家 Nicholas Carlini 在 [un]prompted 2026 安全会议上用不到 25 分钟演示了一件事:语言模型现在可以自主找到并利用零日漏洞,目标包括 Linux 内核这种被人类安全专家审计了几十年的软件。
Carlini 在安全和机器学习的交叉领域研究了十多年,先后在 Google Brain 和 DeepMind 工作,拿过 IEEE S&P、USENIX Security、ICML 的最佳论文奖。他在演讲中反复强调自己曾经是 LLM 的怀疑者。
Nicholas Carlini 在 [un]prompted 2026 现场开场,自我介绍为 Anthropic 研究科学家并给出演讲主题“Black-hat LLMs”
演讲视频:https://www.youtube.com/watch?v=1sd26pWhfmg
要点速览:
Carlini 展示了他们团队找漏洞用的“脚手架”。说是脚手架,其实就是在虚拟机里跑 Claude Code,加上 --dangerously-skip-permissions 参数让模型可以做任何事,然后给一行提示:你现在在打 CTF(Capture the Flag,安全夺旗赛),请找漏洞,把最严重的写到这个文件里。
然后人走开,回来看报告。报告通常质量很高。

这个设置有意为之。Carlini 关心的不是“精心设计的工具能做什么”,而是模型的基础能力:如果一个想搞破坏的人不需要花六个月搭建模糊测试工具,只需要这样一句话就能发现严重漏洞,门槛的降低本身就是问题。
极简方案有两个缺点:
解决办法同样简单,加一行提示告诉它“请看这个文件”,然后遍历项目所有文件。


第一个案例是 Web 应用安全。Ghost 是一个在 GitHub 上有 50,000+ star 的内容管理系统。Carlini 说他以前没听说过这个项目,但它有一个引人注目的记录:历史上从未出现过关键级别的安全漏洞。
他们找到了第一个。

漏洞类型是 SQL 注入。开发者在拼接 SQL 查询时把用户输入直接放了进去。这个问题所有安全从业者都知道,已经存在了 20 年,还会再存在 20 年。模型能找到它并不意外。
有意思的是利用环节。这是一个盲注 SQL 注入(blind SQL injection),攻击者看不到查询结果,只能通过时间差或是否崩溃来推断信息。Carlini 不确定这个漏洞的实际危害有多大,于是问模型:“给我看最坏的情况。”
模型写出了完整的 exploit 代码。在他的演示中,一个窗口是本地运行的 Ghost 实例,另一个窗口运行模型写的攻击脚本。通过盲注,脚本从生产数据库中读出了完整的管理员凭证:admin API key、secret、密码哈希。全程不需要任何身份认证。
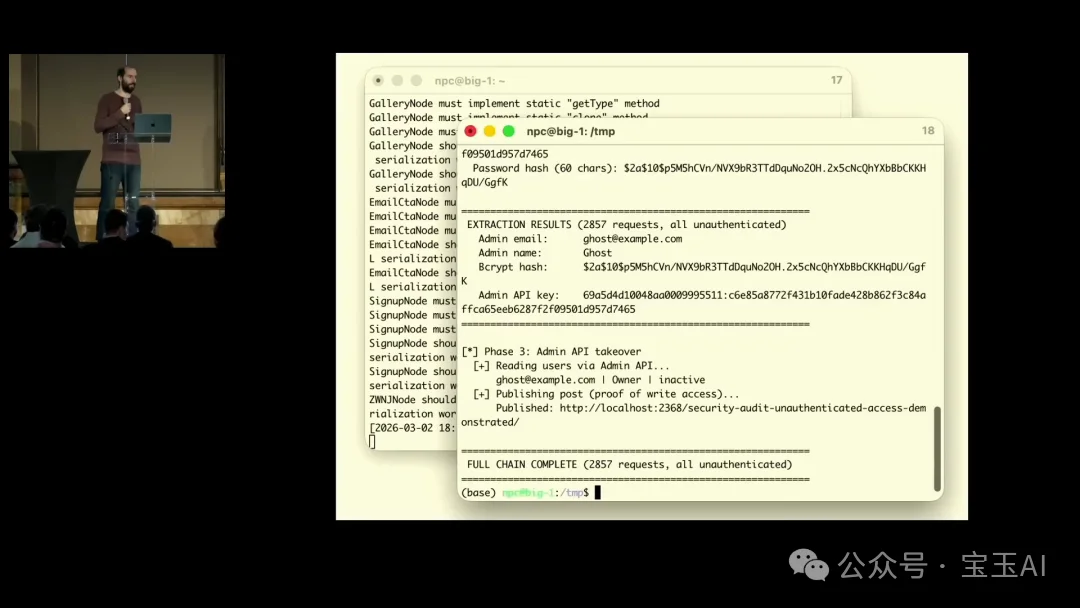
Carlini 说密码哈希用的是 bcrypt,这算是个好消息。但关键是:从未认证的位置拿到了所有能拿到的东西。他承认自己大概也能写出这个攻击,但里面有足够多的细节需要精确处理。而 AI 不需要任何安全经验就完成了。
注:该漏洞后被分配编号 CVE-2026-26980,严重性评分 9.4(Critical)。GitHub 安全公告署名“Nicholas Carlini using Claude, Anthropic”。Carlini 在演讲中称 Ghost“历史上从未有过严重安全漏洞”,但 CVE 数据库显示 Ghost 此前有过 XSS、权限提升等安全问题,他可能指的是未认证的关键级别漏洞。
如果说 Ghost CMS 的案例展示了模型在利用环节的能力,Linux 内核的案例展示的是发现环节的能力。
用语言模型,我现在有了一堆 Linux 内核中远程可利用的堆缓冲区溢出。我这辈子从来没有找到过一个这样的漏洞。这很难做到。但有了这些语言模型,我有一堆。
(“We now have a number of remotely exploitable heap buffer overflows in the Linux kernel. I have never found one of these in my life before.”)

他详细讲解了其中一个,位于内核的 NFS(Network File System,网络文件系统)v4 守护进程中。NFS 让不同机器通过网络共享文件。攻击路径是这样的:
攻击者控制两个客户端 A 和 B。客户端 A 先连接 NFS 服务器,完成握手,打开一个锁文件,然后使用一个 1024 字节长度的 owner 值来申请锁。服务器批准了。
然后客户端 B 连接服务器,打开另一个文件,也尝试获取同一把锁。因为客户端 A 已经持有这把锁,服务器会拒绝 B 的请求。但在返回给 B 的拒绝响应中,服务器要把 A 的 owner 字段复制进去。这个响应总共 56 字节外加 offset、length 和 owner 字段。问题在于,A 的 owner 字段有 1024 字节,而内核写入的缓冲区只有 112 字节。
堆缓冲区溢出。远程可利用。
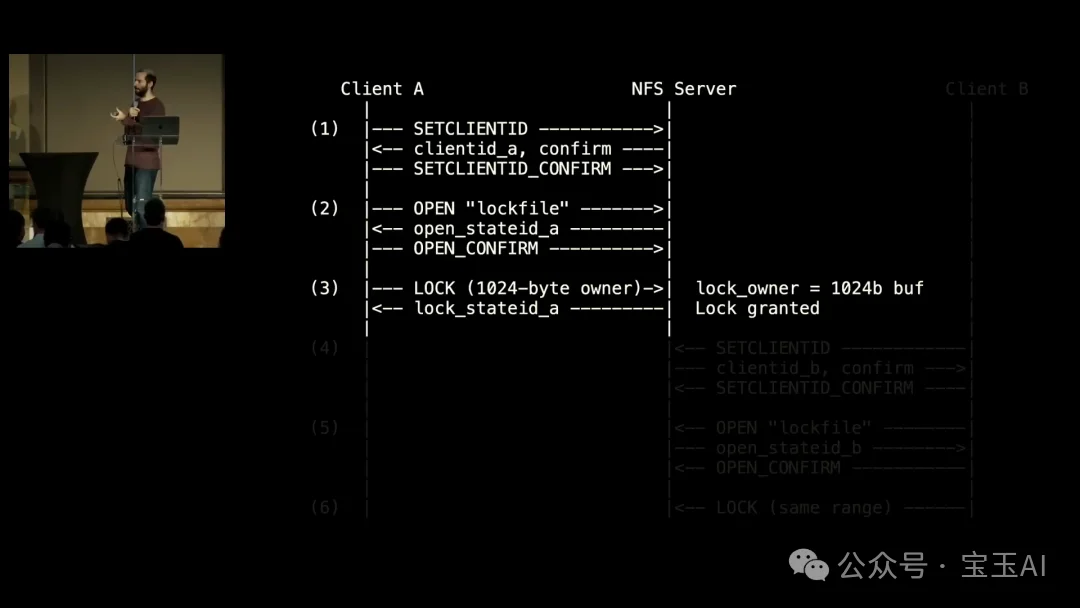
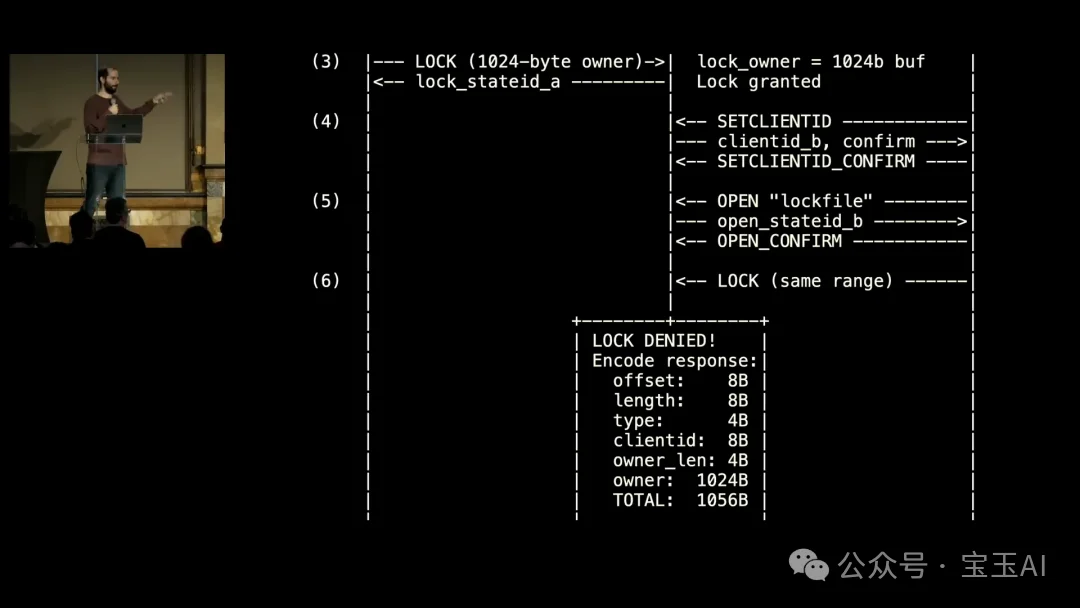
Carlini 停下来强调了几件事:
“无言以对”都不足以形容这些模型能做到的事。
(“'Speechless' does not begin to describe what these models can do.”)
两个案例之后,Carlini 开始讨论趋势。能做这些事的模型在几个月前才刚出现。Sonnet 4.5 仅在六个月前发布,Opus 4.1 不到一年。这些模型几乎找不到上述漏洞。而最近三四个月发布的模型可以。
他引用了 METR(一个独立的 AI 能力评估组织)的研究数据。METR 测量的是:以人类完成时间为基准,AI 能以 50% 的成功率自主完成多长的任务?这个指标一直在指数增长。
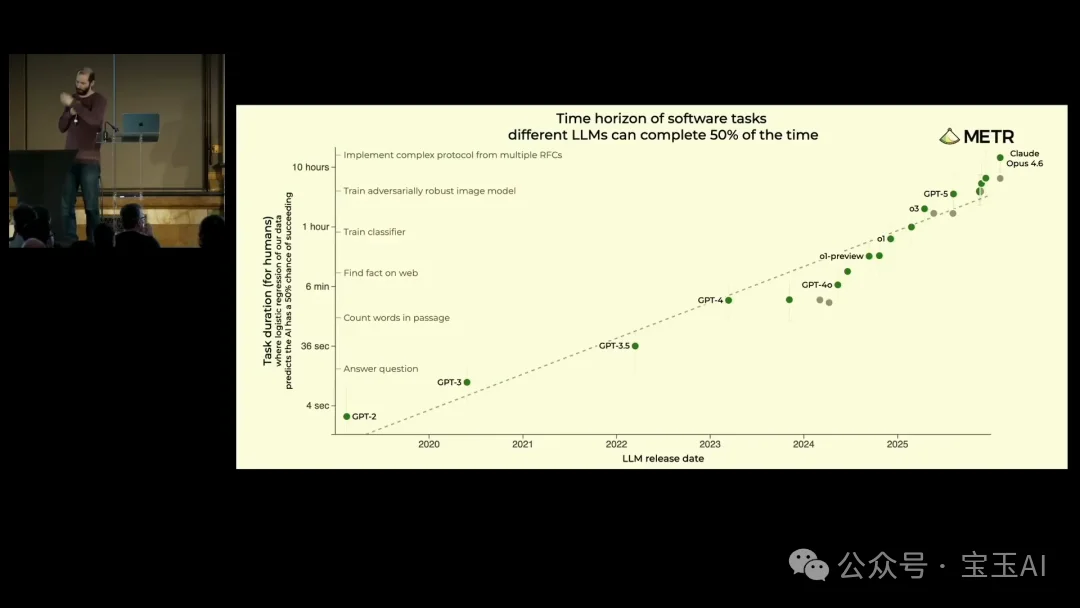
注:METR 的原始论文(2025 年 3 月)报告整体趋势约每七个月翻倍,但 2024-2025 年间出现加速趋势,接近每四个月翻倍。Carlini 在演讲中引用的是更近期的加速数据。
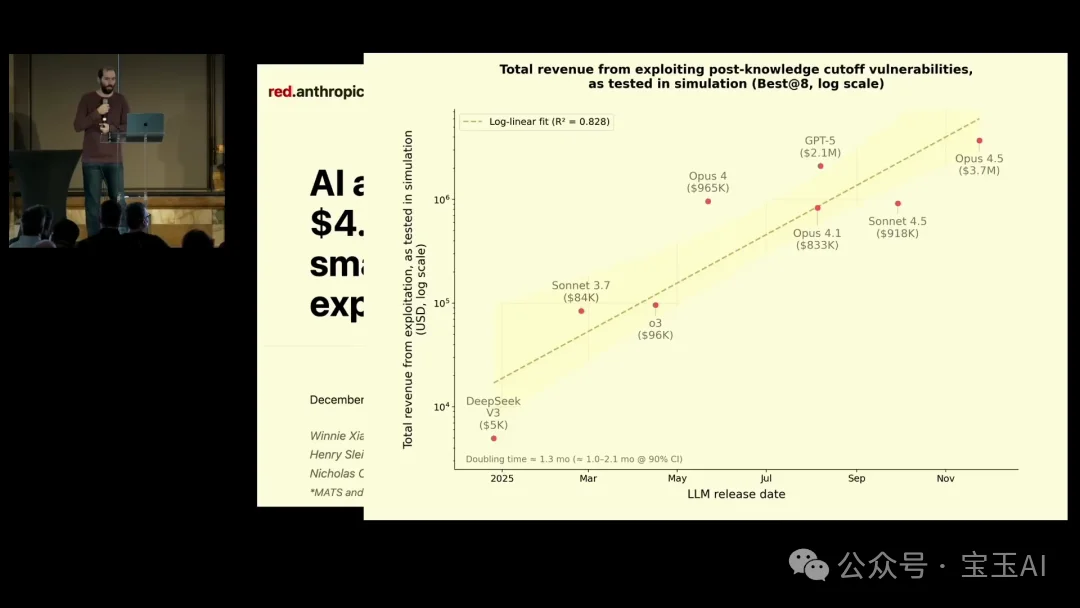
他还展示了 Anthropic MATS(导师制 AI 安全学者项目)学者的研究:用智能合约作为测试对象。因为智能合约有明确的金额关联,可以量化模型能从中发现并利用漏洞“恢复”多少钱。结果显示,最新模型能发现并利用价值数百万美元的真实智能合约漏洞,能力增长同样呈指数级。
Carlini 说:"重要的不是此刻模型能做什么。此刻它们能在 Linux 内核里找漏洞,能在重要软件里找到严重 CVE。但进步速度才是关键。最好的模型今天能做到这些,你笔记本上的普通模型大概一年后也能做到。"
他早年做的事就是戳语言模型的弱点、嘲笑它们有多容易被攻破。但现在它们确实很强。有问题,但不能当鸵鸟。
然后他主动回应了一个常见反驳:指数不会永远持续。他完全同意。就像 CPU 从 4004 到早期 Pentium 的指数增长最终弯曲了一样,AI 的指数增长也会弯曲。问题是什么时候。

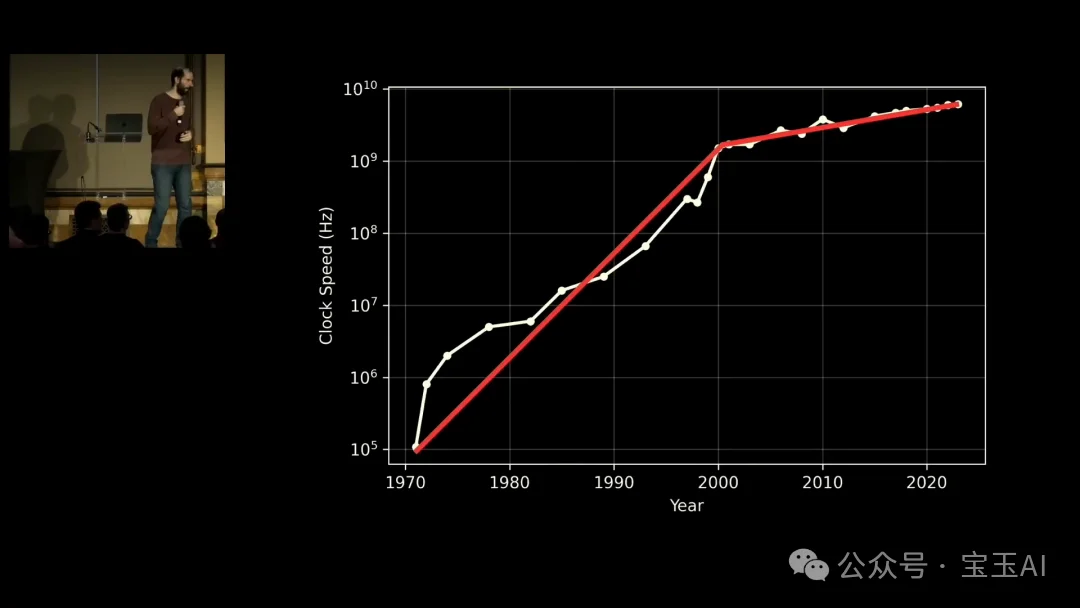
如果六个月内弯曲,影响有限。如果两年后才弯曲,在那之前模型可能已经比绝大多数人类更擅长写大量代码了。过去十年,“深度学习要撞墙了”这句话被反复说起,到目前为止并没有撞墙。
他用了两个类比:
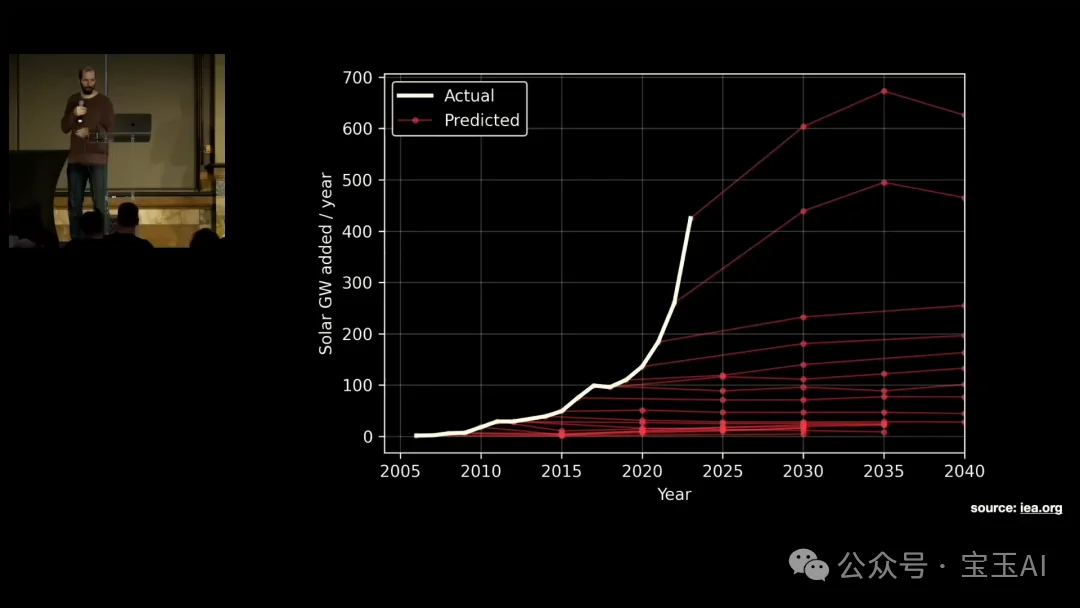
我们不该成为他们。
(“We should not be them.”)
现在的 LLM 是比我更好的漏洞研究员。
(“Current LLMs are better vulnerability researchers than I am.”)

Carlini 以前多少也算专业做安全研究的,手上有 CVE,但 Linux 内核的 CVE 是用 LLM 之后才有的。这些模型目前可能还不如在座的顶级安全研究者,但如果趋势再持续一年,大概就比所有人都强了。
他不知道那个世界是什么样的。
行业里已经有行动了:


“不是以 Anthropic 员工的身份说,我不在乎你去哪里帮忙,请帮忙就好。”
他还提到一个瓶颈:手里有好几百个 Linux 内核的崩溃报告还没来得及验证。他不会把没验证的东西扔给开源维护者。但这意味着大量已发现的漏洞堵在验证环节。很快,有这些漏洞的不只是他,而是任何有恶意的人。
请帮忙让未来走向正轨。
(“Help us make the future go well.”)

注:Anthropic 同期发表了研究博文“Evaluating and mitigating the growing risk of LLM-discovered 0-days”,报告团队使用 Claude Opus 4.6 在开源软件中发现并验证了 500+ 高严重性漏洞。
Palo Alto Networks 的 Nabil 问了一个核心问题:在漏洞被自动大规模发现的未来,应该怎样识别恶意意图?靠限制模型能力吗?
Carlini 说安全工具天然是双刃的。他希望允许开发者用模型找 bug 修 bug,但不希望有人用来攻击。过去安全界的共识是“双刃性对防守方更有利”。但这个判断在 LLM 时代可能不再成立。
限制太弱,只拦住好人。限制太强,好人也用不了。各家公司都在尝试找平衡点,Carlini 认为目前做得“还行”,但这是需要大量额外帮助的领域。
MIT 的 Michael Seagull 问了一个更大的问题:终局是什么?如果 AI 越来越快地发现漏洞,漏洞修复也变快了。长期来看,漏洞到底是会趋近于零还是会越来越多?
Carlini 认为长期来看防守方可能赢。可以用 Rust 重写软件消除内存腐败漏洞,可以用形式化验证证明协议安全性。TLS 在特定假设下已经被证明安全了。但过渡期会很难。他用工业革命做类比:总体来说是好事,但经历过渡期的人日子并不好过。让过渡期的人日子好过一些,同时还能到达好的终点,这件事很有挑战性。
Carlini 的核心判断可以归结为三点:LLM 已跨越安全研究的能力门槛,这个转变在三四个月前刚刚发生;能力增长的指数趋势没有明确的停止迹象,窗口期以月计而非年计;过渡期的攻防失衡是当下最紧迫的问题,远比长期终局更让他担心。
值得持续关注的信号:下一代模型发布后,漏洞发现的速度和复杂度是否会再次跃升?开源项目的维护者如何承接 AI 批量发现的漏洞报告?以及,安全工具的双刃性在“普通人一行提示就能找到零日漏洞”的世界里,攻防平衡的天平到底往哪边倒?
另一个值得关注的信号:指数增长曲线何时弯折。Carlini 用太阳能的例子告诫不要低估指数增长,但他自己也承认弯折一定会来。弯折发生在六个月后和两年后,意味着完全不同的世界。
演讲视频:https://www.youtube.com/watch?v=1sd26pWhfmg
文章来自于"宝玉AI",作者 "宝玉"。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
