# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
想让大模型重点关注提示词里的某句话可没那么容易。
在NLP领域,注意力引导(Attention Steering)是控制大语言模型(LLM)聚焦行为的核心技术之一,其中提示高亮(Prompt Highlighting),即让模型优先关注用户指定的关键文本是一项关键策略。
然而,现有方法因需要显式存储完整注意力矩阵,与FlashAttention等高效实现完全不兼容,带来了严重的延迟与显存瓶颈。
为了攻克这一难题,来自爱丁堡大学的Weixian (Waylon) Li联合华为英国研究所、伦敦玛丽女王大学以及RayNeo的合作者,提出了SEKA(Spectral Editing Key Amplification)及其自适应变体AdaSEKA。
该方法另辟蹊径,在注意力计算之前直接编辑Key向量,通过频谱分解学习“相关性子空间”来引导注意力分配,天然兼容FlashAttention,延迟开销几乎为零。目前,该项工作已被人工智能顶级会议ICLR 2026接收。

本文提出SEKA(Spectral Editing Key Amplification),其核心思想非常直观:与其在注意力计算之后去修改注意力矩阵,不如在计算之前直接编辑Key向量,从源头引导注意力的分配。
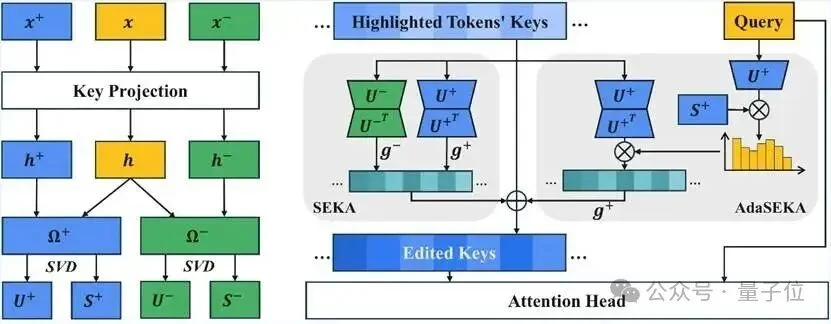
△ SEKA和AdaSEKA方法概览
SEKA通过频谱分解学习相关性子空间,在注意力计算之前编辑Key向量;AdaSEKA进一步利用Query向量动态组合多个专家投影。
具体而言,SEKA分为离线学习和在线推理两个阶段:
离线阶段:通过构造对比提示对(正向/负向/中性),提取不同条件下的Key嵌入,并利用奇异值分解(SVD)学习一个“相关性子空间”。这个子空间捕捉了当某些token与问题相关时,Key向量中最显著的变化方向。
在线推理阶段:对需要高亮的token,将其Key向量沿着学到的相关性子空间进行投影和放大,公式简洁优雅:k’ = k + g·P·k,其中P是投影矩阵,g是增益系数。
这一操作在数学上等价于为注意力分数添加了一个低秩偏置项,但因为它完全作用于Key嵌入层面,所以天然兼容FlashAttention等高效实现,无需访问或存储注意力矩阵。
SEKA的一个关键设计是:并非对所有KV头施加引导,而是只选择那些对“相关性”敏感的头。

△ Qwen3-8B各层各KV头的正负Key嵌入ℓ₂距离热力图
绿色区域集中在中后层,说明“检索”主要分布在这些层,也是SEKA选择性施加引导的依据。
上图展示了Qwen3-8B所有层和KV头的相关性敏感度。绿色区域(高ℓ₂距离)集中在中后层的特定头上,与近期机制分析中发现的“检索头”分布高度吻合。SEKA正是利用这一发现,仅对这些敏感的KV头施加引导,避免干扰其他功能头——消融实验也证实,去掉这一筛选机制会导致性能大幅下降。
标准SEKA的投影矩阵是固定的,面对不同类型的任务可能需要手动调参。为此,本文进一步提出了AdaSEKA(Adaptive SEKA),引入多专家路由机制:
这一机制无需任何额外训练,计算代价极低,同时显著降低了超参数调优的负担。新的专家可以随时模块化地加入,无需重新计算已有专家。
本文在CounterFact(知识冲突)、Bias in Bios(职业提取)、Pronoun Changing(指令遵循)等标准基准上,使用Qwen3(4B/8B/14B)和Gemma3(4B/12B)进行了全面实验。
下表展示了各方法在不同模型上的表现:
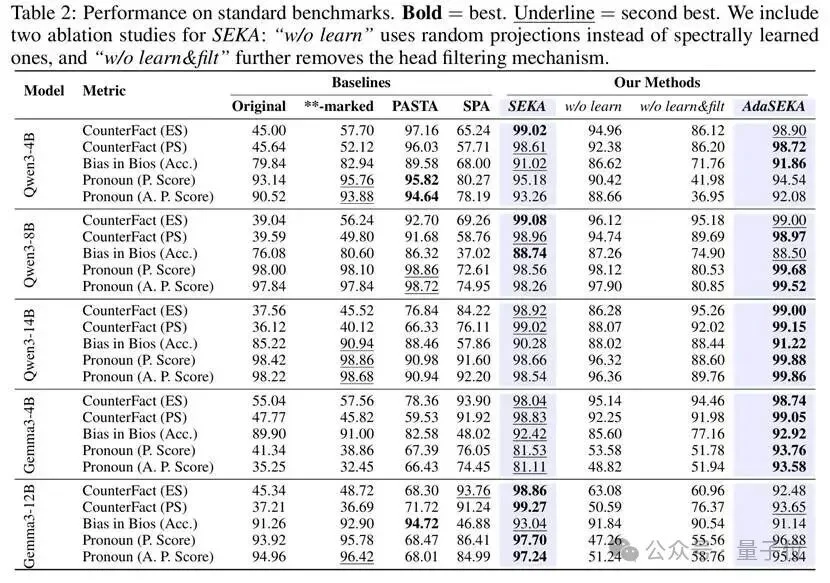
SEKA和AdaSEKA在绝大多数设定下排名前二,在CounterFact上将准确率从30-50%提升至接近99%。
效率对比同样亮眼:
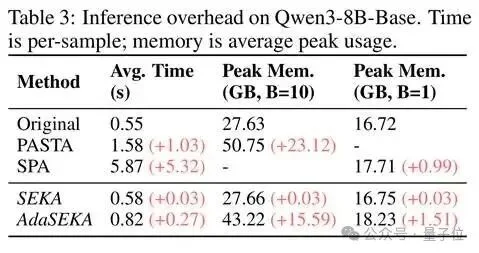
SEKA每个样本仅增加0.03秒延迟和0.03 GB显存,效率优势达到PASTA的数十倍,且完全兼容FlashAttention。
SEKA的意义不仅在于一个更高效的注意力引导方法,更在于它揭示了一个重要的发现:大模型的Key嵌入中存在结构化的“相关性子空间”,可以通过简单的频谱分解来发现和利用。
这一发现为理解和控制Transformer的注意力机制提供了新的视角,也为构建更加可控、高效的大语言模型系统打开了新的思路。在长上下文应用日益普及的今天,一个既高效又有效的注意力引导框架具有重要的实用价值。
论文标题:
Spectral Attention Steering for Prompt Highlighting
论文链接:
https://arxiv.org/abs/2603.01281
代码:
https://github.com/waylonli/SEKA
文章来自于"量子位",作者 "SEKA团队"。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
