# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在刚刚,DeepSeek 的 GitHub 开始了频繁更新,上线开源了一个新的代码库 Tile Kernels,同时并对 DeepEP 代码库进行了更新,上线了 DeepEP V2。距离上次 DeepSeek 悄悄更新 Mega MoE、FP4 Indexer 还不到一周。
链接:https://github.com/deepseek-ai/TileKernels
据介绍,Tile Kernels 是为 LLM 操作优化的 GPU kernels,是用 TileLang 构建的。而 TileLang 是一种用于在 Python 中表达高性能 GPU kernels 的领域特定语言,具备易迁移、敏捷开发和自动优化等特性。
Tile Kernels 的性能非常强悍,正如 DeepSeek 写的那样:「本项目中的大多数 kernels 在计算强度和内存带宽方面都已接近硬件性能上限。其中部分已经在内部训练和推理场景中投入使用。不过,它们尚不代表最佳实践,我们也在持续改进代码质量和文档。」
代码库的介绍信息不多,然而字里行间「剧透」了 DeepSeek 下一代模型底层的架构创新路线。
下面是 Tile Kernels 的一些具体特性:
EPv2 地址:https://github.com/deepseek-ai/DeepEP/pull/605
在今天更早的时候,DeepSeek 还发布了最新版本的 EPv2,实现了更快的专家并行(EP),并支持 Engram / 流水线并行(PP)、上下文并行(CP)。
随着硬件、网络和模型架构的演进,DeepSeek 此前的 DeepEP V1 积累了过多的历史包袱和性能问题。
本次更新对专家并行(Expert Parallelism)进行了彻底重构 —— 与 V1 相比,仅需几分之一的 SM 资源即可实现极致性能,同时支持更大规模的 Scale-up(单机扩展)和 Scale-out(跨机扩展)。
此外,DeepSeek 还在本次更新中推出了实验性的 0 SM 系列方案,包括 0 SM Engram、0 SM 流水线并行(PP)以及 0 SM 上下文并行(CP)的 All-gather 算子。此外,后端已从 NVSHMEM 切换为更加轻量化的 NCCL Gin 后端。
下面是 DeepEP V2 版本的一些新特性:
遵循 DeepSeek-V3 的配置,在新版本下,在每批次 8K token、7168 隐层维度、Top-8 专家、FP8 分发以及 BF16 结合的设置下进行了测试,结果如下:
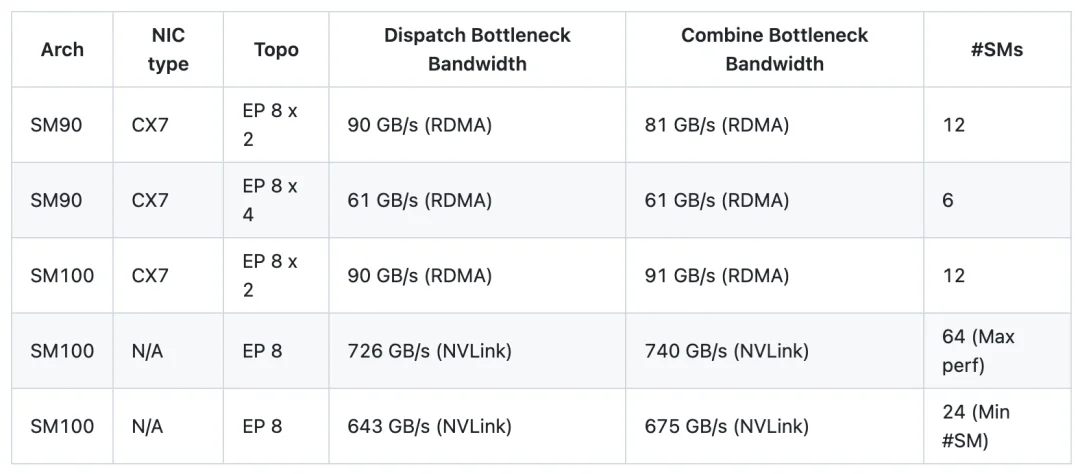
说明:结果显示的是逻辑带宽。例如在 EP 8 x 2 的情况下,90 GB/s 的带宽实际上包含了本地显卡(local rank)间的流量。
与 V1 相比,V2 实现了高达 1.3 倍的峰值性能,同时节省了多达 4 倍的 SM 资源占用。
最后,劝一下 DeepSeek,赶快发 V4 吧,都等急了。
文章来自于"机器之心",作者 "机器之心编辑部"。


