# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026年春季,大模型行业的高烧似乎正在退去,取而代之的是一种近乎冷酷的理性。近日,《财经》报道指出,全球企业级 AI 应用中,约50%的Token正在被浪费。
浪费的原因很具体,AI应用从“对话”转向“执行”,这些计算资源流向了较贵的大型旗舰模型,Agent在复杂多轮任务中,历史文件、对话会不断累积,大量无用、冗余、过期的信息会不断产生并且重复计算,Token消耗因此指数级增长。也就是说,企业和开发者在用最贵的车跑最短的路。
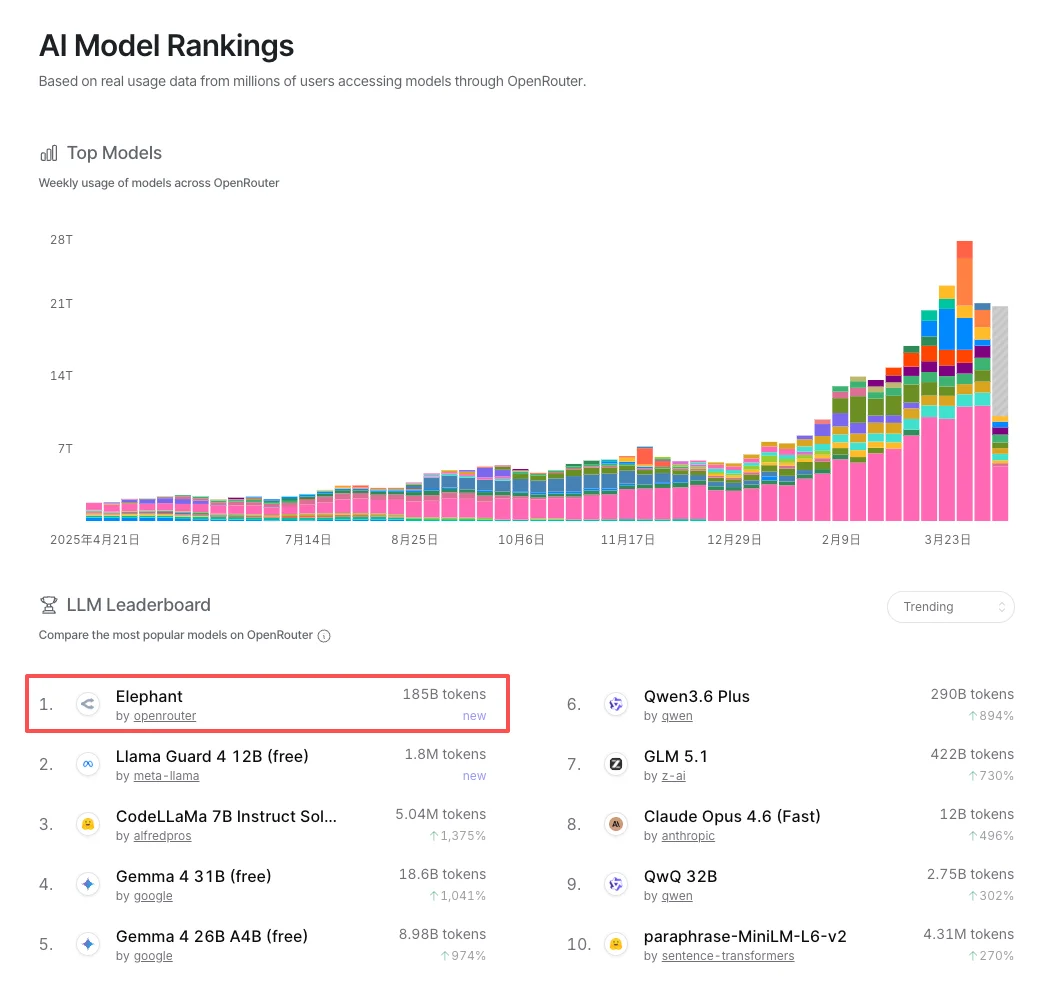
OpenRouter的流量数据反映了这个转变:过去一个季度,旗舰级模型的调用占比在下降,100B–300B区间的模型调用量则明显上升。以近日上线的100B 模型Elephant为例,单日流量暴涨500%,冲上热榜榜首,成为OpenClaw等 Agent 最受欢迎的选型。开发者开始按任务类型分配模型,而不是一律用最顶配。这是工程理性回归的信号,不是对旗舰模型的否定。
为什么现在才开始算这笔账
几年前,"选最强的模型"是最省心的工程决策。旗舰模型几乎在所有任务上都更好,成本问题还没到逼人重新设计架构的程度。
现在情况变了,Agent需要“执行”大量工作。一个客服Agent处理一张工单,可能需要调用模型十几次:理解意图、查询知识库、判断优先级、生成回复、核查格式。如果同时有几千张工单在处理,每天的调用量轻松进入百万级别。在这种频率下,每次调用多付的溢价开始在账单上显现。
今年3月,一位名为shelvenzhou的开发者在Github进行了一项基准测试,引发了广泛讨论。他记录自己的OpenClaw日常工作(包括代码、邮件、PDF、图片、搜索等)Token消耗情况——第一轮对话Token成本0.0050美元;第五轮对话Token成本0.0665美元,是第一轮的13.3倍;第10轮的Token成本达到了0.13美元,是第一轮的26倍。
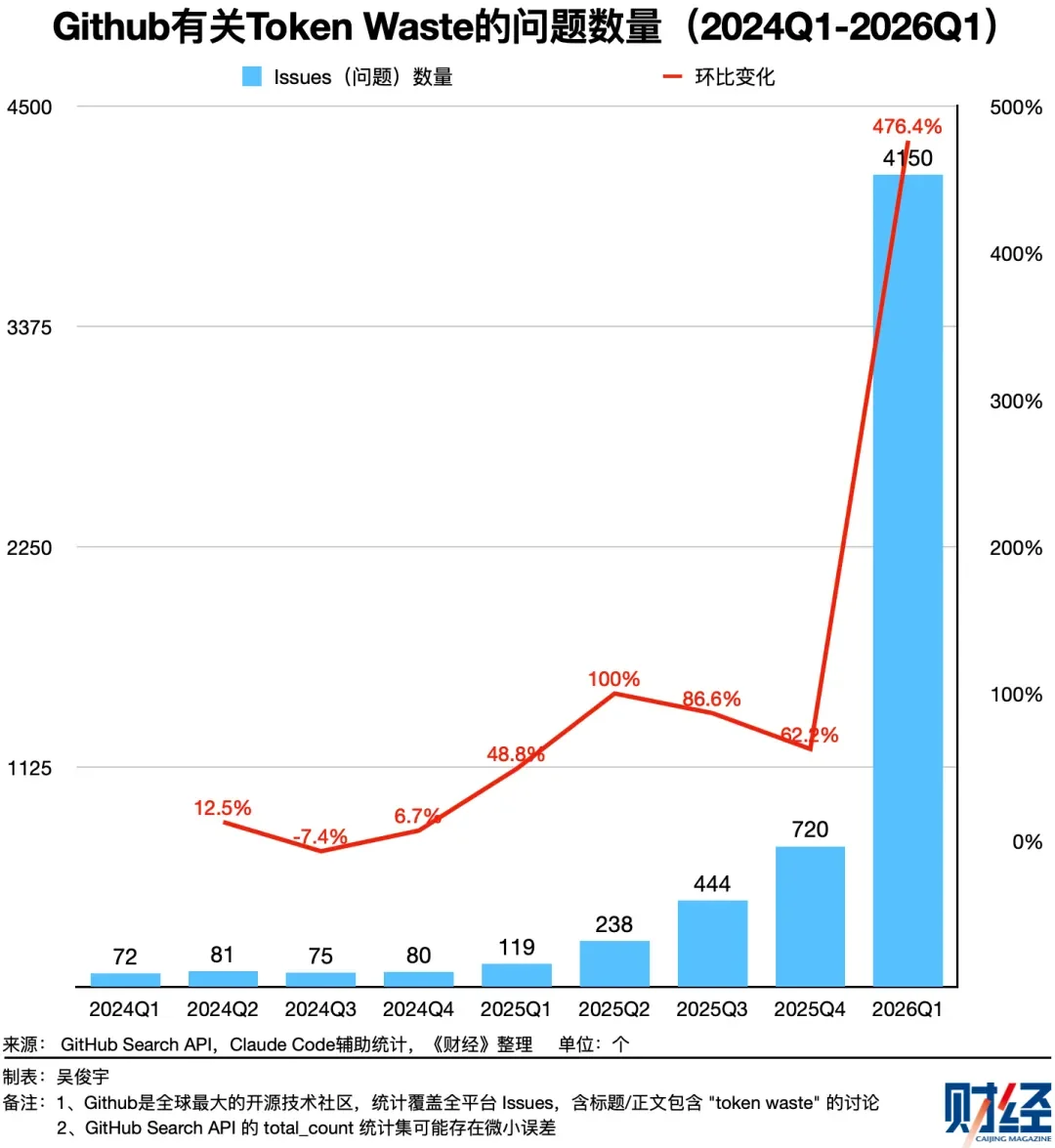
根据报道,《财经》统计了GitHub上有关“Token Waste”相关Issues的数量。这一讨论至少有5200个,仅2026年一季度就诞生了4150个。越来越多的开发者在实际业务中正面临控制Token浪费的问题。
目前大多数Agent的工程实现还相当粗糙。面对Agent的多步任务,Token消耗以接近线性的速度增长,而其中大量内容对当前步骤毫无意义。这类问题催生了一个新的工程概念——Agent Harness,它不是模型本身,而是包裹在模型外部、负责管理上下文、编排工具调用、控制执行生命周期的“缰绳”和“马具”。
Token 效率因此形成了两条并行的压力线,一条来自 Agent 框架侧,Harness 的出现就是典型代表;另一条来自模型侧,推动厂商用更精简的参数完成同等质量的推理。
模型,向实用主义靠拢
在这场范式转移中,一批深耕“token效率”的模型成为了舞台中央的主角。它们不比拼参数规模,而是在单位Token成本下,比拼推理速度、指令遵循度以及长上下文的稳定性。
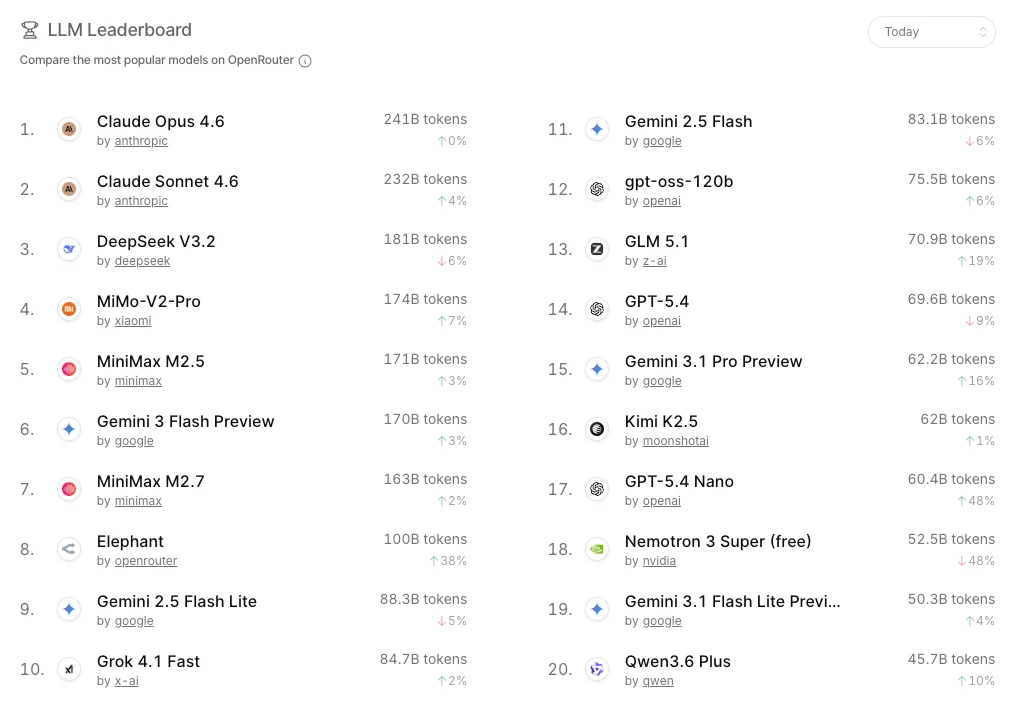
根据OpenRouter 的 LLM Leaderboard在4月16日的数据,模型格局呈现出明显的“大模型控榜,小模型控场”的分化态势。
在前20名的榜单中,传统意义上的大尺寸旗舰模型(如Claude Opus 4.6、DeepSeek V3.2等),主要分布在榜单头部和中上部,依然掌握着复杂任务的话语权;而主打轻量化、高性价比的小尺寸模型(如Gemini 3 Flash、Grok 4.1 Fast、GPT-5.4 Nano等),且多集中在第 8 名至第 20 名的区间,形成了不可忽视的“腰部力量”。
可以明显看到,小尺寸模型的涨幅惊人。根据4月16日数据,排名第17位的 GPT-5.4 Nano以48%的惊人涨幅领跑增长榜,100B模型Elephant单日涨幅 38%。
从App使用情况来看,OpenClaw、Hermes Agent、Kilo Code、CLaude Code 等成为这些小尺寸模型的“最大流量贡献”,开发者正在将小尺寸模型作为高频、低延迟任务的首选。
在业界看来,100B-300B已然成为一个实用主义区间。GPT-5.4-Mini是目前这条路线的典型代表之一,以更低延迟和更低成本大幅缩小与旗舰模型的性能差距。
OpenAI 此前着重强调了新模型在多模型分层系统中的位置:以其自研编程助手Codex为例,GPT-5.4负责规划、协调与最终判断,而GPT-5.4 mini子智能体则并行处理代码库检索、大文件审阅及辅助文档处理等粒度更细的子任务。
OpenAI表示,随着小型模型速度更快、功能更强大,开发者无需使用单一模型处理所有任务,而是可以构建系统,由大型模型负责决策,小型模型则快速大规模地执行任务。这种分层调用的模式开始变得实用而非将就。
Elephant Alpha是另一个值得关注的案例,该模型于4月13日深夜上线 Openrouter。同为100B参数,Elephant定位为“智能效率”优先,在保持256K 上下文窗口的同时,重点优化Token使用效率,适合代码补全、快速文档处理和轻量Agent交互等场景。由于来源匿名,其具体技术细节尚不透明,但在开发者社区已有相当的实测关注。
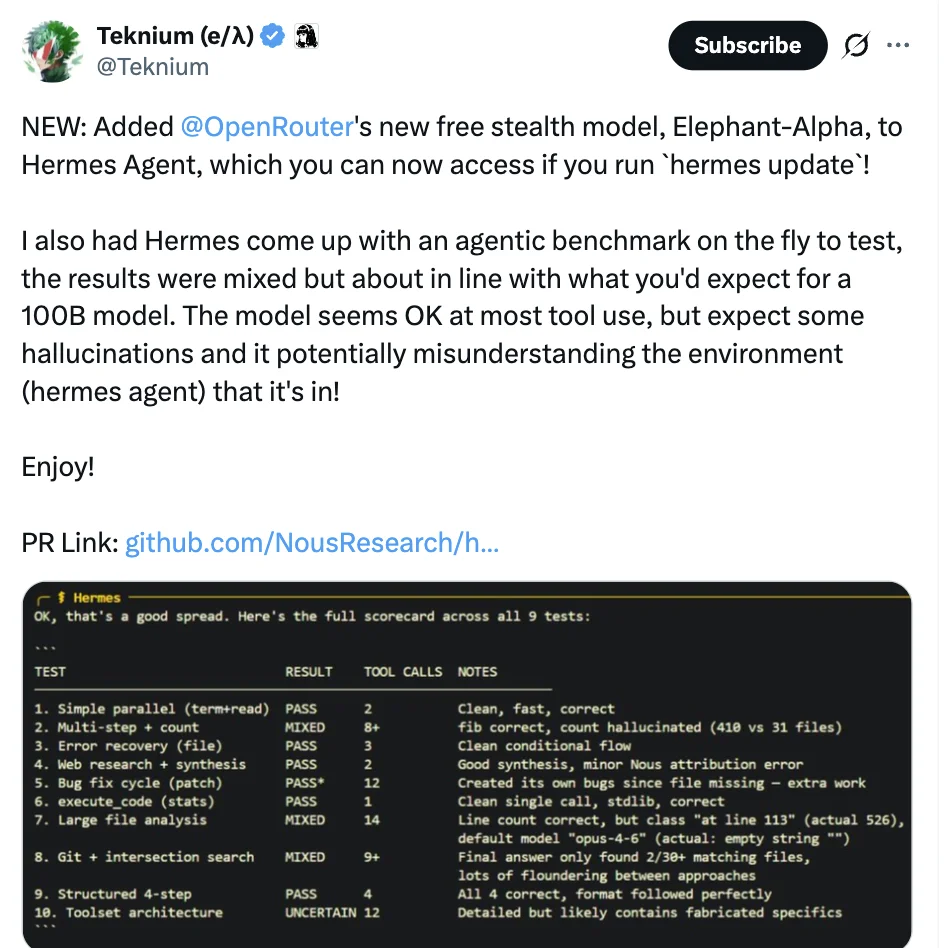
效率不是降级,是分工
旗舰模型不会消失。在需要跨领域深度推理、多步骤规划、复杂代码生成的任务上,它们仍然是必要的。没有人认真地认为100B模型可以在所有场景下替代旗舰版。
但在日常的业务执行层——那些占据大多数调用量的任务——用旗舰模型是在为不需要的能力付费。把这部分流量迁移到效率更高的模型上,毫无疑问是更具性价比的决策。
这种分工在软件工程里有先例。CPU发展从追求单核主频转向多核协作,不是因为单核不重要,而是因为在实际工作负载下,多核架构的整体吞吐远超单纯堆主频。数据库领域也有类似的演变:OLTP和OLAP长期共存,不同的查询特征对应不同的存储和计算架构。
模型选型的逻辑正在经历类似的成熟。Token效率正在成为工程师评估模型的核心维度之一——不是因为便宜,而是因为在高频调用的场景下,它直接关系到产品的商业可行性。那些在单位成本下能提供足够推理质量的模型,正在成为 Agentic应用的默认底座。
一条路线日渐清晰:规模继续重要,但效率开始定价......
文章来自于微信公众号 "华尔街见闻",作者 "华尔街见闻"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
