# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

深度求索(北京子公司)和月之暗面都位于海淀区知春路一带,相距仅1.4公里,步行只需十几分钟。站在其中一家公司的会议室里,能隔空望见另一家公司的办公楼。或许在某些时刻,它们的研究员会隔着一片楼宇对望,脑海里浮现的尽是关于AGI蓝图的构想。
物理空间的接近,让这两家公司员工气质多有相像:低调,纯粹,专注AGI。在社交媒体里,你能看到几乎每位DeepSeek研究员的关注列表里都会有Kimi研究员,而Kimi研究员的关注列表里也躺着不少DeepSeek研究员。
过去一年,Kimi研究员对DeepSeek几乎不吝赞美。我们去年7月和Kimi的人士有过短暂交流,当时他就直言“感谢DeepSeek”。本月初,《人物》杂志详细报道了月之暗面这家公司,同样指出“你能够感受到公司中蔓延的对DeepSeek的尊重”。
正是DeepSeek R1的出现教育了市场,硬实力就是最好的推广。去年Kimi也选择了DeepSeek敲开的推理路线,并一路在agent能力上实现超越。
这种惺惺相惜,也体现在DeepSeek的研究员身上。一位DeepSeek研究员非常直白地告诉我们,他个人比较看好Kimi,这两家公司有着相似的技术理想,也更纯粹,但在管理上略有不同。DeepSeek做事慢一点,会做得更细致一点,“如果Kimi老板看对了方向,可能比DeepSeek更快接近AGI。”
相似的技术气质,让这两家公司更愿意押注那些成本高、周期长、不确定性强的方向,也因此更有机会触发范式级的能力跃迁。
它们同样是资本热衷的对象。一位去年参与Anthropic融资的国内一线投资机构人士告诉我们,国内模型公司里,如果能闭着眼选两家直接打钱,一个是DeepSeek,另一个就是Kimi。
从投资人、大模型科学家到行业内部从业者,都在不约而同地将这两家公司放在同一坐标系中审视。审视公司,也是审视两位创始人梁文锋和杨植麟。他们同样信仰Scaling Law的底层力量,坚持“模型即产品”的极简逻辑,在互联网大厂的流量围剿中守住了C端用户基本盘,也同样在海外市场撕开了中国大模型的品牌缺口。
海淀区知春路一向被认为是创业者的福地。张一鸣曾于2012年在知春路的一处民宅中创立今日头条,开启了他的创业历程。当前AI时代,这两个扎根知春路一带的AI创业新星,在技术迭代、战略选择甚至一些心境上,都愈加同频。
一种默契
4月的倒数第二周,Qwen、Kimi、DeepSeek、小米、腾讯的新模型扎堆发布。4月20号,Kimi发布了Kimi2.6并开源,该模型在多项编码基准测试中超越GPT-5.4和Claude Opus 4.6等闭源模型,大幅增强了Agent自主化执行能力,长程编码能力也得到显著提升。
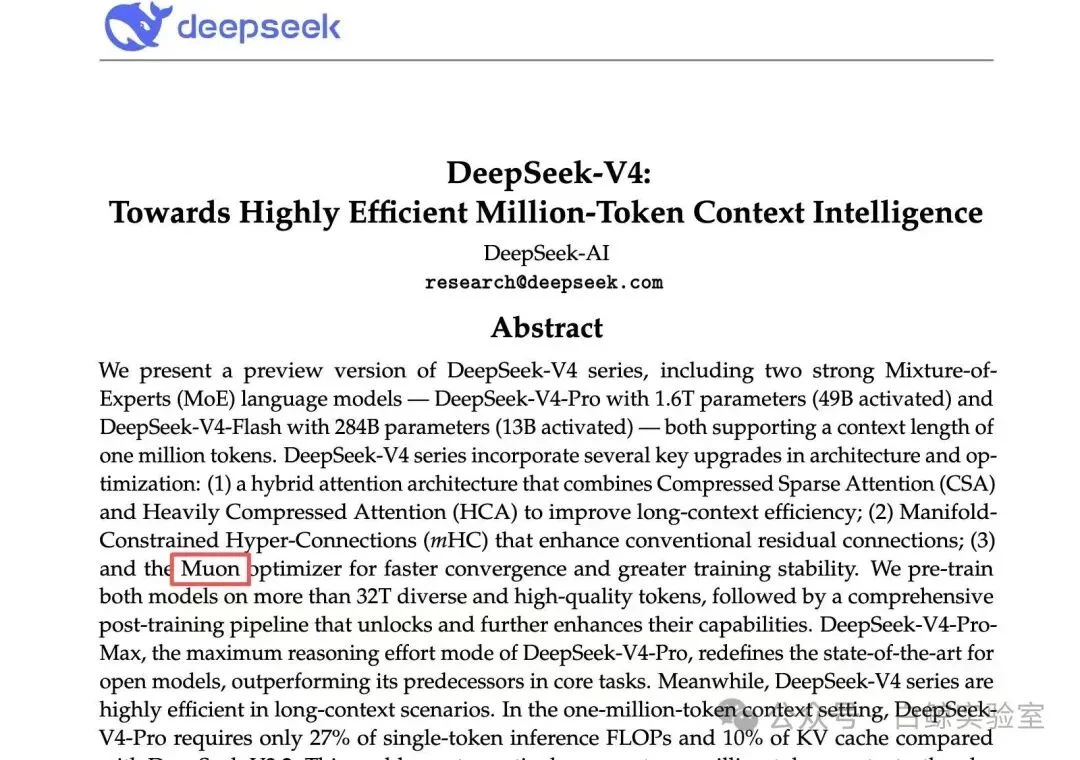
仅仅4天后,DeepSeek V4也终于在外界的关注下姗姗来迟。DeepSeek官方同样称,相比前代模型,DeepSeek-V4-Pro的Agent能力显著增强,在Agentic Coding评测中,V4-Pro已达到当前开源模型最佳水平,并在其他Agent相关评测中同样表现优异。
此时距离上一代V3发布已经过去了484天,这期间DeepSeek从爆红到几乎隐身,用户数也一度大幅下滑,甚至被指责只是昙花一现。梁文锋团队承受巨大压力。在官方公众号发布V4新模型的文章里,梁文锋引用了荀子的名言:“不诱于誉,不恐于诽,率道而行,端然正己。”这是他的自勉,也是对过去一年最好的回应。
没人比杨植麟更懂这种被全世界冷落的感受。去年年初DeepSeek爆红时,作为创业明星的杨植麟默默承压。外界纷纷诟病月之暗面陷入流量依赖的路径陷阱,基座模型进展迟缓,在万亿参数竞赛、推理能力突破、开源生态布局上,全面落后于横空出世的DeepSeek。
杨植麟对此从未回应,只是带领团队埋头研发新模型。直到2025年7月11日,Kimi K2发布,总参数达到万亿,并采用Muon二阶优化器训练,也是国产大模型首次大规模用二阶优化。
一时间Kimi K2震动全球,《自然》杂志称:“另一个DeepSeek时刻”。杨植麟用新模型回应过去的一切。
去年8月,杨植麟接受媒体人采访时说:“这也是Kimi跟我讲的——任何中间状态都有可能成为被批评的对象。你总是会有这个时代的局限性。”这种豁达的价值观,与梁文锋引用荀子的名句所表达的价值观几乎一致。
梁文锋与杨植麟的相似性,根植于对AGI的共同信仰。他们都坚信,大模型的能力上限由基础架构与参数规模的持续突破定义,所有的产品体验与商业价值,都要建立在基座模型能力领先之上。这种信仰,让两家公司在技术路线上走出了罕见的协同进化轨迹。
从去年至今,媒体关于DeepSeek与Kimi叙事都是“撞车”,包括发新论文和新模型的架构和参数量。例如DeepSeek V4采用MoE混合专家架构,总参数规模达到1.6万亿,激活参数约370亿。而Kimi K2系列同样采用万亿级MoE架构,总参数1万亿,激活参数320亿。
类似的“撞车”太多。事实上它们远不止“撞车”这么简单,而是已经形成了互相验证乃至彼此复用的默契。
2025年年初,DeepSeek在V3模型中推出的MLA多头潜在注意力机制,通过压缩KV缓存大幅降低了大模型推理成本,成为万亿参数模型落地的核心架构创新。而Kimi在后续的K2系列模型中,直接沿用了这一架构,为其超长上下文与Agent能力的落地扫清了工程障碍。
到了2025年7月,Kimi在万亿参数MoE模型K2中,率先规模化验证自研Muon二阶优化器,官方论文与技术报告确认,其token效率达AdamW的2倍,训练成本降低50%以上,成为全球首个在万亿级别落地的二阶优化方案。
而这次DeepSeek V4的技术报告里显示,也跟进采用了Muon,成为其1.6万亿参数模型训练的核心底座。
两家公司形成的默契,背后是两个创始人的精神共振。梁文锋从量化投资起家,带着“用极致工程能力实现模型效率革命”的底色,DeepSeek从成立之初就坚持用自有资金支撑底层研发,只为不受短期商业目标干扰。
杨植麟出身清华与卡内基梅隆大学,是NLP领域的顶尖学术人才。从创立月之暗面之初,他就定下了“用长上下文能力突破AGI边界”的核心路线,即便在行业流量战最激烈的阶段,也坚持将核心资源投入基座模型研发。
这两个在知春路一带相距1.4公里的男人,忙得也许很少能见到面,但他们可能又是神交已久且最了解对方的那个人。
海外影响力
DeepSeek和Kimi另一个共同点,是在海外的口碑,这也是它们能够吸引投资的重要原因之一。一家一线投资机构在Kimi估值60亿美金的时候进入,后续两轮都选择了跟进。
“模型好,产品好,认知好,全球化做得好,团队反应速度也快。”这家机构参与投资的人士举例称,全球化上最明显的案例就是今年3月国外产品Cursor套壳Kimi。
3月20日,Cursor正式发布新编程模型Composer 2,官方博客全程强调,自研,持续预训练+大规模强化学习,并宣称超越Claude Opus 4.6,价格仅为其1/10。
几个小时后,一位开发者调试Cursor API时,截获内部模型ID:kimi-k2p5-rl-0317-s515-fast。直译为,Kimi K2.5 +强化学习(RL)+3.17版本+快速推理。马斯克下场回复帖子下评论:“Yes, Kimi 2.5!”,全球舆论引爆。
“你就从Cursor训了它的模型就能看出来,Kimi的全球的认知肯定是很好的。”上述投资人说。
自去年发布Kimi K2以来,Kimi几乎每隔两个月就有一次重大发布。同年11月,Kimi推出万亿参数的K2 Thinking大模型,在智能体工具调用能力测试中93%的得分位居全球第一,超过OpenAI、Anthropic 等海外闭源旗舰模型,成为当时 “最大最好的开源模型”。
今年1月推出的K2.5,在多模态、长记忆和智能体上全方位升级,随后借助小龙虾的火热,在技术社区走红。2月登顶海外模型聚合平台OpenRouter,成为周榜调用量冠军。
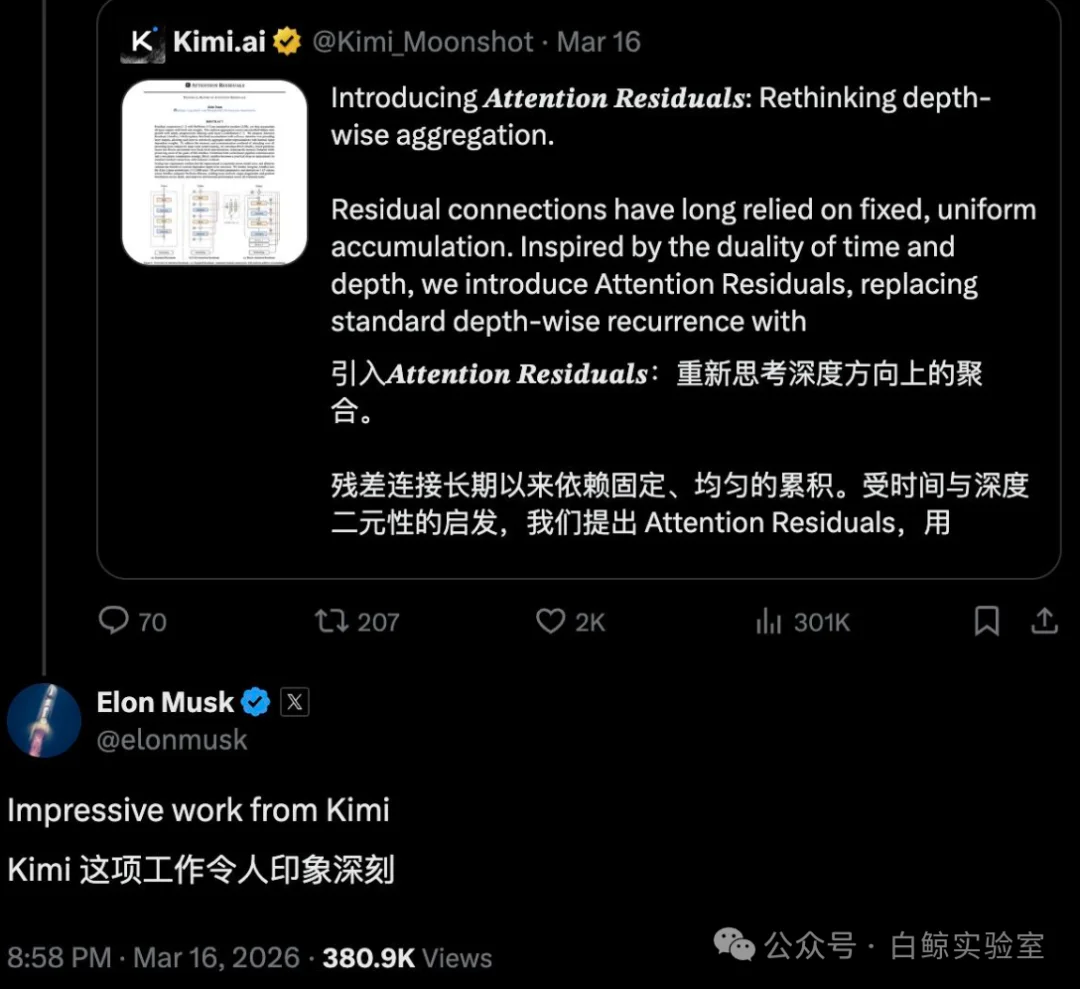
同样在3月,Kimi发布重磅技术报告,被认为挑战了Transformer沿用11年的残差连接机制,前OpenAI研究副总裁Jerry Tworek也评价其为“深度学习2.0”的开端。马斯克转发评论:“Impressive work from Kimi”(Kimi 的工作令人印象深刻)。
DeepSeek的海外影响力自不必多说。去年年初DeepSeek R1就是率先在海外走红的,在一些海外开发者和创业者心中,DeepSeek被奉为开源之神的存在。
本月DeepSeek V4发布后,再次在海外掀起巨量讨论。凭借极致性价比,《彭博》把DeepSeek V4写成对OpenAI和Anthropic的有力挑战。尽管也有不少声音认为,V4的声量完全不如V3带来的冲击。
“对开发者而言,国产开源模型DeepSeek、Kimi和智谱虽然和海外闭源模型相比仍有几个月的差距,但这些模型凭借性价比依然是最能打的。”上述投资人士称。
资本市场对DeepSeek的兴趣也已经达到前所未有的程度。DeepSeek融资,相关报道满天飞,官方一直未回应。
我们独家获悉,DeepSeek融前估值是3000亿人民币,约合440亿美元。DeepSeek计划增资500亿,内部增资200亿,对外募资300亿。这次投资非常隐秘,属于定向邀约,要求也极高。一家一线投资机构因为募资的基金里有许多个人投资人未达标,也被拒之门外。
融资在某种程度上是为了留住人才。此前,DeepSeek多位核心技术人员被高薪挖走。上述DeepSeek人士表示,获得融资对DeepSeek最大好处之一,或许就是人员被挖走的概率降低了。
Kimi同样重视人才。去年12月杨植麟在内部信里称,Kimi账上现金超过100亿元人民币,短期内并不着急上市。他还说,融资是为了更加激进地扩充显卡(GPU)储备,加速下一代K3模型的训练与研发,并将部分资金用于大幅提高员工激励,以吸引和保留顶尖人才。
据今年4月初晚点报道,Kimi将推出一项新的顶尖人才校招计划,拟授予尚未毕业的实习生公司期权,在实习生通过月之暗面为期3到6个月的考察后,计划入选者将被直接授予期权股数,即使本人尚未正式毕业。
大模型的竞赛,是一场资本、人才和算力的全方位比拼。DeepSeek从不融资到宣布融资,Kimi从宣布不着急上市,到账面资金阔绰、到融资数十亿人民币,都反映资本市场已经形成的共识——大模型底层能力跃迁带来的生产力巨量提升,已经非常明确。
大模型投资依旧热
去年9月的外滩大会上,朱啸虎公开演讲称:“大模型已经变成水电煤,是基础设施,没有超额利润,真正的机会在应用。”
目前来看,事情并没有沿着那个方向发展。尤其当智谱和MiniMax上市后,模型热一直持续,两家公司市值一度达到三千多亿和四千多亿港元。
今年以来大模型投资的热度继续高涨,尤其从DeepSeek V4的融资门槛,以及Kimi连续融资并且估值翻了四倍来看。就连大模型存在感不强的阶跃星辰,也在2026年1月26日宣布完成超50亿元人民币B+轮融资。
视频大模型和世界模型同样迎来投资热潮。生数科技在4月完成近20亿元B轮融资,估值120亿元,阿里、中网投领投。极佳视界单月融资25亿元,估值破100亿元。
相比海外,国内这些融资显得小情小调的。OpenAI2026年3月完成高达1220亿美元融资,投后估值8520亿美元,亚马逊、英伟达、软银入局。Anthropic2026年2月完成300亿美元G轮融资,估值3800亿美元,新加坡GIC、Coatue领投。
投资的热潮背后更直观的反应是,模型公司收入增速表现非常乐观。截至4月7日,Anthropic对外披露的ARR是超过300亿美元,较2025年底的收入增长了3倍有余。上述参投Anthropic的投资人告诉我们,“Anthropic的2026年ARR收入预计会突破1000亿美元”。
“大模型作为底层设施,可能会吞噬所有行业的价值黑洞。”上述投资人称,过去一年她频繁的见许多全球最优秀的一批研究员,他们无一例外都向她展示了模型涌现能力已经出现。
看到模型收入增速以及智谱二级市场的暴涨反应,更多的投资人是一种FOMO心理。
据我们了解,最近几个月,Kimi的股权一直很抢手,一家美元基金犹豫了几天名额就满了。
不过,钱对两家公司来说从来都不是目的。梁文锋唯一一次接受采访是在2024年7月,当时他说过这句话:“我们的出发点,就不是趁机赚一笔,而是走到技术的前沿”。这与杨植麟所说的:“不急于短期变现,专注技术前沿与长期AGI目标。”不谋而合。
这份可贵的纯粹,也正是他们持续吸引外界关注的原因。
知春路的风永不停歇,吹过一代代创业者。从PC互联网到移动互联网,中国的科技行业从来不乏流量明星与商业神话,但在AI这条关乎未来的赛道上,或许需要更多的时间来验证新的范式。
文章来自于微信公众号 "白鲸实验室",作者 "白鲸实验室"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
