# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Hongyuan Adam Lu,FaceMind CEO,CUHK AI PhD 研究课题:LLM 预训练、世界模型、端侧模型训练;帝国理工 CS 本硕;爱丁堡大学 AI 硕士;ACL 系顶会 Outstanding Paper Award 一作;曾于 MSRA(北京)任预训练一职,研发了世界上第一个支持 200 种语言的 LLM;旗舰会议 ACL 2025、NAACL 2025 Area Chair,创办了 AI 软件:叠叠社,深受二次元喜爱,是一款被投资人称之为 “米哈游的蔡浩宇都要学习的 AI 产品”。
有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
深挖这个现象,是一个有趣、有用、但 “反直觉” 的问题:如果语义不变,只是把一句话改写成更常见、更高频的 “大白话”,模型的推理以及训练表现会不会更好?
最近,来自脸谱心智与香港中文大学的科研人员围绕这个问题展开了系统研究,并提出了一项中稿 ACL 2026 Main 的新工作。他们提出了一个极具记忆点的新概念:Adam’s Law,aka Textual Frequency Law(文本频率定律)。

论文用理论推导以及模型实验向我们展示了:当不同表述表达同一个意思时,语言模型往往更偏好 “高频文本”。而这种偏好不仅出现在你敲下 Prompt 的那一刻,甚至在模型训练阶段也同样适用。
用大白话说,很多时候决定模型是否聪明的,不只是 “你问了啥”,还包括 “你是怎么说的”。
这启发了什么?今天我们业内谈起模型优化,关键词永远是:更强更大的基座、更长的推理思维链、以及昂贵的高质量训练数据,或者是极其复杂的 alignment 算法。但 Adam's Law 揭示了文本频率对于模型训练以及推理的重要性。
研究表明,高频表达因为在训练语料中出现的次数足够多,大模型对它们有着天然的 “肌肉记忆”。因此,在面对这些模型自身熟悉的词句时,模型在理解、推理和生成时更容易零百 “进入状态”。
Adam’s Law 主张的铁律是:我们应该优先使用句子级频率更高的 expression,无论是做 inference 还是 training。
研究团队不甘让结论停留在 “哎哟,好像确实是这样” 的 empirical observation。
他们先是提供了缜密的 theoratical proof,也为其搭建了一个完整的 framework,由三板斧组成:

极其硬核的部分推导数学辅佐
用大白话来说,他们的操作流程是这样的: 先给一句话算算 “八字”(估算常见度),把同义句里最接地气、最 frequent 的那句挑出来喂给模型;如果怕算得不准,就让模型自己做几道 “故事续写” 题,看看它平时潜意识里爱用什么词,借此来修正频率估算;最后,在训练时,不光是要挑数据频率,而且训练顺序都给你安排得明明白白。
这里有一个大坑:像是 GLM 这种主流大模型,预训练数据全是个黑箱,连它吃过几碗干饭都不知道,你怎么算它对哪句话更眼熟?不用担心没关系。
作者给了个极其巧妙且工程化的解:咱不纠结模型见过啥,直接借助公开的庞大 corpora 和词频资源去估算就行。 在 Adam’s Law 中,句子的频率被近似为词频的组合,直接攒出一个 “句子级频率指标”。
这意味着,开发人员完全不需要破解闭源模型的训练集,就能直接用这套频率估算大法。极其接地气,绕开了黑箱限制,把玄学推进到了可验证、可复现的工程层面。
当然,仅靠公开词频估计大概率是有误差的。Adam 打出了第二把斧 TFD:让目标模型对给定文本做 “story completion 续写补全”。这相当于在审问模型:“别装了,暴露你的真实用语习惯吧!” 用模型自己吐出来的语料蒸馏,再去辅助修正原始频率,这样就无限逼近了模型内部真正熟悉的白话表达分布。
Adam's Law 最绝的一点,是没有把 “文本频率” 局限在一个讨巧的 Prompt 推理技巧上,而是直接杀到了更硬核的模型训练范式里。
在提示(Inference)阶段,逻辑非常顺滑:同一道数学题,如果把题目里的生僻词换成大白话的高频表达,模型马上就算得更准。
但在训练(Training)阶段,Adam 抛出了一个灵魂拷问:如果老板给的算力预算有限,训练数据该怎么挑怎么用?Adam 说:高频文本可能比低频文本更值得优先保留!
而且 CTFT 甚至改变了喂数据的姿势。作者发现,低频表达往往语境更稀疏、结构更复杂。就像我们上语文课一样,先让他死磕难懂的古文(更低频),再让他看通俗的白话文(更高频),最终的收敛效果,居然比随机乱喂数据还要好。
为了拿数据说话,作者死磕出了一个专门的数据集 TFPD(Textual Frequency Paired Dataset),涵盖了数学推理、机器翻译、常识推理和智能体工具调用等多个场景。
为了保证严谨,他们先用模型生成一批 “文绉绉、极其少见” 的改写,和一批 “大白话、极其常见” 的改写,再花钱请人工标注员挨个检查,确保改写后意思没变,最后凑成了 “高频 vs 低频” 的成对样本。
结果极其直观。
在数学推理、Agent 任务、以及常识解析上,仅仅只是把 Prompt 换成更高频的表达,不换模型、不加训练数据、不增加 inference 时长,inference 效果显著增加;在机器翻译上,Adam's Law 同样稳如泰山:研究人员一口气测了 100 个语言翻译方向:在训练实验里,三板斧 CTFT 的威力同样显现。在 Pangasinan(一种菲律宾语支)的机器翻译任务中,使用了 CTFT 后, BLEU 分数狂涨 29.96%。
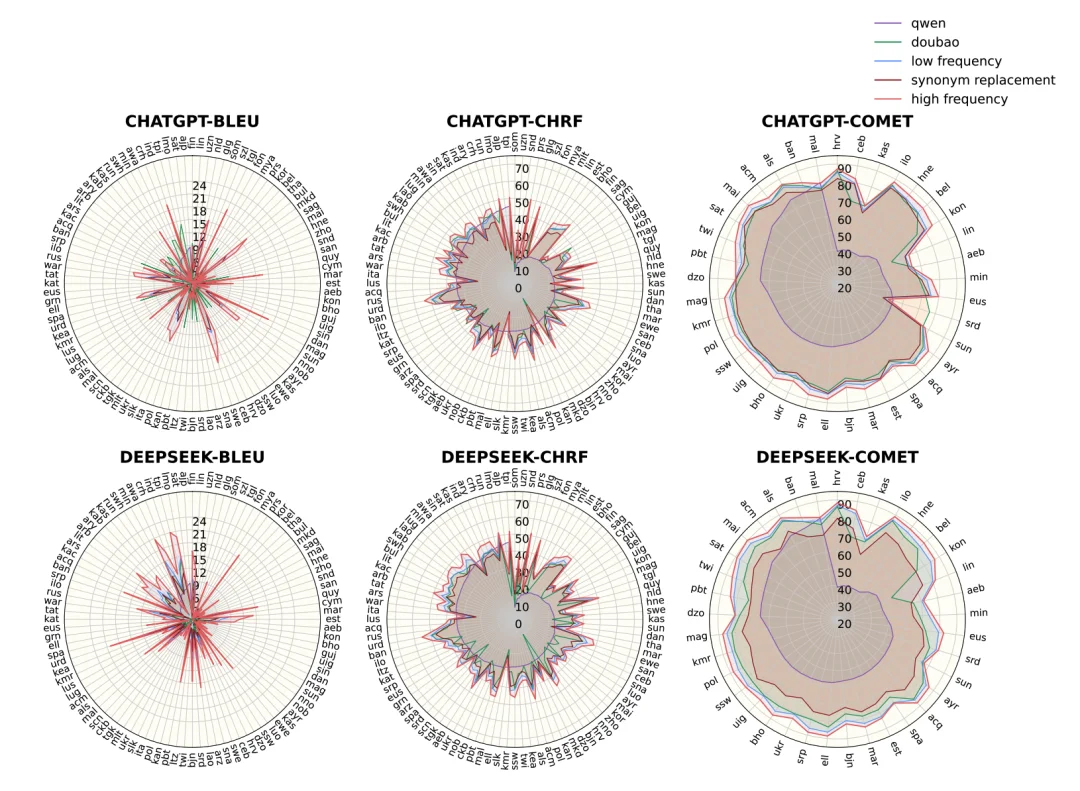
Adam's Law 在上百种语言上的结果可视化,最外圈为 Adam's Law 的结果。
更颠覆认知的是:有时候用高频改写数据去训练,效果甚至比直接用原汁原味的基准 training set 还要好!这直接挑战了业内 “原始数据天然最优” 的传统偏见。
Adam’s Law 把一种飘渺的 “直觉”,打造成了一套可定义、可估算、可验证、可部署、绕过黑盒的方法学定律,通过数学推导以及实验的方法证明了其可靠性。
对搞应用(做 Agent、写 Prompt)的打工人: 别再给 Prompt 疯狂加毫无必要的定语、约束和高端词汇了。先把 Prompt 理顺,改得更自然、更高频,这可能是一种几乎没有成本、见效极快的 “魔法”。
对搞训练(Pre-training、SFT、蒸馏、做数据清洗)的炼丹师: 这是全新的 Data Engineering 治理思路。以后洗数据做数据,除了看数据的质量、长度、难度,咱还得给文本频率拉个画像。GPUTPU 吃紧时,“留什么数据” 不只看标注对不对,咱还得看看这句话是不是足够 “大白话”。
对评测(Benchmark)的研究者:如果一道题,换个冷门说法模型就不行,那它是真的有了 “推理能力”,还是仅仅靠着 “刷题”,记住了特定表述的熟悉度?这给未来构建更抗造的评测榜单提了个醒。
Adam’s Law 像一面镜子,照出了 LLM 的本质:模型不仅在 “理解世界”,它更是在 “记住人类语言世界里,什么东西最常出现”,然而这是双向的,LLM 在看世界的时候,世界也在看 LLM。
当整个 AI 圈都在为了更长的 RL 推理、更庞大的参数量、更玄乎的对齐算法无脑卷生卷死时,这篇工作轻巧地给出了一条无比朴素的线索:
让模型变聪明的捷径,不是把话说得更高深,而是把话说得更大白话一点。这在推理时有用,也在训练时有用。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
