# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型对齐新方法,让数学推理能力直接提升9%。
上海交通大学生成式人工智能实验室(GAIR Lab)新成果ReAlign,现已开源。

随着以ChatGPT为代表的语言大模型的快速发展,研究人员意识到训练数据的质量才是大模型对齐的关键。
然而,目前主流的提示数据质量的方法不是需要大量人工成本(人工构造高质量数据)就是容易遭受大模型幻觉的影响(从蒸馏数据中选择高质量样本)。
ReAlign能以较小的人工成本提升现有数据集的质量,进而提升模型整体对齐能力,包含数学推理能力、回答问题的事实性、回答的可读性。
目前,该项目开源了大量资源:
该方法有如下优势:
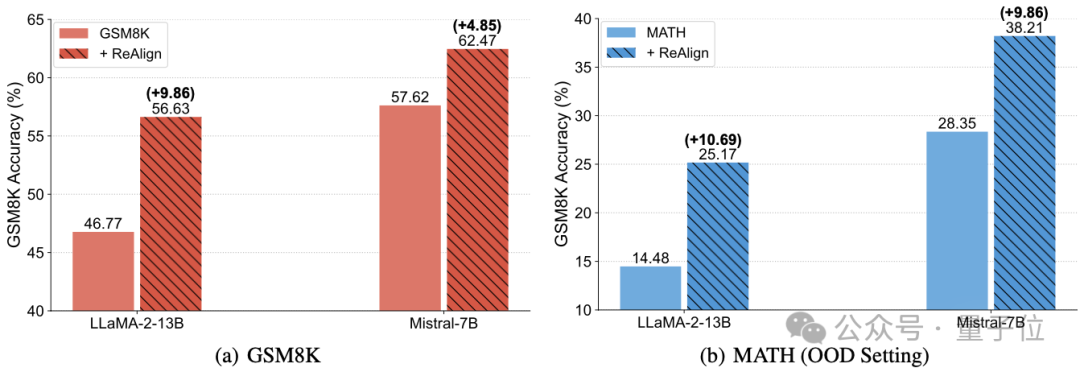
可以显著提升数学推理能力:LLaMA-2-13B在GSM8K上的数学推理能力从46.77%提升到了56.63%。
同时具备显著的OOD泛化能力:在MATH上训练,LLaMA-2-13B在GSM8K上从14.48%提升到了25.17%。
该方法与其他对齐技术(如SFT、DPO、指令数据构造方法等)垂直,即可以在现有技术的基础上去进一步提升大模型性能。
该方法所得到的模型在回答问题时具备更易读、组织格式更优良、原因解释更细致等优点,可以显著提升可读性与数学推理能力。
该方法在针对知识密集型任务时采用了检索增强技术,可以有效提升模型的事实性,减少了幻觉带来的影响。
该文章也指出ReAlign的底层逻辑是重新协调人类与大模型在对齐过程中的角色,利用他们之间互补的优势,让人类去明确指定自己的偏好,而大模型采用自己强大的生成能力去按照人类指定偏好重构回答,并不会蒸馏大模型本身的知识(避免幻觉问题)。
下图示例1展示了ReAlign用于一个数学任务训练数据后的效果,可以看出ReAlign后的回答格式更加清晰易读。

下图示例2展示了采用原始数据集训练后的模型与采用ReAlign的数据集训练后的模型在回答问题上的差异,红色字体高亮了原始回答较弱的部分,绿色字体高亮了ReAlign后的模型回答较强的部分。

该方法流程示意图如下:

该方法分为3个模块:准则定义、检索增强、和格式重构。
该预定义准则包含任务和相应的格式。
任务
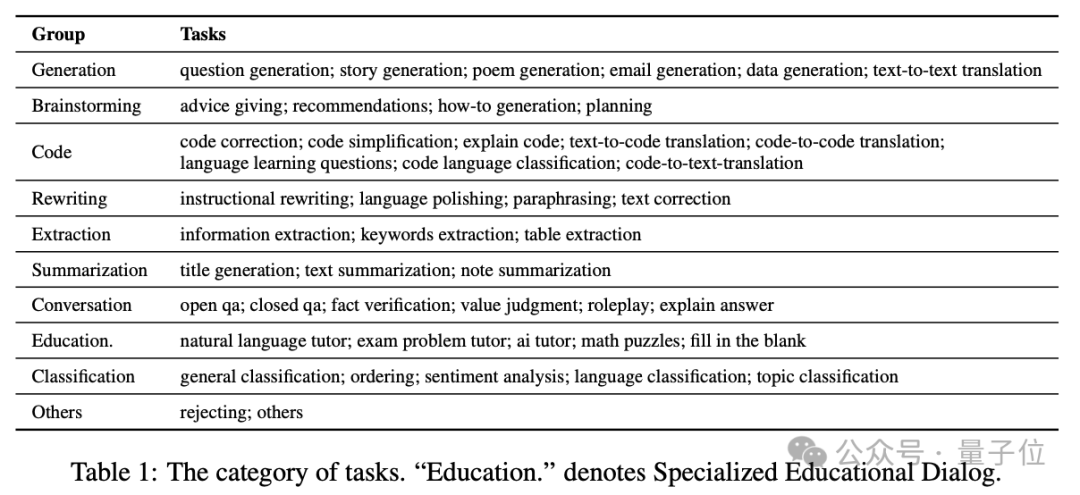
该文章作者人工定义了46个任务,可以归为10个大类,具体分类情况如下表所示:
同时,作者针对这46个任务训练了一个任务分类器。
格式
由于不同任务对于格式的需求是不一样的,因此作者针对这46种任务精心设计了46个回答格式,包含组织结构、章节内容要求和输出形态。这样特定的格式相比通用格式更清晰易读,下表示例为邮件生成任务的格式:

知识密集型任务如开放域问答和事实验证任务,需要大量外部知识作为证据来确保回答的事实性。
因此作者选择了5个知识密集型任务,针对这些任务的问题,先去调用谷歌搜索的API得到对应证据,用于后续改写。以下是一个检索增强的示例,可以看出有了检索增强后的ReAlign可以给出具备事实性的详细解释:

重写
作者利用大模型(比如ChatGPT)基于之前定义的准则和检索到的证据(对于知识密集型任务)来重新改写原数据集中的回答。具体来说,是通过提示将问题、原始回答、格式要求和证据(对于知识密集型任务)进行组织,然后询问大模型得到重写后的回答。此外,由于一些问题有特定的格式要求,因此作者采用了自适应改写,即先让大模型判断该问题与给定的格式是否匹配,若匹配则改写,否则保留原始回答。
此外,作者认为一些特定任务不应有特定格式要求,例如故事生成、诗歌生成等,因此作者对这类任务并没有采用格式重构(具体可看论文)。
后处理
长度过滤:作者发现大模型在改写回答的时候偶尔会只输出做了改变的句子,这种情况下长度会锐减。因此,作者将改写后长度小于原始回答一半的数据保留其原始回答不改变。
基于任务的过滤:作者发现任务分类器有时候会导致错误传播,因此针对以下3个任务设计了特定过滤规则:
作者在5个数据集(Open-Platypus、No Robots、Alpaca、GSM8K、MATH)和2个模型(LLaMA-2-13B和Mistral-7B)上做了实验。
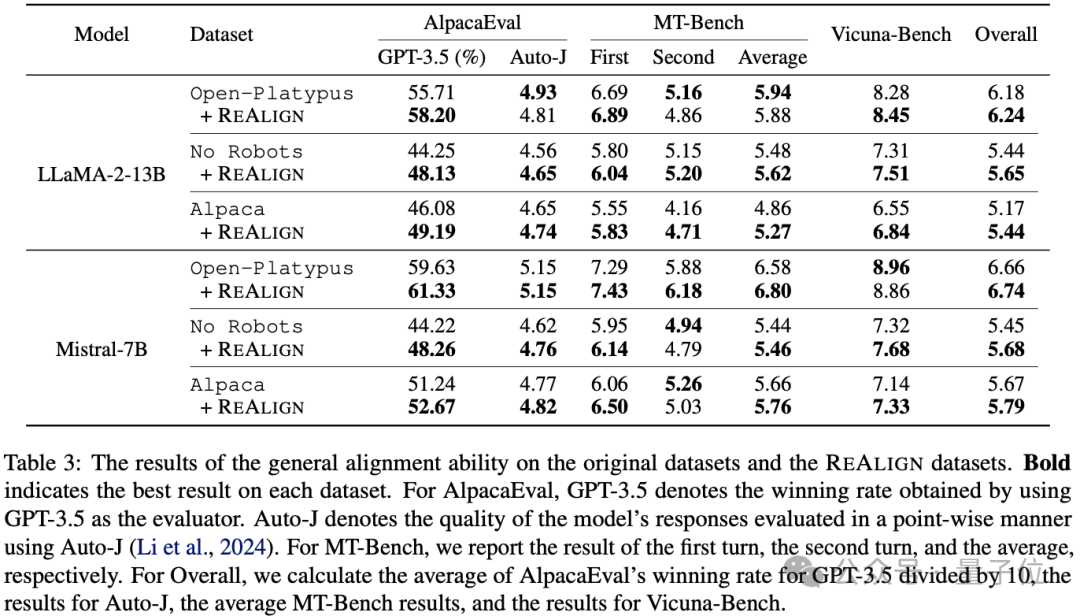
作者首先在AlpacaEval、MT-Bench、Vicuna-Bench上测试了通用对齐能力,结果如下表所示,发现除了部分MT-Bench的第二轮对话性能下降,其他均有提升,证明了对回答格式重构可以有效提升对齐能力。
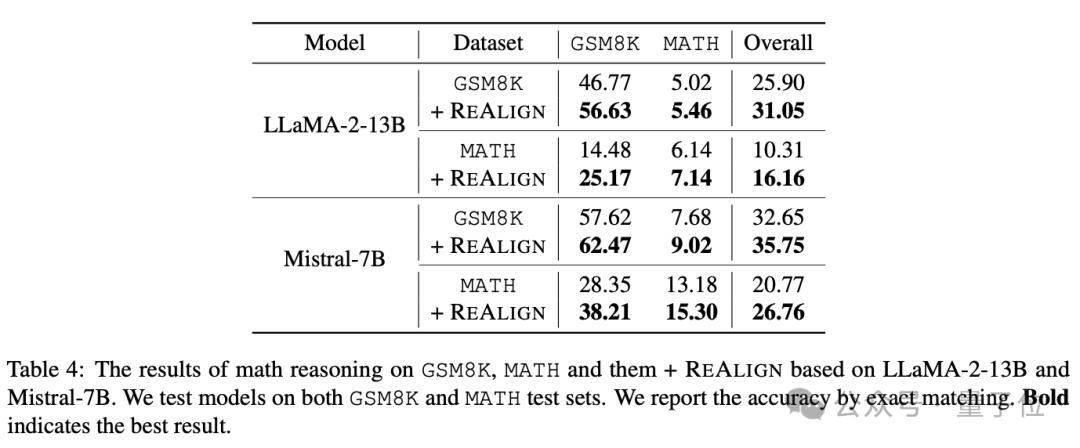
随后,作者测试该方法对数学推理能力的影响,其在GSM8K和MATH两个常用数学数据集上进行测试。结果如下表所示,可以看到该方法可以显著提升数学推理能力,甚至可以得到9-10个点的提升。
此外,还具有显著的OOD泛化能力,例如LLaMA-2-13B在MATH上训练,在GSM8K上测试可以提升10个点以上。作者认为这样的提升可能是因为格式重构后带来了更多以及更清晰的中间步骤和解释,进而提升了模型的数学推理能力。
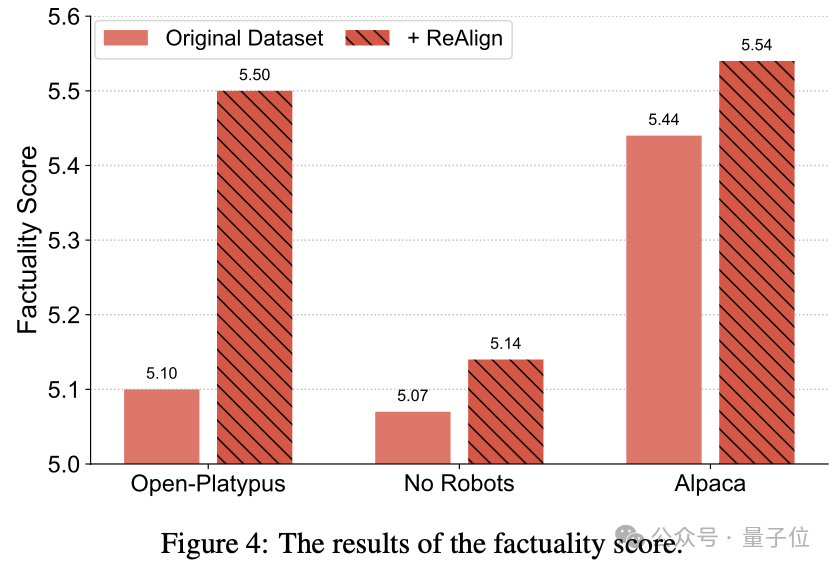
接下来,作者构造了一个评测标准去测试模型的事实性(Factuality),他们从带有正确答案的NQ数据集中随机筛选了100条数据。
随后用训练好的模型去回答这100个问题,得到模型的回答,接下来采用一个提示模版将问题、答案和模型的回答组织起来,让GPT-4为该回答与正确答案的符合程度进行打分作为事实性分数。
测评结果如下图所示,可以看到在这三个数据集上事实性均有提升,作者认为是检索增强带来的效果。
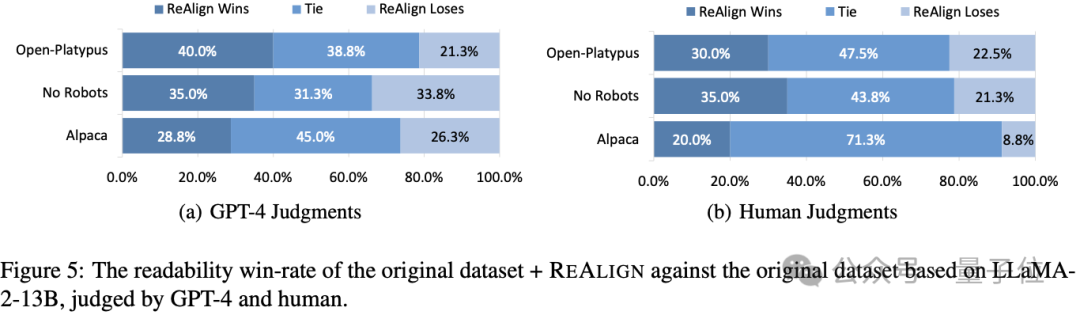
此外,作者还测试了模型的可读性(Readability),他们针对Vicuna-Bench的回答,采用GPT-4和人工评估对用ReAlign前后的回答进行一对一可读性比较。
结果如下图所示,可以看到无论是GPT-4还是人工,ReAlign后的数据集相比原始数据集均有显著提升。
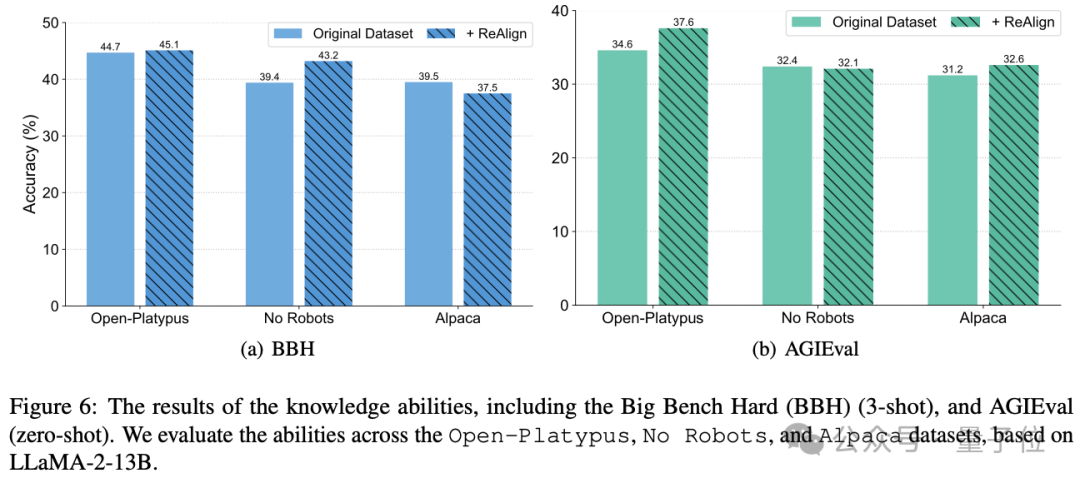
作者还进行了对齐税(Alignment Tax)分析,在知识型评测基准BBH和AGIEval上进行测试,发现采用ReAlign后的模型并不会损失其原有的知识,并且在个别情况还会有提升。
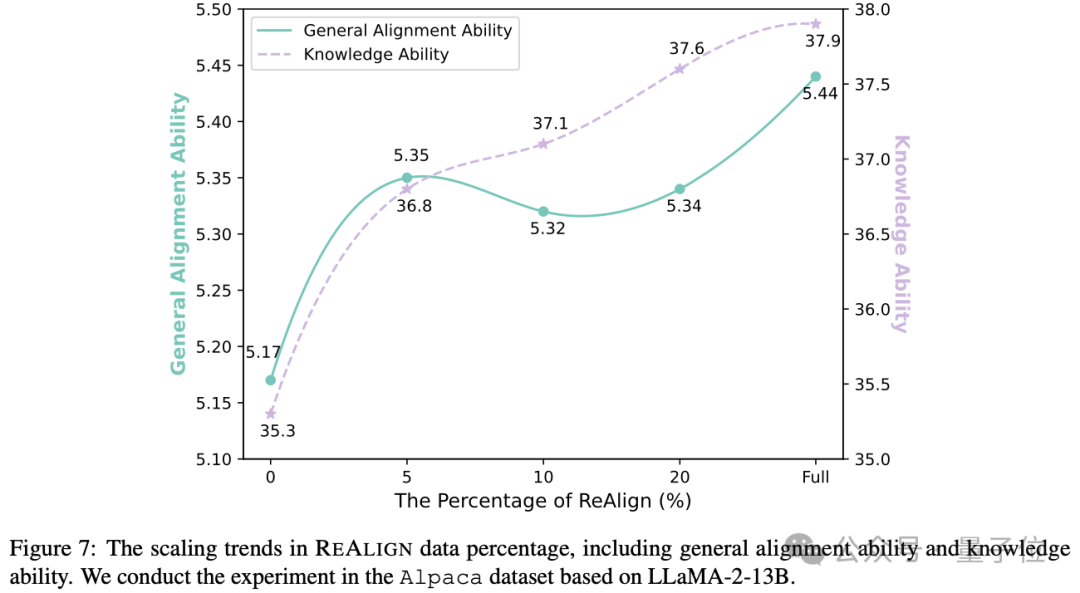
最后,作者分析了ReAlign的扩展定律(Scaling Law),即只ReAlign一部分数据,对训练后的模型的影响情况。
结果如下图所示,可以看出只ReAlign 5%的数据即可为通用对齐能力带来全部ReAlign的67%提升,并且随着ReAlign的比例提升性能也呈上升趋势。
总的来说,GAIR研究组提出了一个新的对齐方法ReAlign,其可以自动化提升现有指令数据集的回答质量,并且最小化了人工成本和幻觉影响。
他们ReAlign得到了了5个新的高质量数据集Open-Platypus、No Robots、Alpaca、GSM8K和MATH。实验证明,ReAlign可以显著提升通用对齐能力、数学推理能力、事实性和可读性,并且不会损害知识能力。
此外,也公开了数据集、人工精心撰写的46种任务描述及格式、任务分类器及其训练数据、事实性评估数据集。
论文地址:https://arxiv.org/pdf/2402.12219.pdf
项目地址:https://gair-nlp.github.io/ReAlign/
代码与数据地址:https://github.com/GAIR-NLP/ReAlign
文章来自于微信公众号“量子位”(ID: QbitAI),作者 “Pengfei”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
