# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让AI理解人的想法,而不是让人适应AI。

过去这半年,图像生成领域的更新节奏实在是太热闹了。
Banan Pro惊艳亮相,很快更具性价比的Banana 2推出。然后前两天GPT-Image-2在万众期待下发布,新神登基,各种以假乱真的生成图血洗全网。
像素级还原的UI、逼真的直播画面,还有本尊见了都得愣住的AI 梗图……看得人太恍惚了,Banana Pro守了大半年的王座,又转回了 GPT 手里。
然而在这片大厂混战里,我更感兴趣的,反而是一个非巨头背景的团队——Luma AI,以及他们仅凭一条宣传片,在X 上红极一时的Uni-1图像模型。

截止写稿时,这条Uni-1的发布视频浏览已超600万。
它没在国内火我还挺奇怪的。就个人体感来说,综合能力完全可以跟Banana Pro掰掰手腕。而且在扩散模型(Diffusion)统领天下的主流里,Uni-1高调宣布拥抱自回归Transformer这个新路线,也足够引起关注和讨论。
说到这儿,其实有不少人推测GPT-Image-2恐怖的能力跃升,可能也归功于自回归核心。
既然 OpenAI 还没公开具体的技术细节,我们觉得倒是可以蹭这波热度,盘盘已经把明牌打出来的 Uni-1。
可以说,就是脑子的区别。
Diffusion生图做的是概率演算,它并不完全理解自己在画什么。后来「用户输入—语言模型优化翻译—生图模型」的流水线提高了准确率。但听用户需求的和动笔的,还是两个脑子。这种割裂感,怎么修补都差点意思。
而自回归 Transformer,大家应也很熟悉,就是LLM(大语言模型)里最常用的架构。它在生图上,做的是「统一理解和生成」这件事。要画狗趴在桌子上,它得先脑子里有物理逻辑,知道桌子是平的,狗是立在上面的,才能把正确的像素放对位置。
Uni-1的自回归,用他们自己的话说,是为了让AI的创作过程更靠近人类左右脑的工作习惯。

理解、推理、编辑、生成,结合得更加紧密。这就是为什么这代模型突然变得「通人性」了。
🚥
为了看看Uni-1 是不是真有实力,我实测了好些 case。
但非常可惜的是进度慢了一拍,这篇文章的case是在GPT-Image-2发布前测的。一方面是来不及重roll,另一方面大家也对Banana更熟悉,所以这一次的case测试还是以Nano Banana作为对比基准。
和实力相当的对手 PK,或许你也更能感觉到 Transformer 架构生图有什么不同。
画面有质感,图文混排强
既然要测,画质肯定是第一关,我先跑了些细节要求多的画面,放两个比较满意的。
16:9,逼真的电影感街头肖像,一位年轻女子静止地站在拥挤的城市街道上,面部清晰对焦,表情平静而专注。长曝光效果,周围的人移动时产生强烈的方向性运动模糊,人群流动的轨迹形成条纹。自然柔和的日光,浅景深,逼真的皮肤纹理,平静的表情望着镜头,素颜,深色冬装和围巾。沉稳的基调,城市故事摄影。单反相机质量,85 毫米镜头效果,f/1.8,高动态范围,8K,

A medium close-up, cinematic photograph of a handsome man. He is looking upwards with a serious, pained, and deeply emotional expression, his eyes fixed on something unseen above. A single strip of white adhesive bandage is taped across the bridge of his nose. The scene is lit by intense, dramatic, bi-color neon lights. Intense magenta light bathes the front and top of his face. A cool, contrasting cyan-blue light emanates from the dark, indistinct background and provides edge lighting. The background is a blurred, dark cyberpunk cityscape with indistinct bokeh of neon signs (cyan, green, purple). The focus is sharp on his face, showing skin pores, beard stubble, and the texture of his dark leather jacket collar. Shallow depth of field, cinema still quality, film grain, hyper-realistic details.

指令完整遵循,而且细节质感和光影逻辑,都能和Banana Pro五五开。
既然单张画质兜住了,我们直接上强度,测测更吃能力的图文混排。
传了双Timberland的靴子和泥巴地的照片,让AI生成海报,要求广告语要在鞋子图层的下方。

用选中的两张图片作为参考,设计一张广告海报,通过一张图传达靴子耐穿、登山越岭也不会坏的感觉。 广告语“没有穿不坏的鞋只有踢不烂的你”,用中文粗体字体现在海报中,需要有排版设计,highlight的是“踢不烂的是你”。文字可以在鞋的图层下方。暗色调、泥土质感、粗犷字体,像 The North Face 户外广告。
Uni-1让我眼前一亮的瞬间来了。

这仨是我用同一个指令跑出来的,只有Uni懂得我想要的画面。
在我没有要求的情况下,它设计版式、排好图层、做了文字特效,甚至有透视。Uni-1在主动地把文字作为视觉元素融入设计,而不是仅仅作为贴图和标注。
我又试了一个水墨画+写诗的,直接对话框告诉AI:
用中国风水墨画形式表现“大漠孤烟直,长河落日圆”的情境,充分留白,体现中式含蓄的辽远的审美意境。 画面右侧用楷体字书写着一首完整的《使至塞上》,内容是【完整全文】。

三个模型都能理解意境,也画得不错。文字方面的确如社区所说,大的海报文字生成Uni很稳定,但这种小字的准确度比较玄学,Banana pro的文字更稳定,但显然是硬贴了一段印刷字体。
而Uni书画是一体的,更符合写Prompt时预期的古代文人给画题诗的感觉,是整体效果最自然的。
Luma发布Uni的时候,特别强调了一下它的一致性和空间逻辑表现,必须试试。
先测一致性,玩玩奇迹暖暖。给了Uni下面5张参考图和我的要求:
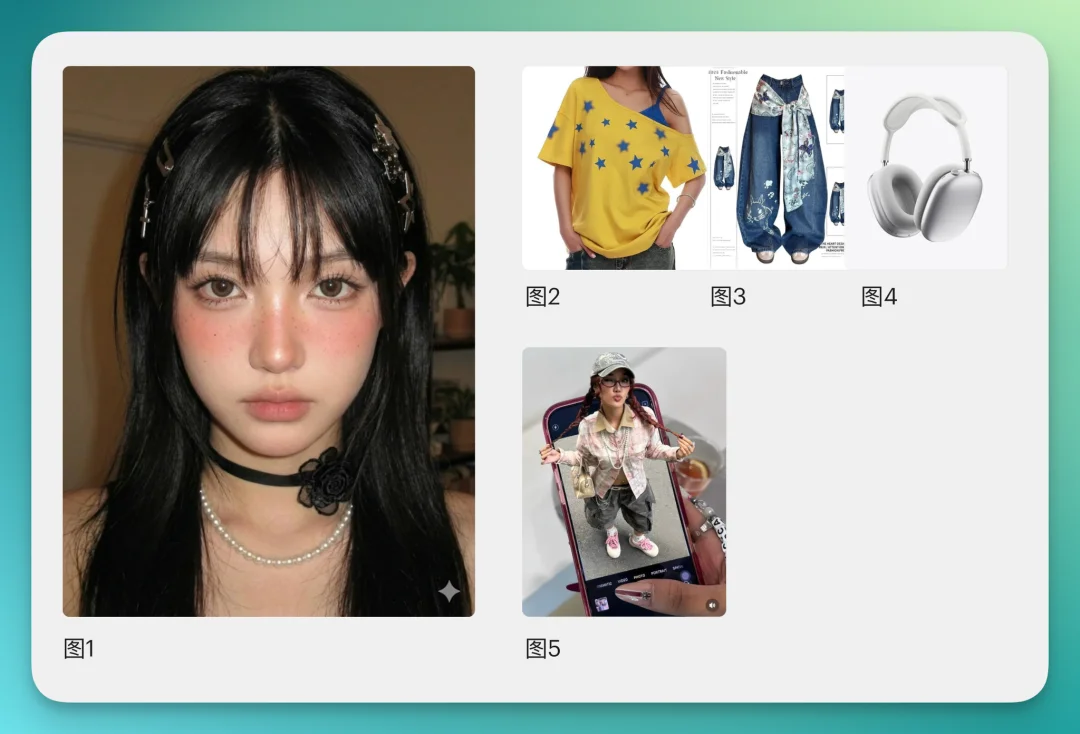
让图1的模特女孩,穿上图2的上衣和图3的裤子,脖子上挂着图4的耳机。 模特动作、人物角度和图5相同。 最终构图和画面排版也参考图5。
结果是这样的,和参考图对比着看。

好听话的模型,感动。要是生成的结果把透视和细节渲染再做自然点就更好了,但一致性的控制力确实OK。
再看看空间和层叠逻辑的表现。
《鬼灭》的无限城自带复杂的纵深和结构。Uni-1的参考图最多可以放9个,于是我上传了下面7组英雄,和2张动漫里无限城的截图:
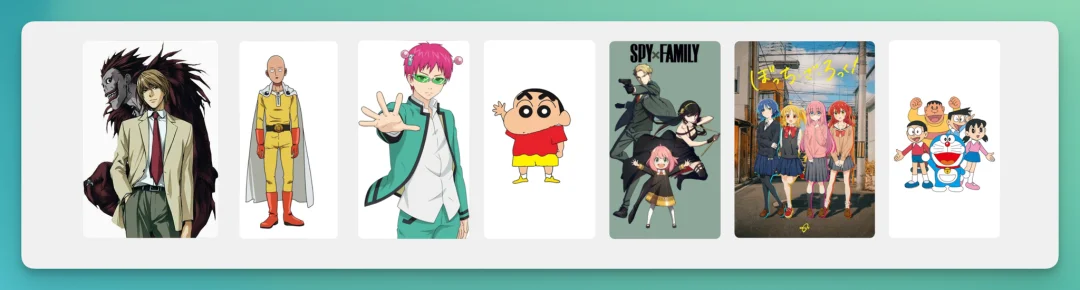
参考【场景参考】中的2张图创建一个无限城的场景,概念是会无限延展的木质结构楼内空间,然后将【角色资产】中的角色放置在无限城中。 要求:夜神月、一拳超人在画面左侧前景,蜡笔小新和齐木楠雄在画面右侧前景,其他角色在画面中后景

角色多,所以我给的指令不算太复杂,但在处理这么多参考的纵深关系时,Uni-1 的空间逻辑是最正确的,Banana Pro因多复制了一组角色惜败。而且对比来看,Uni 还控制了角色和场景的色彩饱和度,也融合得更好。
我又测了几个文本的空间逻辑。
真实照片质感,16:9,2K画质,自然暖光。蛋糕店室内场景。故事是“萝卜纸巾猫”和“蒸蚌”在蛋糕店里卖蛋糕。 前景:一张白色小圆桌,桌上摆着一个巧克力蛋糕,桌子局部遮挡两侧角色的下半身。 中景左侧:一个竹制、多层的大蒸笼,顶层笼盖掀开,里面躺着一只蚌。蚌是半圆形的,整只蚌朝向着桌上的蛋糕。 中景右侧:一只奶牛猫,穿灰色围裙, 戴着蓝色针织小帽,怀里抱着一包抽纸和一个棉花填充的胡萝卜玩偶。视线朝向桌上的蛋糕。 后景:蛋糕店室内场景。

类似《指环王》《权力的游戏》的奇幻电影感画面,16:9,2K。一条废弃铁路从画面左下角延伸至右上角,强烈纵深感,枯草荒野,枕木腐朽断裂。铁路中段,一只穿着铁甲的龙虾趴在轨道上。铠甲沿身体分节覆盖,脖颈和背部套着皮革马具harness(如胸颈革、背带),缰绳绑在龙虾头两侧。一匹戴牛仔帽的白马骑在龙虾背上,后蹄在龙虾背甲两侧,前蹄拉住缰绳驾驭龙虾。光源来自右上角远处,逆光,铁轨金属反光,龙虾铠甲边缘有高光轮廓。

Pro和Uni的差距真不大。对比来看,Uni-1 的图还是AI 味儿最淡的一个。虽然做不到100%正确,但我想要的感觉,尤其是画面的氛围,Uni最到位。
测着测着,我真觉得它懂我了。
有了前面这些单张画面的测试,我们把目光拉远一些:Uni 可以把这些能力组合在一起,讲好一个连贯的故事吗。
我在逛推的时候发现,很多日本用户的首波测试,都是奔着画漫画分镜去的。国内大佬的测试反馈也多对Uni-1画漫画的能力有好评。
漫画的确是AI生图能力的试金石。需要模型懂构图、能处理复杂的图文排版、要保持好人物和风格的一致性……最重要的,能不能用画面「讲故事」。
所以我试着走了一遍完整的条漫创作流程,画了一个「咕咕嘎嘎勇夺雪糕山顶上草莓宝石」的冒险故事。
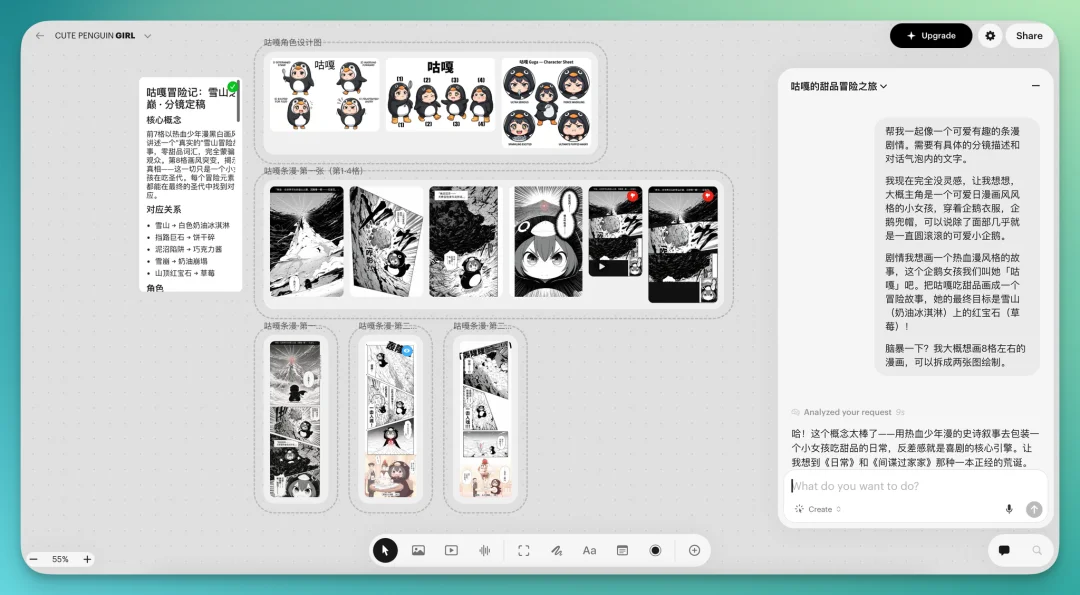
条漫任务复杂,而且我完全没想好分镜要画什么。所以先在对话框和Luma的Agent说我大概的想法:画一个企鹅女孩咕嘎看似在雪山热血冒险,实际只是在吃甜品的小条漫。
和AI交流合作的过程很顺,就是抛出【一个大概想法】-【沟通生成角色】-【确认分镜】-【生成最终条漫】。觉得不好的就让AI改,没什么特别大的卡顿。它想到的细节,也能启发我更多灵感。
聊想法时,建议在对话框选【Brainstorm】模式,聊好了再【Create】。

确认我们想法一致了,Agent就自己安排好在画布上写分镜文本、设计角色形象,一直到画前四格参考分镜,我都觉得不错。但合成条漫的时候AI设定的画幅太短,分镜拼得乱七八糟,实在是不满意。也可以让Agent停止生图,继续改改。

接下来就是让Uni生成,我评价,再改,再生成。从我提出模糊的想法,到AI画好条漫,应该花了不到一个小时。最后的条漫是这样的两张,我觉得还不错。

测到这里,我觉得Uni丝滑的感受,除了模型本身有进步,很大一部分也要归功于Luma自带的Agent工具。创作类Agent其实Google AI Studio、还有我们之前测评过的即梦Octo也有。
但Luma Agent往前多迈了一步,它多了一个视觉自我审查的环节。其实在前面的测试里,Agent 也一直在后台做这件事。它会自己用视觉能力去评判生成的图片是不是符合我最初的要求,有没有丢掉细节。
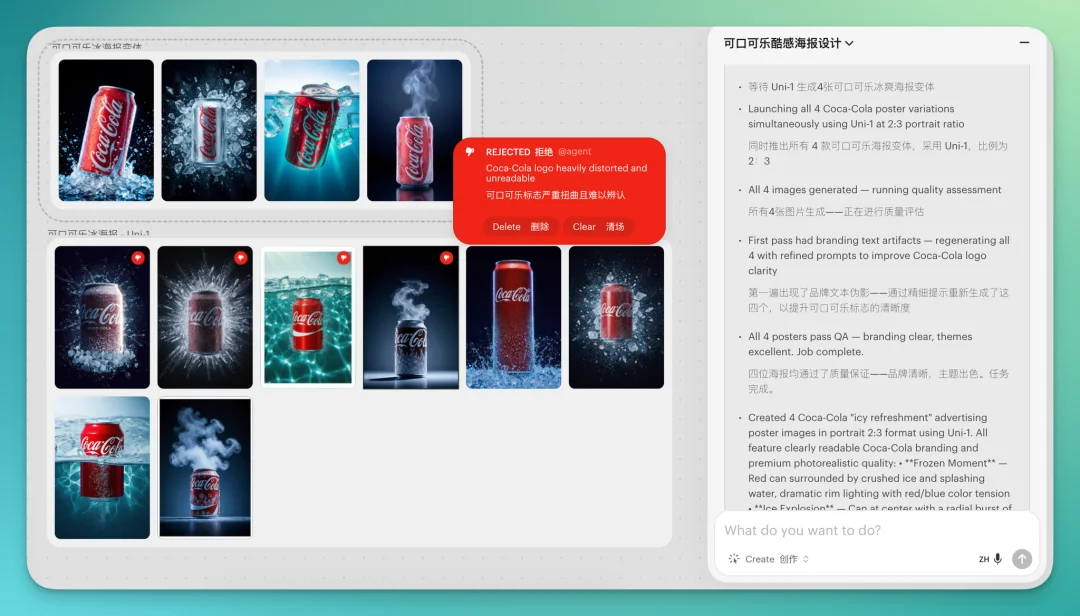
图上红色的👎标,就是它自己审视,给它认为的废稿打上的标记。判断Reject后,Uni会自动重roll。
比如上面古诗图的测试case,Uni其实自己纠正过,重roll后的文字就对了。
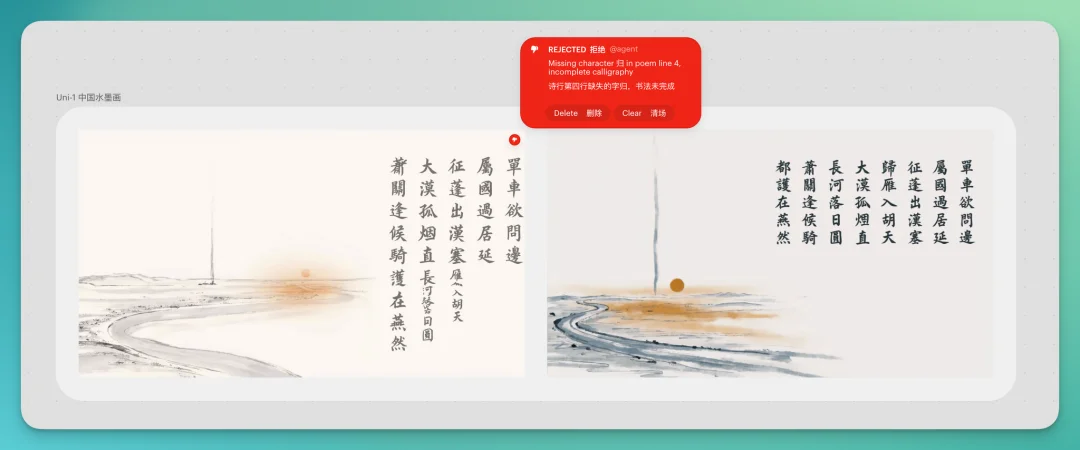
这个过程看起来非常奇妙。有点幻视以前o1和R1的self-play。
很多时候我们用 AI 绘图,发现它又画错细节、违背预期的时候,总是很令人抓狂。要么是手动画蒙版让 AI 重 roll,要么变着法子改进Prompt,跟模型斗智斗勇缠缠绵绵。现在好了,不用我再去学什么 PUA 话术了,AI 终于可以自己审视自己了。
非常支持AI们多内耗。
毕竟搞创作这种事,本来就该内耗的。把这部分痛苦的试错成本交给AI自己去消化,让人类把更多精力真正留给创意本身。
Uni-1 的亮点挺明确的:理解和推理能力、空间逻辑、生成质感统一。绝对是可以和Banana Pro对打的生图模型,Uni-1的交互体验也有点惊喜。
但有一说一,用过GPT-Image-2的都知道,准度和精度实在是太超模了。这也是大厂用数据和算法喂养出来的护城河,短时间内确实难跨过去。
所以如果你是追求稳定产出的生产力用户,首选肯定是GPT-Image-2,Sam Altman甚至把价格都打下来了,现在大概是Banana Pro的 1/4左右。。。
但如果,你是那种更看重创意思考,需要用AI做更多复杂流程创作的,Uni-1也确实值得玩玩。哪怕它现在还不是最强的,但它这种「试图理解人类脑回路」的底层逻辑,确实让我看到了一点生图领域的另一种可能。
而且发现个细节,Uni-1 出图的饱和度相对没那么高。如果你跟我一样不太喜欢鲜艳的AI 塑料感,体验应该会还不错。
需要提醒的是, Uni-1 目前没开放 API,只能在他们自己的网站用,且必须!手动选择 Uni-1 或者要求 Agent 用 Uni-1 生成。
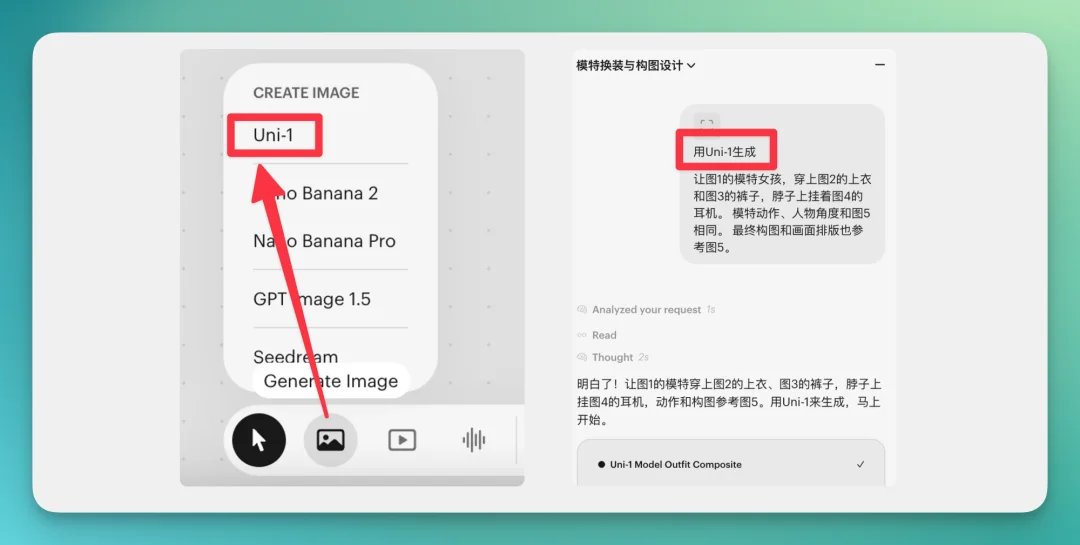
不然 Agent 是默认用 Banana Pro 画图的,也是不懂为什么。目前还没发现能一键固定选用Uni-1的方法,如果有大佬弄懂了,欢迎分享经验。
Uni-1现在可以用谷歌账号注册白嫖,大家可以动手试试。如果你有很多 Google 账号……
如果把视线从具体的生成案例拉高,回到 AI 图像生成过去的发展脉络,你会发现Luma Uni-1、GPT-Image-2这些模型的出现,还在回答一个更底层的问题:人机交互该走向何方。
计算机发展史的每一次跃升,从纸带编程到命令行,从图形界面(GUI)到如今的自然语言(LUI),主线其实只有一条:
不断降低人类的表达成本。
技术的终极目标,始终是让机器去「理解并学习像人一样思考」,而不是强迫人去「像机器一样工作」。
从这个角度看,Uni-1 放弃扩散模型,转投 Transformer,出发点就是希望图像生成的思考过程装上有逻辑的大脑。当生成的图像是真的理解图像后的绘制,而不是拼贴;当一个模型能够开始主动对用户意图进行逻辑推导,甚至像 Luma Agent 那样自我反思时,AI 似乎在向人类的认知方式靠拢。
Prompt 这门伴随 AI 爆发而诞生的外语,的确只是技术过渡期的一个补丁。
十字路口播客曾经采访过写出「神级 prompt」的 thinking claude 的作者涂津豪《他看到的未来,和我们有什么不一样?| 对话18岁的涂津豪:DeepSeek 前实习生、阿里数竞 AI 组冠军》[1],他在这期播客中也说过:
「它单单只是一个提示词,不是模型本身。当模型能力越来越强,你会想用更长的 Prompt,而不是更结构化的,从这点看它其实不重要。」
当机器能够真正听懂甚至补全人类的模糊意图时,横亘在创作者面前的技术门槛将被渐渐铲平。
当工具不再是壁垒,最纯粹的创意与审美,始终是艺术这个行业里唯一的硬通货。

文章来自于"十字路口Crossing",作者 "稳稳"。



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
