# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
图结构学习(Graph Structure Learning, GSL)旨在通过生成新的图结构来捕捉图结构数据中节点之间的内在依赖性和交互关系。
图神经网络(Graph Neural Networks, GNNs)作为一种有前景的GSL解决方案,通过递归消息传递来编码节点间的相互依赖性。然而,许多现有的GSL方法过度依赖于作为监督信号的显式图结构信息,使它们容易受到数据噪声和稀疏性的挑战。
在这项工作中,研究人员提出了GraphEdit方法,该方法利用大型语言模型(Large Language Models, LLMs)来学习图形结构数据中复杂的节点关系。

论文链接:https://arxiv.org/abs/2402.15183
代码链接:https://github.com/HKUDS/GraphEdit
通过对大型语言模型进行图结构指令调优以增强其推理能力,旨在克服显式图结构信息相关的限制,并提高图结构学习的可靠性。
该方法不仅有效地去除了噪声连接,还从全局视角识别了节点间的依赖关系,为图结构提供了全面的理解。我们在多个基准数据集上进行了广泛的实验,以证明GraphEdit在不同设置下的有效性和鲁棒性。
图结构学习(GSL)是一个新兴的研究领域,致力于揭示图形结构数据内部的模式和关系。GSL的核心目标是发现原始数据中不易察觉的潜在关系和依赖性。通过生成这些新颖的图结构,GSL帮助我们更全面地理解数据,从而支持各种下游任务,比如节点分类。
近年来,图神经网络(GNNs)因其在模拟和利用图形结构数据中的关系方面的出色能力而受到极大关注。GNNs通过有效地聚合和传播图中邻近节点的信息,擅长学习节点级表示。这种能力为图形结构数据的分析带来了一场革命,使我们能够更全面地理解节点间的连接模式和交互。
尽管图神经网络在许多方面表现出色,但许多方法在学习准确表示时过度依赖显式图结构(如节点链接)作为监督信号。然而,现实世界中的图数据经常面临数据噪声和稀疏性的挑战,这可能影响显式图结构的可靠性。
例如,在社交网络数据集中,由于隐私设置或数据可用性有限,某些链接可能缺失或不完整。在推荐系统中,用户-物品互动图可能涉及冷启动用户或物品,导致链接高度稀疏。此外,推荐系统中存在的各种偏见也会向数据中引入噪声。
在这些情况下,仅依赖显式图结构作为监督信号可能导致表示不准确或有偏。这些挑战需要开发更加健壮的图结构学习框架,以适应并克服图形结构数据中数据不完美的影响。
面对前文提出的挑战,本研究旨在探索大型语言模型(LLMs)如何有助于推理图形结构的底层逻辑。我们介绍了我们提出的模型,GraphEdit,该模型旨在有效地优化图结构。
我们的模型有两个目标:首先,识别并处理不相关节点之间的噪声连接;其次,揭示隐性的节点间依赖关系。为了实现这些目标,我们的模型利用了与图形结构数据中的节点相关的丰富文本数据。通过结合LLMs的文本理解能力,特别是通过指令调优范式,我们增强了对图结构的理解和表示。这使我们能够捕捉到可能在图结构本身中没有明确编码的个别节点之间的隐性依赖关系。
这一部分我们将详细阐述GraphEdit的技术细节,模型整体框架图如图1所示:
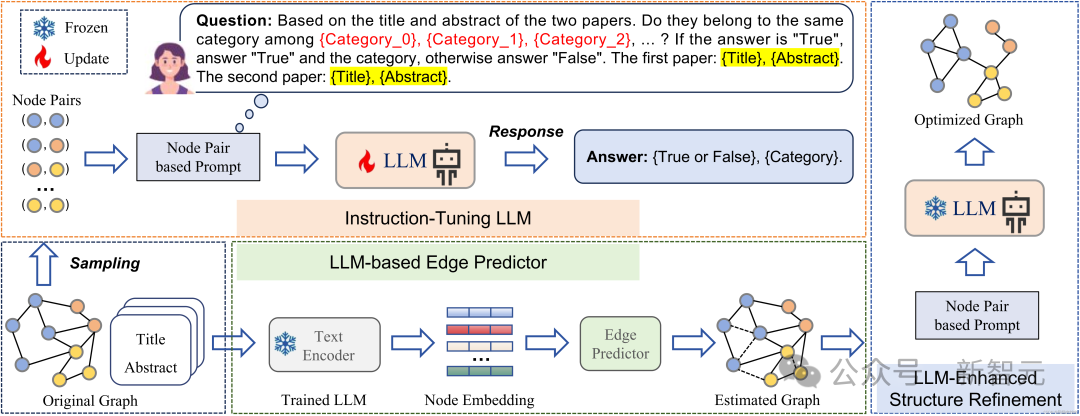
基于同质性假设,即具有相似属性的节点倾向于形成更强的连接。这一概念进一步发展为基于节点连接模式探索节点间标签一致性。具体来说,在依赖图结构的节点分类任务中,理想情况是最大化同一类别内的连接,同时最小化类别间的连接。
在这一原则的指导下,我们的方法旨在利用LLMs的知识来推理节点间的潜在依赖性,同时考虑到与个别节点相关的文本语义。
Q: Based on the title and abstract of the two paper nodes. Do they belong to the same category among {Category_0}, {Category_1}, {Category_2}, ... ? If the answer is "True", answer "True" and the category, otherwise answer "False". The first paper: {Title}, {Abstract}. The second paper: {Title}, {Abstract}. A: {True or False}, {Category}.
在提示创建阶段,我们定义了每个提示中的两个独立目标。第一个目标是评估节点对的标签一致性。它使语言模型能够准确把握所需的图结构。基于标签一致性的第二个目标是确定这些节点属于哪个特定类别。这两个目标,为语言模型的指令微调提供了宝贵资料。
为了进一步增强我们的分析,除了原始图结构外,还需要识别潜在候选边。然而,直接使用训练好的LLM遍历并推理整个图表面临计算挑战,尤其是对于大型图,因为其复杂度为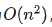 ,其中代表图中节点的数量。随着图大小的增加,这种计算复杂性变得不切实际。为了克服这个挑战,我们提出引入一个轻量级边预测器,以协助LLM在图
,其中代表图中节点的数量。随着图大小的增加,这种计算复杂性变得不切实际。为了克服这个挑战,我们提出引入一个轻量级边预测器,以协助LLM在图 中节点间选择候选边。
中节点间选择候选边。
为确保语义一致性,我们使用从训练好的LLM得到的每个节点的表示。
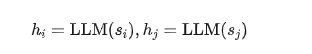
我们使用符号$来表示一对节点。与节点i和j相关文本属性分由s_i和s_j表示。到的表示h_i和h_j$分别对应于它们各自的节点,并保留了从大型语言模型转移来的语义知识和推理力。
在获取节点表示后,我们根据节点标签采用以下程序构建训练集标签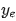 :
:
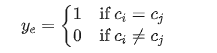
接下来,我们将每对节点中的两个节点表示连接起来。然后,我们将连接后的表示输入到一个预测层,表示为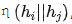 ,这使我们能够获得边存在的概率。我们用交叉熵作为损失函数:
,这使我们能够获得边存在的概率。我们用交叉熵作为损失函数:
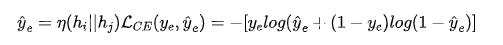
代表真实值,代表边存在的估计可能性。
Q: Based on the title and abstract of the two paper nodes. Do they belong to the same category among {Category_0}, {Category_1}, {Category_2}, ... ? If the answer is "True", answer "True" and the category, otherwise answer "False". The first paper: {Title}, {Abstract}. The second paper: {Title}, {Abstract}.
为了优化图结构,我们利用之前训练的边预测器,根据边存在的估计可能性,为每个节点识别出前k个候选边。这些候选边以及图的原始边随后通过提示提交给LLM进行评估。LLM利用这些信息来决定哪些边应该被纳入最终的图结构中。图结构优化过程可以总结如下:
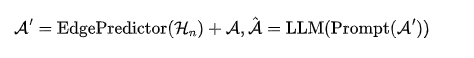
通过将边预测器的输出与原始邻接矩阵结合得到更新后的邻接矩阵,表示为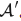 。这一融合过程将边预测器的预测纳入现有图结构中。
。这一融合过程将边预测器的预测纳入现有图结构中。
随后,通过LLM对应用于的提示的评估,生成了优化后的邻接矩阵Â。LLM利用其推理能力,就最终图结构中边的添加和删除做出决策。因此,优化后的邻接矩阵Â
代表了LLM的选择,包括边的添加和删除。这个优化后的邻接矩阵作为下游图任务(例如,节点分类)的输入。
总之,我们的框架通过结合边预测器的预测并利用LLM的推理能力,提高了最终图的质量和结构。这包括隐性全局节点间依赖性的揭示和噪声连接的去噪,从而改善了图表示。
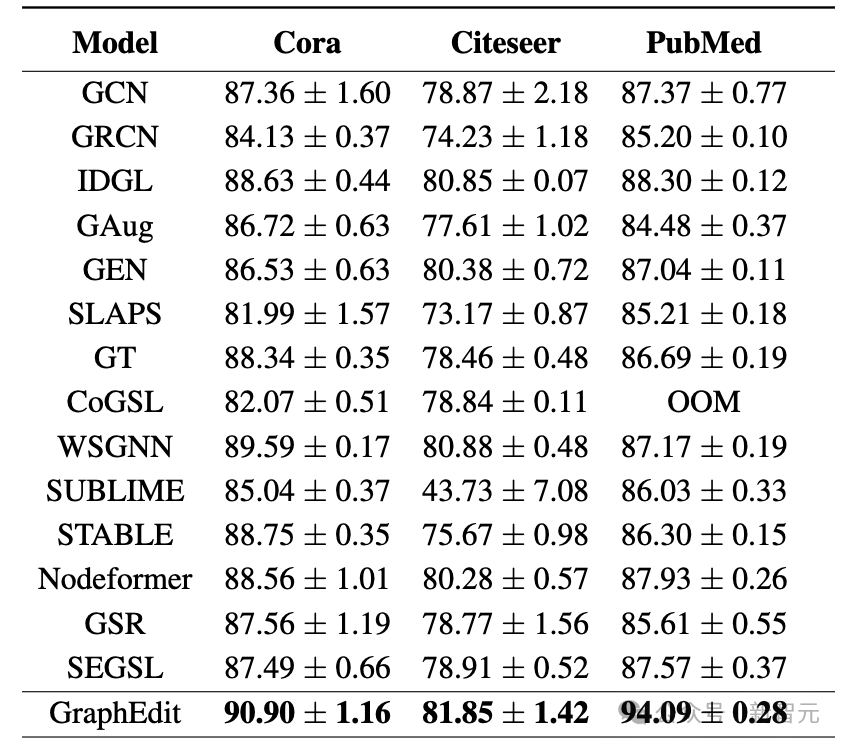
Obs.1 GraphEdit的卓越性能:
我们的GraphEdit模型与现有的GSL方法相比,在三个数据集上展现了优越的性能。这些显著的成果凸显了GraphEdit揭示隐性全局依赖性和有效消除图中节点间噪声连接的能力。
通过这一过程,GraphEdit不仅提高了图结构学习的准确性,也提升了学习到的图表示的整体质量和可靠性。
Obs.2 现有GSL方法的局限性:
在各种GSL基线中,只有一小部分一直优于标准GCN,而有些甚至阻碍了下游图表示的性能。这些发现揭示了过分依赖原始图结构作为监督标签的替代方案的局限性。
然而,必须承认,节点间观察到的连接往往是噪声多和不完整的,这对GSL方法生成高质量图表示构成挑战。相比之下,我们的GraphEdit利用LLMs的推理能力,将外部语义纳入图结构学习。通过这样做,我们优化后的图结构,在下游任务中提高了学习表示的整体质量。
Obs.3 数据集间性能的变化:
在分析GraphEdit的性能时,我们观察到相比于Cora和Citeseer,PubMed数据集有显著的改进。
与Cora和Citeseer不同,PubMed有更多的节点。因此,当使用相同数量的节点对进行训练时,LLM在PubMed中遇到了更多样化的情况。此外,与Cora常见的缺少摘要不同,PubMed节点中的文本信息始终丰富且详细。
另外,PubMed数据集只有三个分类,是一个较少复杂的分类挑战。在PubMed中进行相同量级的采样,使LLM相比于其他两个数据集,能够遇到与每个类别相关联的更多样化的边。
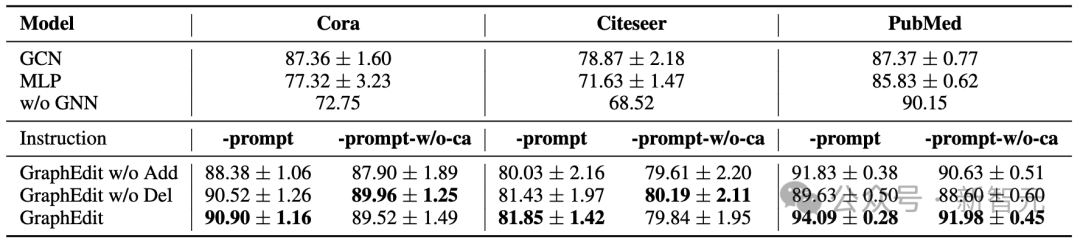
为了分析不同组件对LLM-GSL性能的影响,我们从两个关键角度进行了消融实验。
指令微调范式:
在表中,「-prompt」表示使用了完整指令微调范式对LLM进行微调,包括预测边的存在以及连接节点的特定类别这两个任务。
另一方面,「-prompt-w/o-ca」表示使用简化指令对LLM进行微调,不涉及预测特定节点类别。
图结构优化:
「GraphEdit w/o Add」变体指的是GraphEdit专门用于从原始图中删除边。这个变体的主要目标是识别并移除不必要或不相关的边,从而优化图结构。
相比之下,「GraphEdit w/o Del」变体指的是GraphEdit用于向原始图结构添加候选边的功能。这种方法旨在通过引入节点之间潜在有价值的连接来丰富图结构。
根据表中呈现的结果,我们可以观察到三个显著现象:
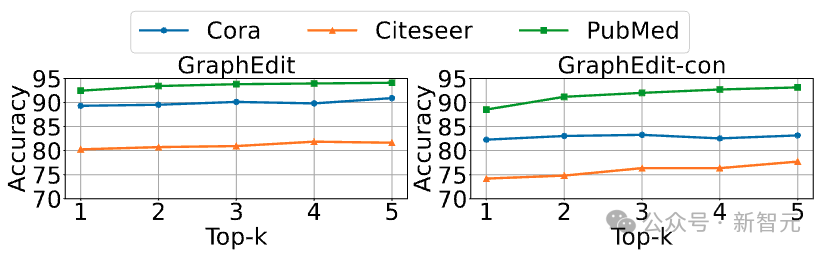
为了探究不同数量的候选边对模型效果的影响,我们通过改变k值(从1到5)来分析三个数据集上的性能表现。
总体上,我们观察到较高的k值倾向于提升模型的性能。然而,在Cora和Citeseer数据集上,性能提升在k=3之后趋于平稳,而在PubMed上,则在k=4左右稳定下来。
这表明存在一个阈值k,超过这个值后,GraphEdit的性能稳定,而没有显著的进一步提升。这些发现为确定候选边的最优数量提供了参考,确保在保持满意性能的同时,有效节约计算资源。
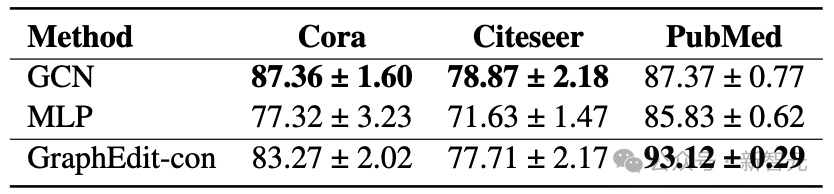
为了进一步展示我们提出的GraphEdit框架在揭示隐性节点相互依赖性方面的能力,我们在没有原始图结构的情况下,评估了其在三个数据集上的性能。结果显示在表中,其中「GraphEdit-con」表示仅使用GraphEdit构建的图结构。
值得注意的是,即使在缺少原始图结构的情况下,GraphEdit也展现出了值得称赞的性能。特别是在PubMed数据集上,GraphEdit的表现超过了原始图结构,凸显了其在文本丰富场景中的潜力。
虽然GraphEdit在Citeseer上没有超越原始结构,但它达到了可比的结果。因此,这一分析确认了我们的模型即使在没有明确图结构的情况下,也能有效捕捉内在的节点关系。
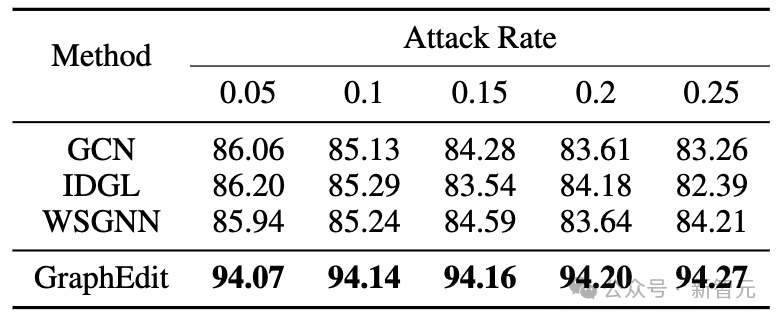
为了探究GraphEdit的抗噪能力,我们向三个数据集的原始图结构中注入了不同比例的噪声(从0.05到0.25)。选择IDGL和WSGNN作为基准,并将它们置于相同的噪声条件下。结果在表中详细说明。
分析显示,IDGL和WSGNN的噪声抵抗力有限。与之形成鲜明对比的是,我们的GraphEdit方法保持了稳定的性能。
令人惊讶的是,在PubMed数据集上,增加随机噪声边实际上提高了GraphEdit的性能。这表明GraphEdit在消除噪声边的同时,有效地保留了作为噪声引入的有益边。
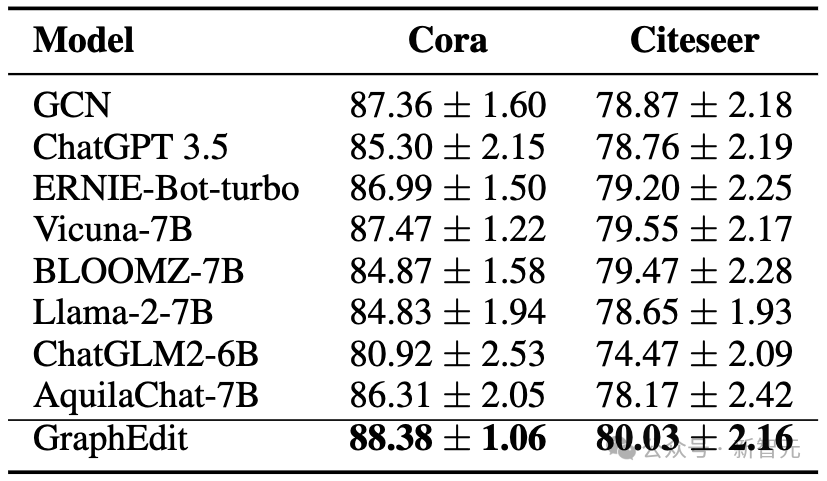
我们将GraphEdit与常用的LLMs进行了比较,以评估它们在Cora和Citeseer数据集的原始图结构上的去噪能力,使用的提示相同。结果总结在表中。
GraphEdit在两个数据集上的去噪性能都显著优于其他LLMs,展示了我们的指令调优方法的有效性。
值得注意的是,ERNIEBot-turbo、Vicuna-7B和BLOOMZ-7B在Citeseer数据集上表现良好,尽管它们在Cora数据集上的性能不那么令人印象深刻。这种差异可以归因于Cora节点中经常出现的摘要缺失,这影响了LLMs的决策过程并影响了最终图结构。
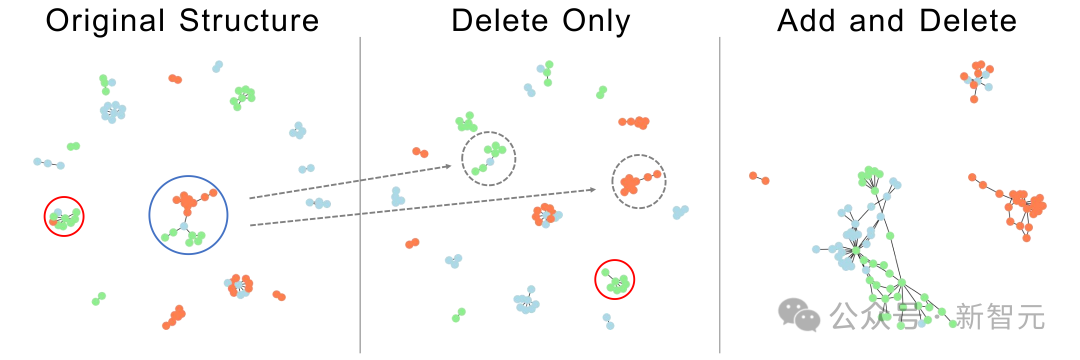
在这一部分中,我们使用图像来直观比较PubMed的原始图结构和优化后的图结构。图像排列如下:原始图结构位于左侧,GraphEdit删除后的图结构位于中间,添加然后移除边的结构位于右侧。
在原始图结构中,中心节点面临分类挑战,因为其邻近节点属于三个不同的类别。然而,GraphEdit通过移除围绕中心节点的不同类别的邻居有效地解决了这一问题,使得准确的类别判定成为可能。
此外,原始结构中有一个混合了三个类别的区域,在GraphEdit处理后成功地分裂成两个不同的子结构,简化了分类任务。而且,右侧的修改结构保持了类内连接,同时消除了类间链接。这些观察结果突出了GraphEdit不仅能去噪,还能以极大地促进GCN节点分类的方式重新组织结构。

为了展示预测节点一致性而非直接预测节点类别的优势,我们从PubMed数据集中提供了一个清晰的示例。
表中展示了一个简单的案例,其中原始PubMed图结构中的节点2601和6289相连,并属于同一类别。在GraphEdit的推理过程中,尽管它没有精确预测这两个节点的具体类别,但成功识别了它们类别的一致性。
这个例子凸显了GraphEdit的训练方法有效地减少了LLM推理中的错误率,重点捕捉底层的一致性而非精确分类。这个示例用于说明优先考虑节点一致性预测的好处,强调了GraphEdit方法捕捉图结构中有意义的模式和关系的能力,即使它在精确分类单个节点方面有所不足。
我们介绍了一个开创性的大型语言模型,名为GraphEdit,专为优化图结构而设计。我们的模型拥有识别节点间噪声连接和发现非连接节点间隐性关系的卓越能力,从而实现图结构的优化。
为了达到这个目的,我们将LLMs的力量与我们开发的轻量级边预测器无缝集成。这种集成使我们的模型能够优化图结构,使其与LLMs的推理知识保持一致。
为了评估我们模型的性能,我们在各种设置下进行了广泛的实验。结果一致地展示了GraphEdit的卓越优势。此外,通过彻底的调查,我们为模型设计背后的理念提供了进一步的验证。
参考资料:
https://arxiv.org/abs/2402.15183
文章来自于微信公众号 “新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
