# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
智能体现在能hold住越来越多复杂任务了,但问题仍然不少。
比如,多智能体协同做视觉任务,常常轮次越多错得越离谱——根源不在模型能力不够,而在于智能体之间传递视觉信息的方式本身就有缺陷。
来自新加坡国立大学LV-Lab及其他国内外科研机构的研究人员关注到:
基于视觉语言模型(VLM)的多智能体系统(MAS)正成为复杂多模态协作的核心方案,却被一个致命痛点死死卡住:多智能体视觉幻觉滚雪球——单个智能体的视觉误判通过纯文本信息流逐级放大,早期细微错误最终演变成系统性崩溃。
此前方案几乎只聚焦「单智能体幻觉抑制」,根本无法阻断跨智能体的错误传播。长轮次协作中,模型性能被幻觉“滚雪球”越拖越垮。

针对这一难题,他们提出了 ViF(Visual Flow),一种轻量通用的视觉流范式。用「视觉流 + 注意力重分配」重构智能体间视觉传递逻辑,无需改造基座模型即可大幅压制幻觉滚雪球。
该工作已入选ICLR 2026,在8大基准、4种MAS结构、10款主流VLM上实现稳定提升。
当前 VLM 多智能体协作,全程依赖文本流传递视觉信息,这一设计存在两大无法规避的缺陷:
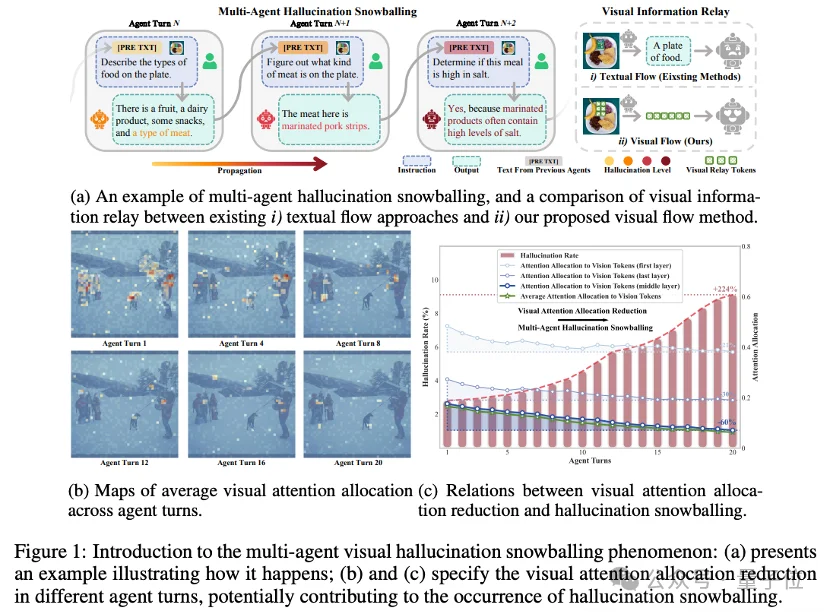
此前优化方案几乎都只聚焦「单智能体幻觉抑制」,无法阻断跨智能体的错误传播;在长轮次协作中,模型性能可能会被视觉幻觉的“滚雪球”拖累,可能导致无法胜任复杂视觉任务。
研究团队从轮次、层级、令牌三个维度做深度注意力拆解,首次系统性的探究了幻觉滚雪球的本质:
1. 随智能体轮次增加,视觉令牌平均注意力分配在第20轮暴跌 62%,中层视觉注意力峰值直接消失;
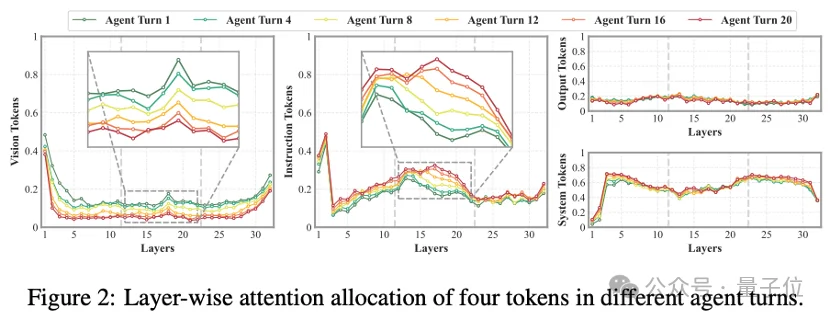
2. 中层单峰注意力视觉令牌是保存原生视觉证据的核心载体,对视觉理解起决定性作用;
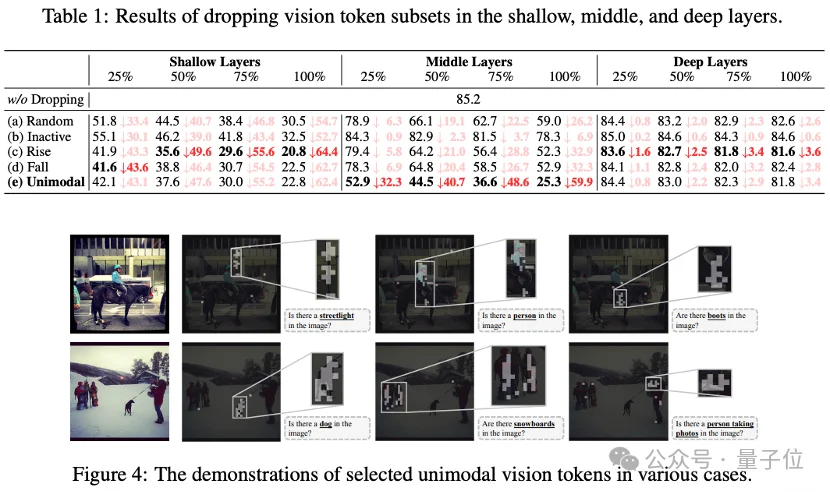
3. 这类关键令牌占比从首轮 1.22% 骤降至第20轮 0.10%,视觉信息彻底被
文本信息压制。
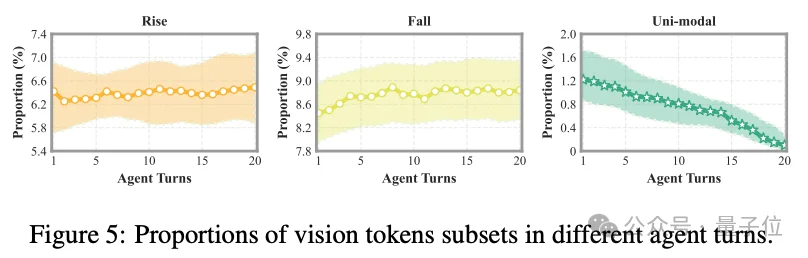
这些核心发现,为精准修复视觉信息流提供了最关键的依据。
ViF彻底抛弃「纯文本传视觉」的逻辑,打造即插即用、模型无关的轻量「视觉直接传递」范式,两大核心设计直击痛点:
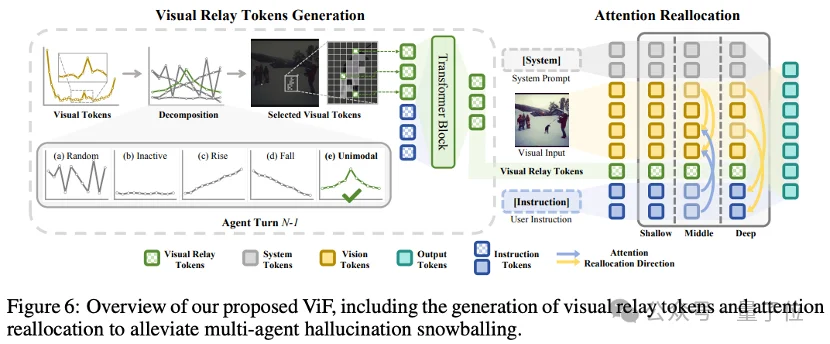
此外,FlashAttention 兼容方案针对现代模型常用的 FlashAttention 2/3(无法获取注意力分数),设计Key-Norm 替代策略,兼顾效率与落地兼容性。该团队提出的方法开销较小,且可无缝适配不同 VLM 与 MAS 结构。
ViF 经过了全面的实验验证:
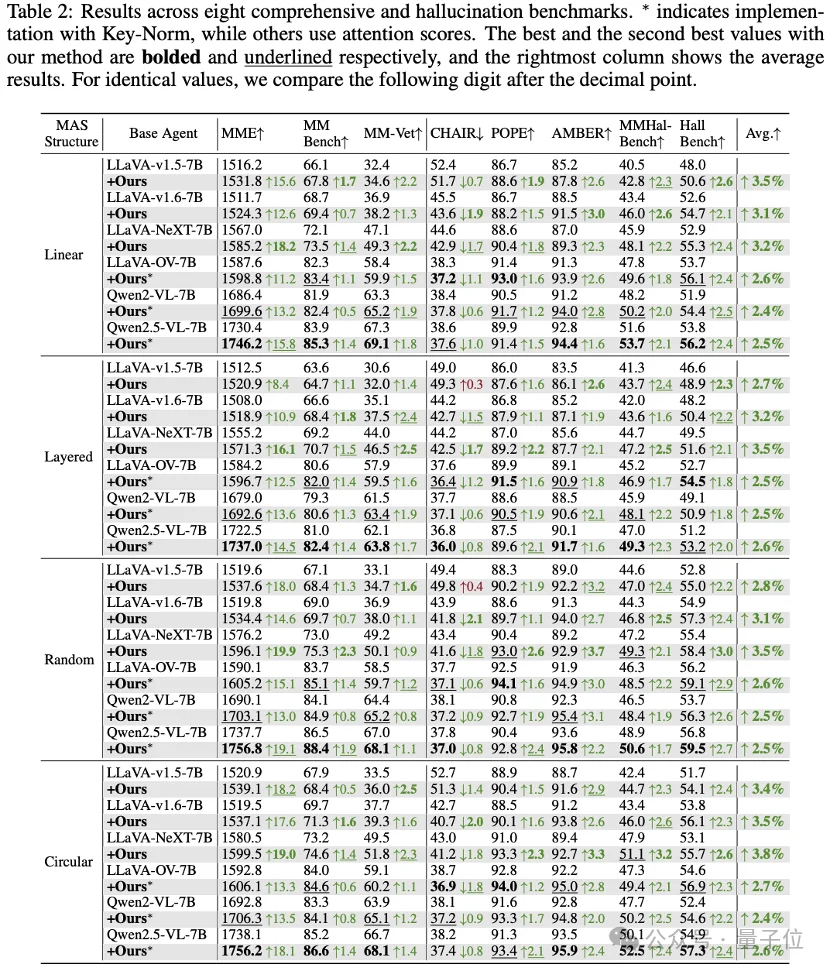
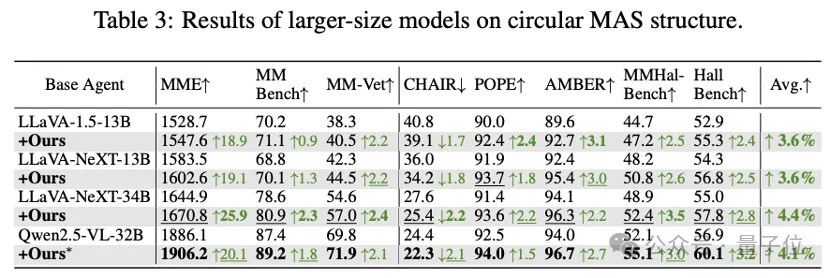
对比5款SOTA单智能体幻觉方案,ViF在多智能体场景下实现断层式领先:传统方案只从单智能体出发,ViF从底层切断视觉幻觉传播,显著抑制多智能体幻觉滚雪球。
ViF 是业内首个从信息流重构层面解决多智能体视觉幻觉滚雪球的方案,直接打破长轮次协作「越做越错」的魔咒,它用较小的代价,建立了智能体间的视觉流信息传递,让多智能体协作真正可信、可用。
论文:https://arxiv.org/pdf/2509.21789
代码:https://github.com/YU-deep/ViF
文章来自于微信公众号 "量子位",作者 "量子位"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
