# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
想知道 Zephyr-7B,TinyLLaMA、OLMo、Solar 等明星大模型背后的奥秘吗?
好数据,才有好模型。
迄今,全球超 200 个模型基于来自 OpenBMB 开源社区的 Ultra Series 数据集(面壁 Ultra 对齐数据集)对齐,数据集包括 UltraFeedback 和 UltraChat,共计月均下载量超 100 万。
数据集的品质怎么样?要看大模型的真实战斗力。
在一些「以小博大」的大模型经典对战中,常可以看到 Ultra Series 数据集(面壁Ultra 对齐数据集)的身影,可以说经过了全球大模型的真实验证。
例如, 在 Ultra Series 数据集的加持下,Zephyr-7B 以更小规模,在不少指标上超越了 LLaMA2-70B-Chat;它亦帮助「大模型中的小钢炮」面壁 MiniCPM-2B 取得与 Mistral-7B 一较高下的惊艳表现。
▾ 传送门 Models Trained on Ultra Series
20+基于 OpenBMB Ultra 系列高质量数据集训练的开源模型
???? https://huggingface.co/collections/openbmb/models-trained-on-ultra-series-65e6c7552c9682c47217731d
▾ 传送门 Ultra Series
???? https://huggingface.co/collections/openbmb/ultra-series-65d490fedc2727f5807f4688
Ultra Series:领先的对齐技术
为什么对齐技术如此重要?可以说,这是 AGI 进程中最重要的工作之一。
就像给大模型带上“紧箍咒”,使其目标、价值观、利益等与人类的相一致,并符合设计者的预期,避免产生超出控制的有害后果。
来自 OpenBMB 开源社区的 Ultra Series 对齐技术(面壁 Ultra 对齐)集成了一系列大模型对齐(Alignment)世界领先成果,由面壁智能与清华 NLP 实验室共同支持,目前包括高质量数据集 UltraFeedback、UltraChat 和大语言模型UltraLM、UltraRM、UltraCM 等。
Ultra Series 数据集的构建基于团队首次提出的“可扩展多样性”原则。
团队认为,数据集规模的持续可扩展与数据中指令和回复的多样性决定了数据的质量。为了实现数据集规模的扩展性,团队在数据集构造全程摒除任何人工干预,整个数据集全部由大模型自动构建。而为了提高多样性与数据质量,团队也设计了一系列方法(详见 UltraChat 与 UltraFeedback 的论文)。
UltraFeedback 是首个大规模通用AI反馈数据集, 首次验证了偏好对齐在开源大模型上的效果。这一大规模、多样化、细粒度的偏好数据集,包括 25 万条对话数据以及相应的偏好标注数据。在非社区标注的偏好数据集中,这一数据规模排在首位。并且,其中每条偏好标注均包含四个方面的细粒度得分与详细的文字说明。
UltraChat 是高质量的对话数据集,包含了 150 余万条多轮指令数据。调用多个 ChatGPT API 相互对话,从而生成多轮对话数据。
▾ 传送门 UltraChat 论文地址:
???? https://arxiv.org/abs/2305.14233
▾ 传送门 UltraFeedback 论文地址:
???? https://arxiv.org/abs/2310.01377
为了验证数据集的品质,团队基于 UltraFeedback 训练了一个奖励模型和一个批评模型来进一步辅助模型评测和模型反馈学习:
如同大模型老师一般对正确回答给予积极的正向激励,并给出答案好在哪里、不好在哪里的具体点评,使模型得以针对性提升。
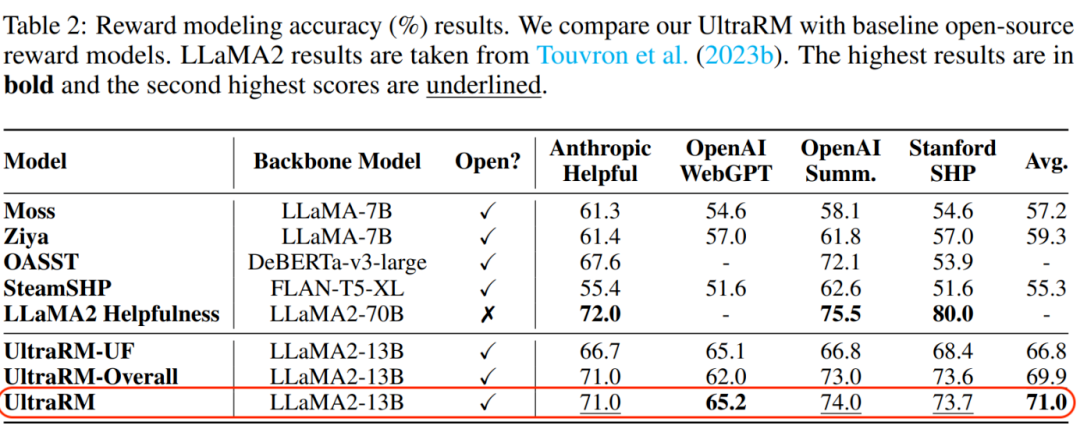
UltraRM奖励模型(Reward Model)旨在区分同一个问题不同回答的好坏。在四个公共偏好测试集上,UltraRM 显著超过其他开源奖励模型,达到了 SOTA 的性能。
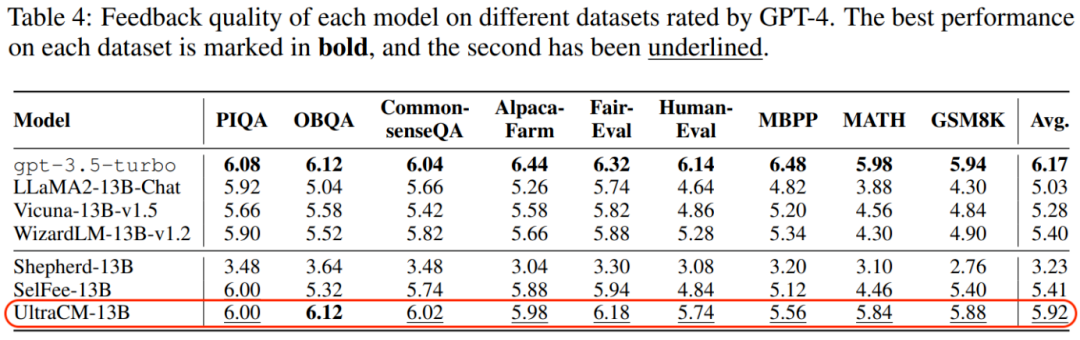
UltraCM批评模型(Critique Model)用于自动生成文本形式的反馈。在 9 个基准数据集上,UltraCM 优于所有开源 baseline,性能接近 ChatGPT。
此外,团队还基于 UltraChat 数据训练了 UltraLM(Language Model),它具有丰富的世界知识和超强的指令理解和跟随能力,能对各类问题/指令给出具有丰富信息量的回复。
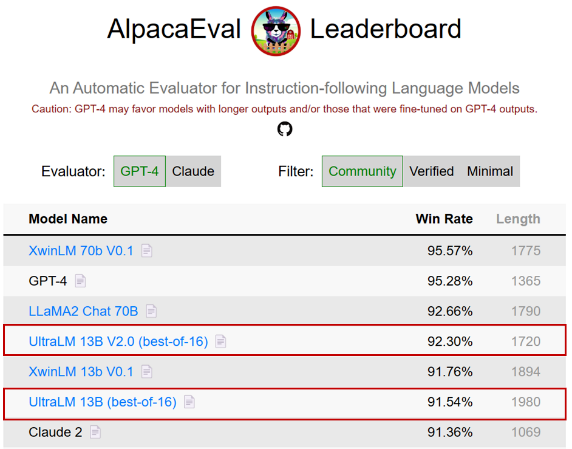
其中,UltraLM-13B-v1.0 发布时登顶斯坦福 AlpacaEval* 开源模型榜单,UltraLM-13B-v2.0(best-of-16 采样)在 AlpacaEval 榜单取得了 92.30% 的好成绩,成为 70B 以下模型最高分。
推动全球大模型对齐研究
在对齐技术流程中,偏好对齐举足轻重。
一些研究提出了基于人类反馈的学习方法,包括基于人类反馈的强化学习 (RLHF),已被 OpenAI、Anthropic 和 Google DeepMind 等业界领先公司广泛研究并应用。
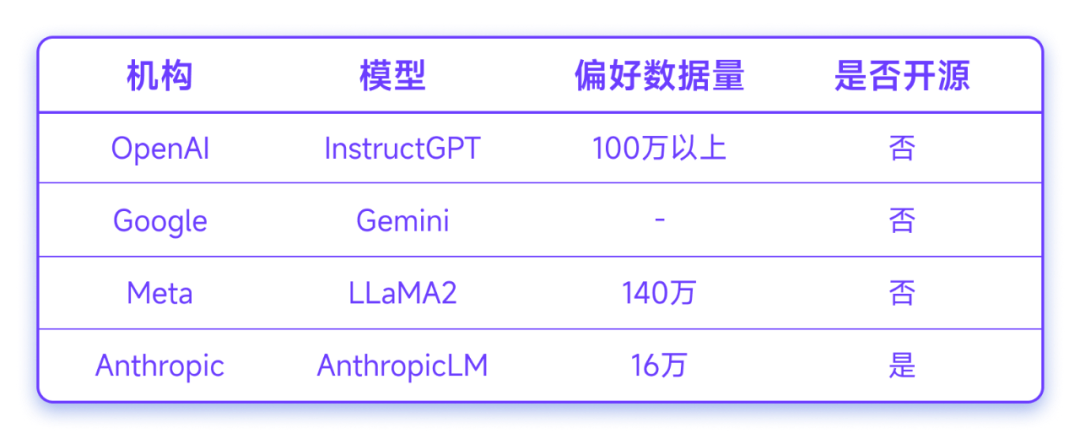
传统偏好对齐数据依赖人工标注,头部公司均收集了几十万上百万的偏好数据,却鲜有开源。
由于缺乏高质量、公开可用的偏好数据集,开源社区在 RLHF 的研究和实践上仍然处于落后状态。
Ultra Series 对齐技术(面壁 Ultra 对齐)为全球开源社区做出了积极贡献,广受赞誉。
Hugging Face 在 2023 年度总结上重点提及了来自 OpenBMB 开源社区的「UltraSeries 对齐数据集」,评价其为开源社区发展进程中的重要一笔。

NLP 大牛、HuggingFace 联合创始人 Thomas Wolf 也在推特上发了一篇长文,讲述了一个 Mistral + OpenBMB + HuggingFace 跨越三大洲的大模型开源合作的故事, “全球三大洲的人们公开合作,共同打造出一个新颖、高效且前沿的小型 AI 模型” 。
来自 OpenBMB 开源社区的 Ultra Series 对齐数据集,在 Zephyr 模型的成长故事中扮演了关键角色。研究模型微调和对齐的 H4 团队表示:使用 OpenBMB 两个数据集训练出来的新模型非常强大,是 H4 团队 在伯克利和斯坦福的基准测试中见过的最强模型。
这创造了一次开源神话。
如 Thomas Wolf 所言,世界各地(欧洲、加利福尼亚、中国)对知识、模型、研究和数据集的开放获取,以及人们在AI上相互建设、相互借鉴,共同创造出真正有价值的高效开放模型的理念。
OpenBMB 开源社区将持续推动大模型技术开源,致力于让大模型飞进千家万户。
文章来自于微信公众号 “OpenBMB开源社区”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
