# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在刚刚,世界模型圈又闯出一匹黑马!
悄无声息地,它就拿下了两个世界第一。
在WorldArena中,总体EWM Score达到63.77,排名第一(截至本月中旬左右)。
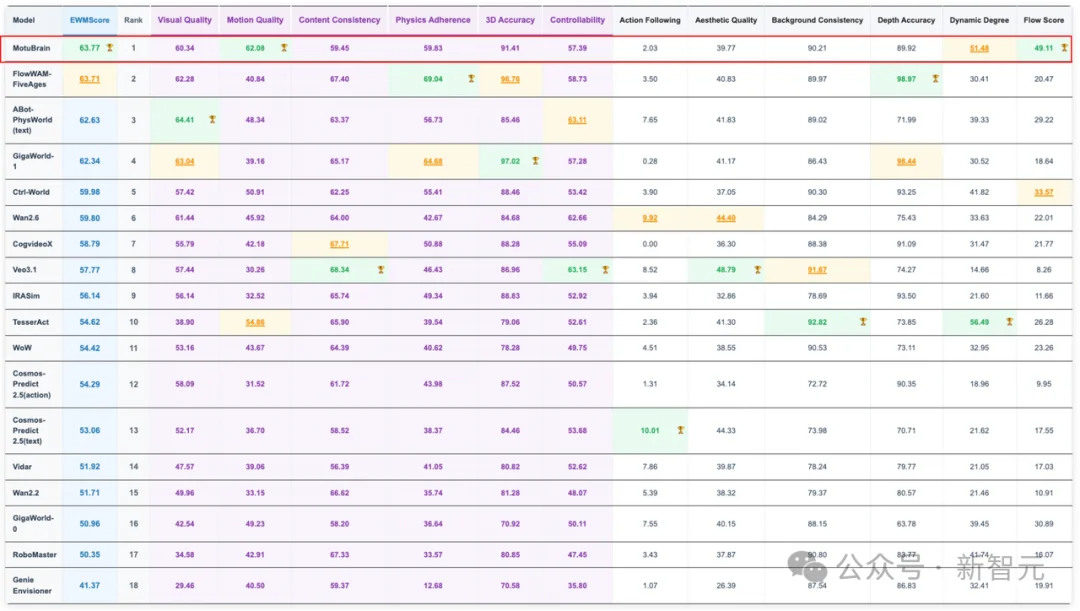
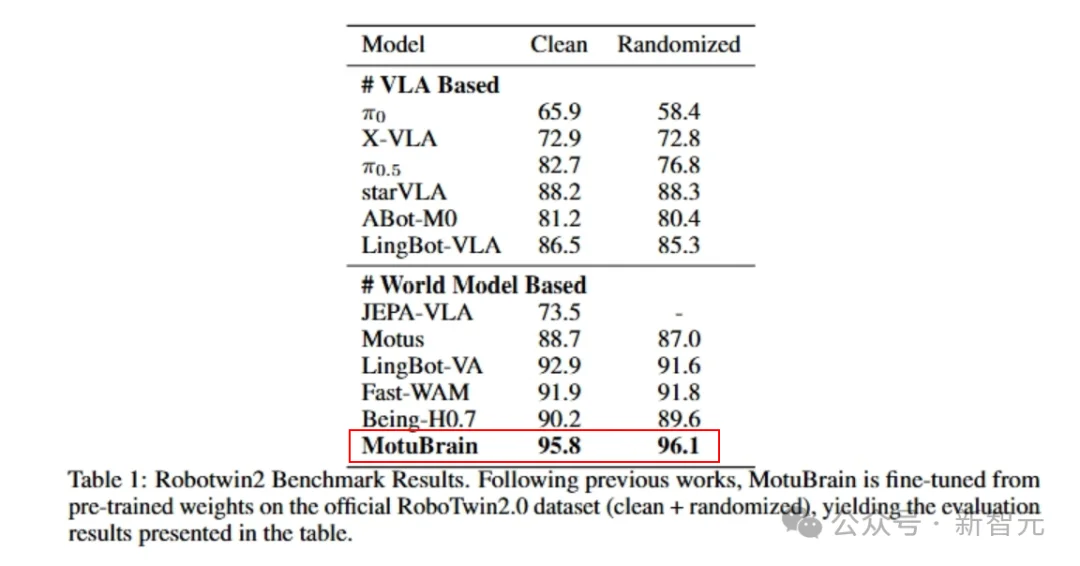
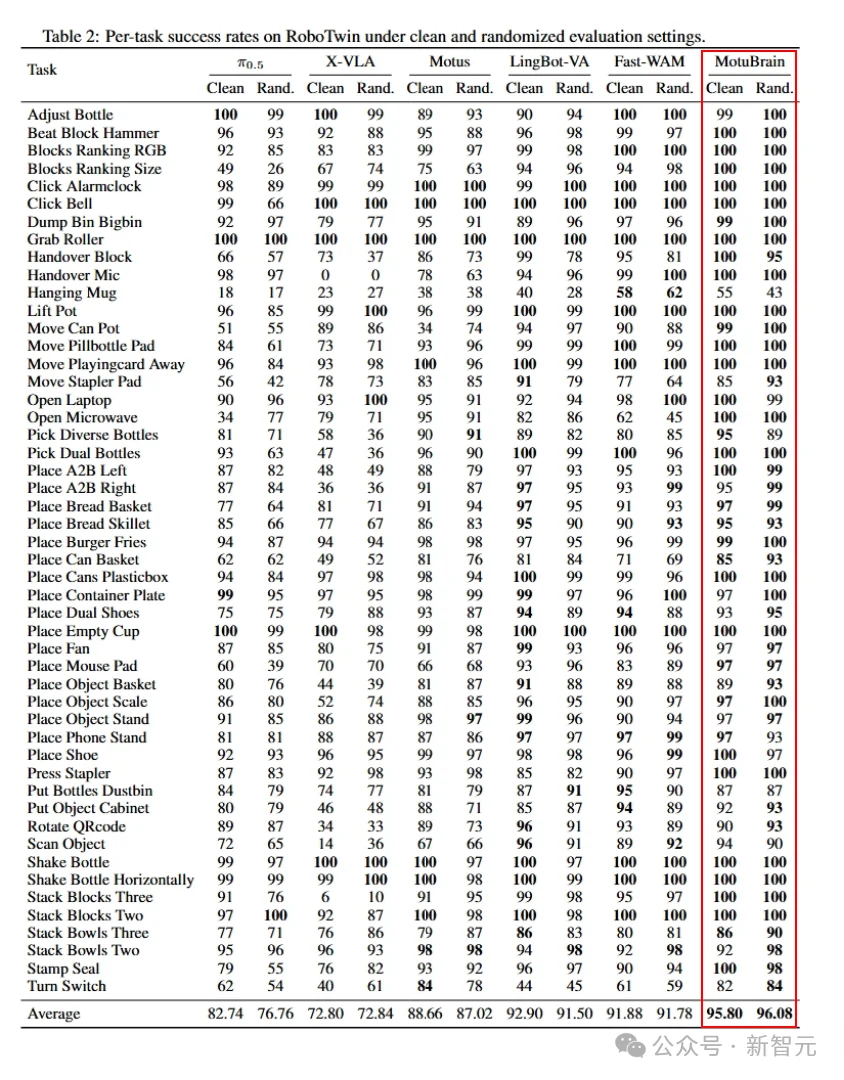
在RoboTwin2.0的Clean和Randomized两个场景下,它分别拿下了95.8和96.1,同样排名第一。
而且,它是百分百的零宣发。
这些荣誉,属于同一个模型——MotuBrain。
它出现得极其反常:没有Logo、没有发布会、没有融资稿,连X账号都是新注册的。
就这么一声不响地,同时爬上了两个国际权威榜单的顶端。
更离谱的是,这两个榜单彼此根本不挨着——一个考「你能不能真正看懂世界」,一个考「你能不能在世界里稳定干活」。
过去几年,行业把它们叫作「两个极点」:做世界模型的看得懂、动不了;做VLA的能动手、想不远。
同时拿下两个第一,业内前所未有。
具身圈猜测刷屏:这是阿里「快乐生蚝」翻版?字节憋的大招?或者华为的暗手?还是李飞飞World Labs的中国分舵?
直到谜底揭开,所有人都没想到——国产生成式AI公司生数科技。
而且他们没有止步与此,现在已经把world action model适配多个头部机器人本体,应对多种任务、建模多个长程任务。
这是工业级的demo,和其他的刷榜模型绝对不一样。
神秘面纱揭开
国产AI领先硅谷巨头
事情得从去年12月说起。
那时候,生数科技联合清华大学开源了一款叫Motus的大一统世界模型。

论文链接:https://arxiv.org/abs/2512.13030
项目主页:https://motus-robotics.github.io/motus
Motubrain官网:https://www.shengshu.com/zh/motubrain
才刚刚发布,Motus就已经在圈内小小震动了一下。
因为它在架构上把五种本来彼此割裂的具身智能范式,拧成了一个「看-想-动」的闭环:
VLA(视觉-语言-动作)、世界模型、视频生成、逆动力学、视频-动作联合预测。
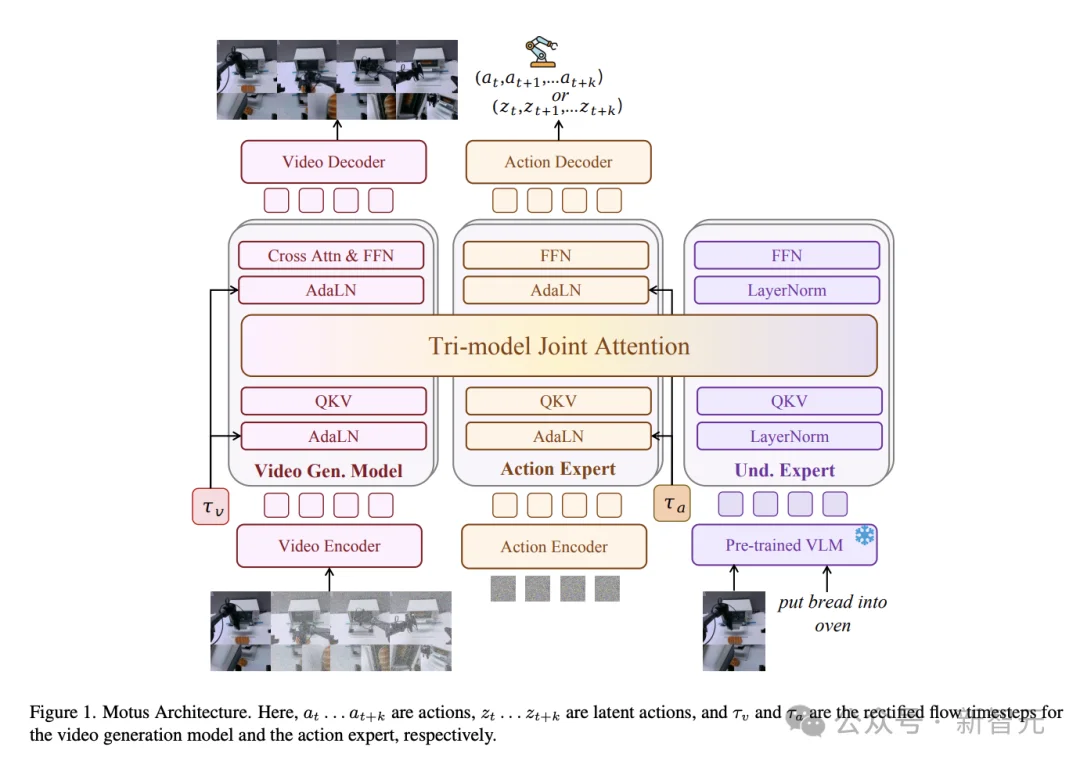
这种统一世界-动作建模,通过一个模型统一建模视频「video」与动作「action」,使之前彼此割裂的5种方法都成为同一建模框架下的不同推理模式。
与以往方法不同,Motus联合建模「视频」和「动作」,学到的不再是机械反应,而是任务目标、环境变化、以及动作会带来什么后果这三者之间的深层世界知识。这让它更能适应新环境和新任务。
Motus引入「潜动作」机制,能从无标签的互联网视频、人类操作视频中提取通用的「运动规律」。
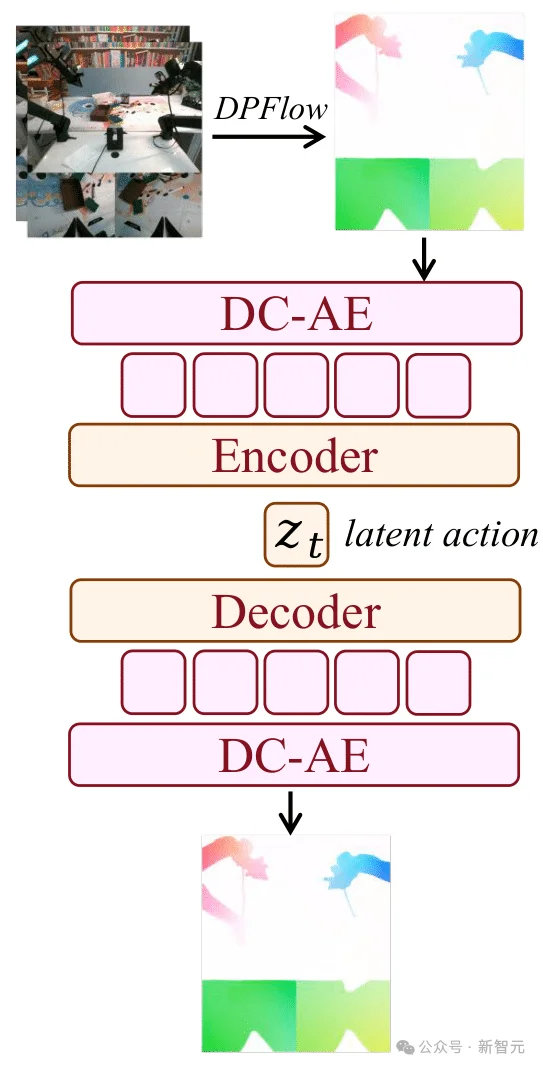
潜动作变分自编码器 (Latent Action VAE)。 这是一种基于光流的表征方式,通过变分自编码器架构将视觉动力学(visual dynamics)与控制信号相衔接
这让它可以利用近乎无限的海量数据来预训练,极大丰富了先验知识。
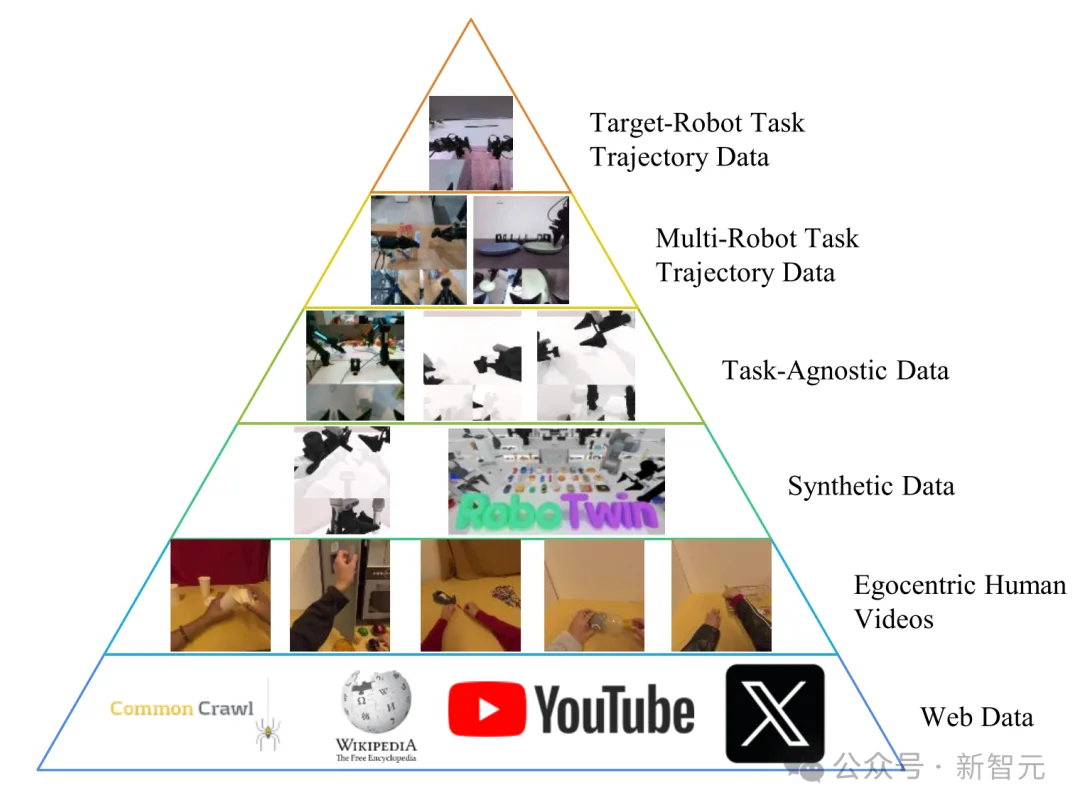
具身数据金字塔。 展示了从互联网数据(第一层)到目标机器人演示数据(第六层)的六级数据层级结构,其任务相关性和数据质量随层级逐级提升。
基于「专家混合」,Motus引入了混合Transformer (Mixture-of-Transformer, MoT) 架构,巧妙融合了视频生成、语义理解、动作生成三个已有的高性能基座模型。
这相当于让模型同时拥有了「想象力」、「理解力」和「执行力」。
Motus表现出了正向的规模效应,即学习的任务越多、数据越丰富,模型掌握的可迁移世界知识就越多,在新任务上的平均成功率反而越高。
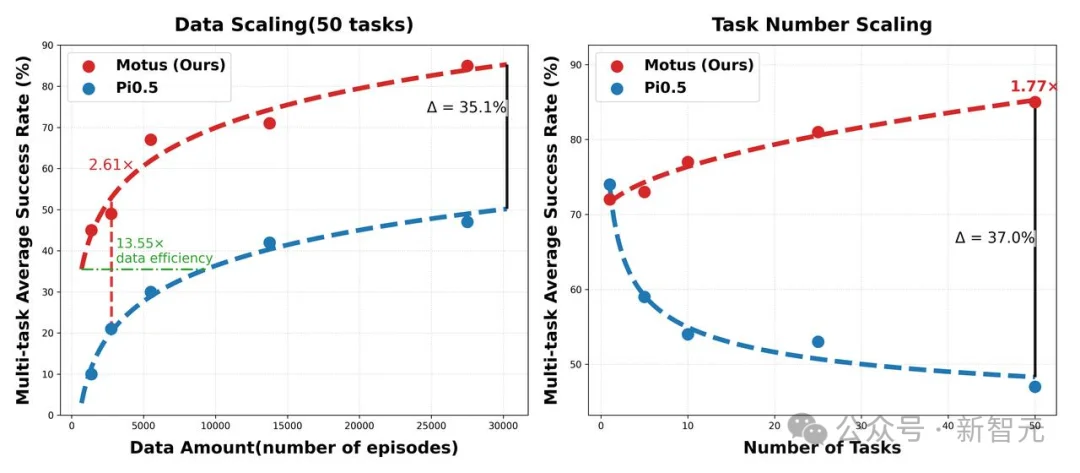
这是它学到了通用规律而非死记硬背的有力证据。
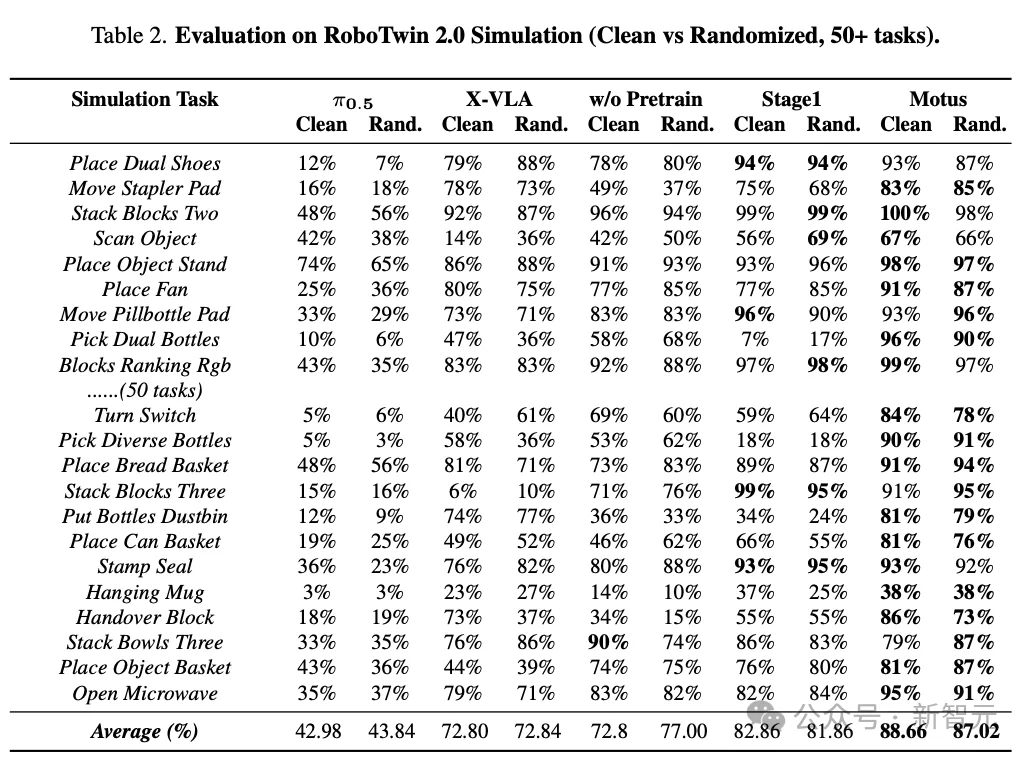
在50项通用任务测试中,Motus的平均成功率高达88%,在当时的RoboTwin2.0上直接霸榜。
但Motus还是起点,MotuBrain才是它进化后的「完全体」——
一个面向真实世界的通用世界行动模型(World Action Model,WAM),具备多本体、多任务、长程执行能力。
在Motus的基础上,MotuBrain更上了一层楼。
简单说:Motus证明了「路走得通」,MotuBrain证明了「我已经在这条路上跑出了世界第一」。
在Motus的基础上,MotuBrain作为商用模型版本,进一步面向真实机器人场景完成系统升级,将World Action Models从技术验证推向更通用、更可落地的具身智能大脑。
为什么这件事让具身圈如此震动?因为在过去一年里,这条赛道挤满了顶级玩家。
大家都在抢同一个高地:怎么把「预测世界」和「驱动行动」放进同一个大脑。
结果,生数科技抢先做到了。
MotuBrain
理解世界,预测世界,行动于世界
下面的demo,详细展示了全球第一的世界模型已经进化到了多么强大的地步,全部任务一镜到底。
装上MotuBrain的机器人给我们演示了一把这个操作:把花插入花瓶中,然后开始用喷壶喷洒清水。

这个操作难度在哪里?
传统机器人方案通常需要一个昂贵的「上层大脑(VLM)」负责拆解指令,再由底层驱动去执行,这种「拼凑感」往往导致动作断档。
而MotuBrain实现了一脑贯通:它无需额外视觉语言模型的辅助,仅凭自身即可直接建模复杂的长程任务,让「从插花到浇水」的逻辑转换如同人类本能般丝滑。
另一位机器人,则在插花机器人的身后整理沙发。
它先将沙发上的衣物放入洗衣篮,然后将靠枕摆回原位,过程中还要弯腰捡东西,这都体现了全身动作的协调性。

接下来,还有更上难度的操作!
只见机器人大厨从锅中舀出了一份丸子放入碗中,同时还倒了一杯果汁。
这个过程人做起来很容易,但对机器人来说,要克服一系列难关。

对人类而言,勺子没捞到东西就再试一次是常识;但对机器人,这涉及极其复杂的闭环感知。
比如,它需要理解当前勺子的空的,通过物理推演意识到「目标未达成」,然后还要预测自己需要重新执行捞取动作。
甚至,机器人的左右手还要同时执行不同的任务。
这种「一脑预见」能力,本质上是机器人对真实物理世界的深度建模——它不仅在看,更在预测物理世界的走向,并以此驱动行动。
下面这个调酒机器人,使用了基酒和牛奶调制了一杯鸡尾酒,然后娴熟地放在了托盘上,这是一个极其复杂的长程任务。

另外,机器人还能整理洗漱台。只见它将牙刷准确地放入杯中,还把肥皂放回原位。

这些操作对于很多机器人来说,都难度很大。
液体流变、精细抓取,包括叠衣服过程中的织物形变……每一个动作背后的物理反馈逻辑迥然不同。
以往,业内需要为每个场景单独训练模型,但MotuBrain却展示出了卓越的「一脑多能」能力,只要一个模型,就可以应对多种任务。
更令人惊喜的是,MotuBrain还能做到一脑多型,一个模型就能适配不同的机器人。
这意味着它不是某个特定硬件的专属,而是一个通用的「数字灵魂」。
同一个模型,可以瞬间适配各种形态、各种自由度的机器人硬件,让AGI真正走入现实物理世界。

双榜第一,到底意味着什么?
让我们认真看看这两个榜单的含金量。
WorldArena:机器人看得懂世界吗?
这个榜单测的是「机器人对真实物理世界的理解到不到位」。
MotuBrain在这里拿下63.77的EWM Score,排名第一,超过了国内外的同类模型。
更值得玩味的是它领跑的几个细分维度:
这三个指标都和「运动」直接相关。
对一个未来要服务机器人的世界模型来说,这才是真本事——画面再美,机器人执行时一抖手汤就洒了,等于零。
RoboTwin2.0:机器人能在世界里干活吗?
如果说WorldArena考「理论」,RoboTwin2.0就是考「实操」。
在Clean(干净)和Randomized(随机扰动)两个场景下,MotuBrain分别拿到95.8和96.1——是榜单上唯一一个在随机环境下平均分超过95的模型。
在接近一半的具体任务里,它都达到了100或接近100的成绩。
跟谁比?JEPA-VLA、Pi-0.5——这些都是行业内大家熟悉的硬茬。
结果,MotuBrain在RoboTwin上的表现,用一个词形容就是「碾压」。
把两份成绩放在一起看,意思就很清楚了:MotuBrain既看得懂世界,又能在世界里稳定干活。
这不是单点强,而是一种系统级的、接近「通用机器人大脑」的能力特征。
MotuBrain:为行动而生
过去两年,具身智能走了几条不同的路:
各有亮点,但都有同一个天花板——局部统一。
VLA学动作模式,世界模型学预测能力,彼此拼接、对齐,终究是五个专科医生会诊。
MotuBrain走的是另一条路:真正的大一统。

它基于自研UniDiffuser架构,将视频和动作两个连续模态从底层统一建模。
一次训练,同时学会五种能力:VLA、世界模型、视频生成、逆动力学、视频-动作联合预测。
正因为大一统,MotuBrain能吸收多模态异构数据——课本、视频、生活观察、跨学科交流。而VLA只能从特定机器人的纯任务轨迹里学习。长期看,差距是数量级的。
通过MoT架构,MotuBrain融合了视觉、语言、动作三种模态。
VLA只有「静态理解」,看到一个杯子,知道「这是杯子」。
MotuBrain还能预判:「如果我推它一下,它会怎么倒、汤会怎么洒。」
一脑多能:一个大脑,应对多种任务
很多机器人模型没法同时做多个任务。
任务一多,成功率就容易下降。
MotuBrain 的目标是让同一个模型处理更多任务。
更重要的是,随着任务数量增加,模型在不同任务之间学习共享的世界知识。
比如抓取、移动、放置、组合、连续操作,看起来是不同任务。但背后都有共同规律:物体会受力,动作有先后,而且环境会变化,错误需要调整。
这些规律被模型学到之后,就能迁移到新任务里。
这就是多任务泛化能力。
实验证明:随着任务数量增加,Pi-0.5成功率持续下降(过拟合任务轨迹),而MotuBrain成功率持续上升——这说明它学到了跨任务的通用世界知识。而且上升的曲线越陡峭,说明模型泛化性越高,这是 MotuBrain 相比Motus的进一步跨越。
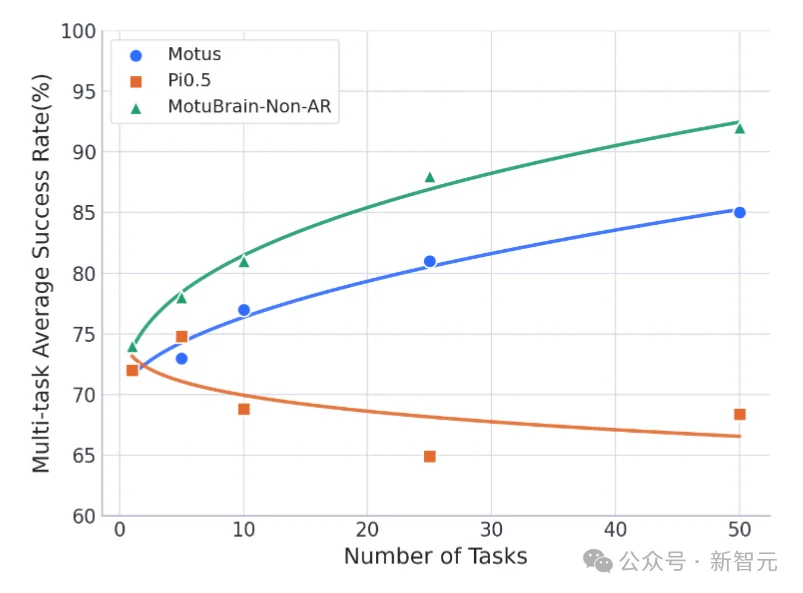
一脑多型:一个大脑,适配多种机器人
现实世界里,机器人有很多形态,比如双臂机器人、移动机器人、人形机器人、机械臂。

它们的身体结构不同,动作格式也不同。
然而,传统方法常常是「一个机器人,一个模型」。换了本体,就要重新适配;换了硬件,又要重新训练。
MotuBrain,就是想要打破这个模式。
它通过统一action表征,把不同机器人本体的动作数据放进同一个框架里学习。
这样,模型学到的就不只是某一台机器人的动作格式,而是更通用的行动规律。
生态里的机器人种类越多,场景越丰富,数据越多,模型能力还可以继续提升。反过来,模型能力提升后,又能帮助更多机器人提升表现。这会形成一个正循环。
一脑贯通:长程任务,一路到底
不过,在现实世界中,真实任务很少只有一步。
机器人要做的不仅仅是「拿起杯子」,它可能要先找到杯子—>再避开障碍—>再抓起杯子—>再移动到指定位置—>最后放稳。
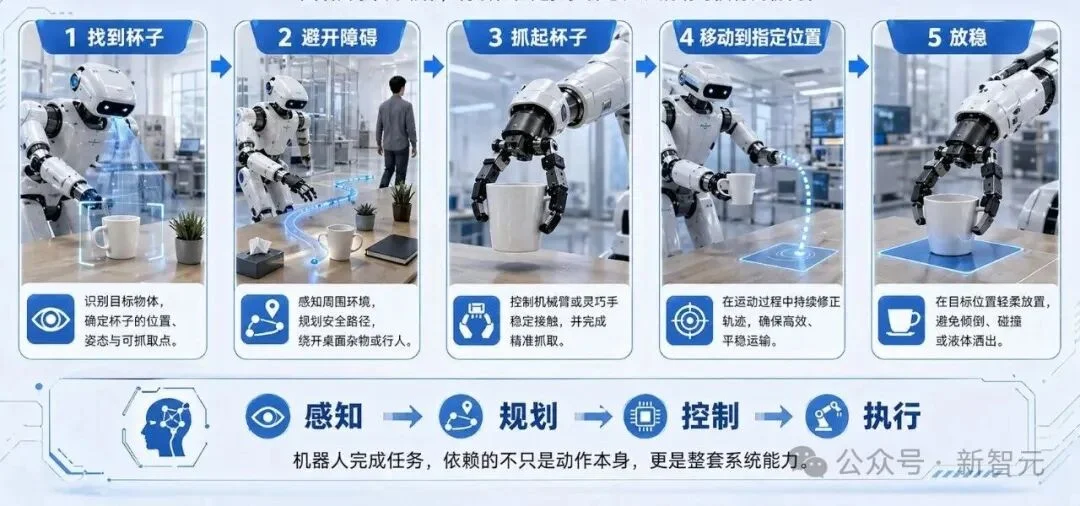
这是一条完整的任务链。
传统方法往往需要上层规划器先拆任务,再让不同模型分别执行,但任务越长,中间出错的概率越高。
MotuBrain的特点就是,可以直接学习完整任务链路。
它不完全依赖上层规划、快慢双系统或多个模型拼接,可完成超过10个原子动作级别的复杂长程任务,远远超过在2到3个原子动作的Demo展示。
这一点非常关键。
因为真实机器人要服务真实世界,就必须能持续推进任务,不能做一步,停一下。
实验证明:随着数据总量增加,MotuBrain稳压Pi-0.5一头。
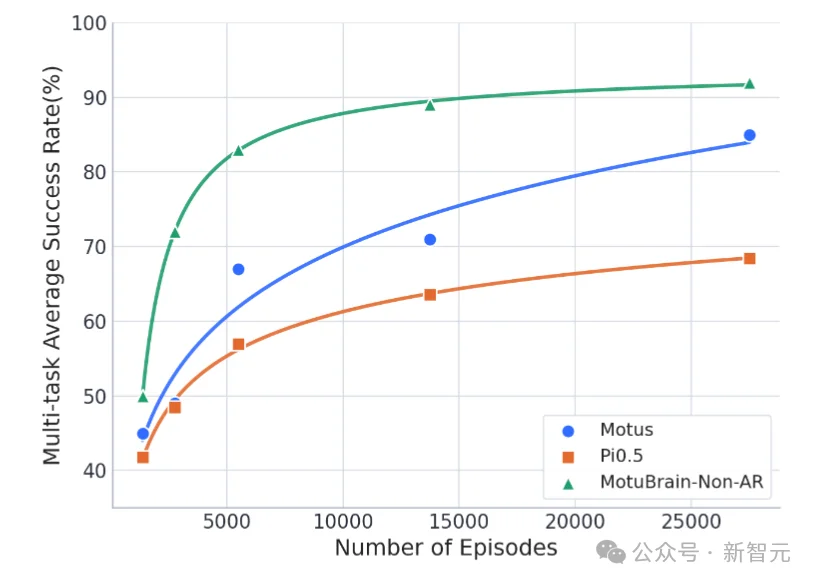
一脑预见:预测世界,驱动行动
此外,机器人执行动作,最怕的就是只看眼前。
人类拿杯子时,会自然预判:手碰到杯子后,杯子会不会滑?桌面有没有水?杯子会不会被推倒?旁边有没有障碍物?
这些判断,决定了动作是否稳定。
而MotuBrain的目标,就是让模型具备类似的预见能力。
它不只是执行指令,还要理解世界。它会预测环境变化,再根据预测结果调整动作路径。
所以,它的能力可以总结成一句话:预测世界,也驱动行动。
生数的世界模型大局观
从数字世界,到物理世界
理解MotuBrain,光看技术参数还不够。它背后是生数科技整个通用世界模型战略的一块重要拼图。
去年三月,生数科技创始人朱军教授,抛出了一个大判断:「通用世界模型是连接数字世界与物理世界的桥梁。」
这句话不是空话。
它对应的是生数科技正在搭建的一个完整体系——以通用世界模型(Foundation World Model)为核心底层,基于全球首创的U-ViT架构(早于Sora的DiT架构),不断积累视觉、听觉、触觉等多模态信息,形成对世界的统一认知。
在这个底座之上,生数科技走出了两条腿。
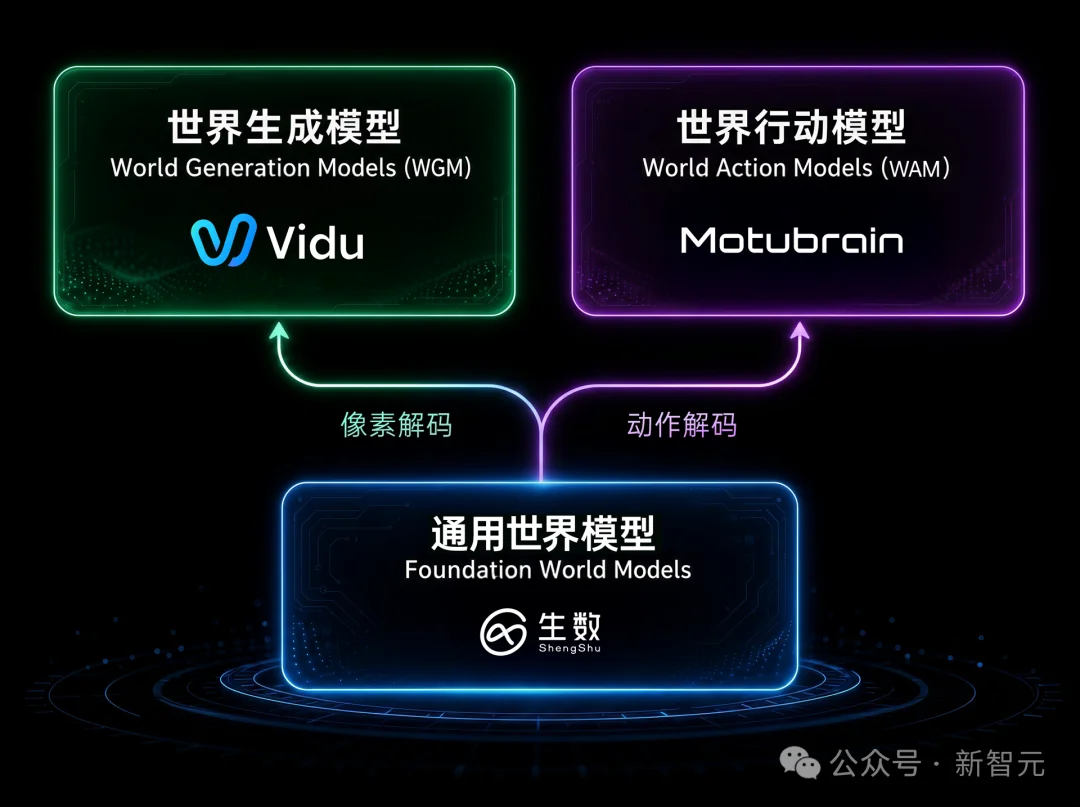
数字空间:Vidu——在屏幕里「生成世界」
基于世界生成模型(WGM),生数科技打造了视频大模型产品Vidu,服务全球200多个国家地区的数千万用户,合作方包括好莱坞工作室Aura Productions(用Vidu制作50集动画短剧)。
这条线解决的是「数字内容怎么被高效生成」的问题。
物理空间:Motus/MotuBrain——在现实里「行动于世界」
基于世界行动模型(WAM),生数科技构建了Motus和MotuBrain,目标是给真实世界的机器人安上一个统一的大脑,解决传统具身智能链路割裂、数据稀缺、泛化能力弱的痛点,实现真实世界下的零样本泛化与跨本体适配。
两条线一加,生数科技形成了一个完整的闭环——预测世界、生成世界、行动于世界。
MotuBrain双榜第一,只是这个战略图谱里的一次「亮剑」,证明物理空间这条线已经走通了。
最近,生数科技在产业侧也动作不断。先后与无界动力、深朴智能、星尘智能达成战略合作,把MotuBrain从「实验室SOTA」推进到「机器人本体适配+真实场景落地」。
总之,MotuBrain回答的是「通用机器人大脑能不能成立」,而生态合作回答的是「这个大脑怎么真正进入工厂、家庭、商业场景」。
写在最后
从「造身体」到「造大脑」的产业拐点
过去几年,机器人产业一直在比拼「身体」——电机更精准、传感器更丰富、整机成本更低。
但真正卡住所有人的,一直是大脑。
资本已经率先用真金白银投出了答案:近一年具身智能的大额融资,几乎都砸向了「做大脑」的公司。
这是一场关于下一代「机器人操作系统」入口的卡位战,谁先建立起world+action的统一架构,谁就拿到了未来十年的船票。
MotuBrain的双榜第一,更像是给整个行业递交了一份证据:通用机器人大脑这件事,中国团队已经走在了第一梯队。
更让人感慨的是这股力量的来源——生数科技,在没有动用什么「营销大招」的情况下,用代码和数据正面把硅谷标杆Pi-0.5撂倒了40个百分点。
未来的故事还很长。
当「预测世界」和「驱动行动」被装进同一颗大脑,机器人才真正配得上「具身智能」四个字。
而这件事,中国团队已经在领跑。
官网链接:https://www.shengshu.com/zh/motubrain
文章来自于微信公众号 "新智元",作者 "新智元"


