# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
世界上第一个「ChatGPT机器人」来了!
初创公司Figure联合OpenAI,现在直接给LLM造了个身体(具体来说,它是个OpenAI训练的多模态大模型)。
半个月前刚获得OpenAI等的6.75亿美元融资,今天初创公司Figure就来交卷了,简直神速。

这个名为Figure 01的机器人,充分展示了和人类以及环境交互的能力。它会说会看,还能给人类递食物、捡垃圾、收拾碗筷。
不仅如此,它还能够推理,自行识别、计划和执行有用的任务。

在这个过程中,由OpenAI提供视觉推理和语言理解,Figure 01的神经网络,会提供快速、低等级、灵巧的机器人动作。
OpenAI和Figure Robotics放出的这段演示,瞬间震惊了网友:大模型和真实物理世界的距离,越来越近了!
此前Midjourney创始人预测:2040年,将会有10亿机器人,2060年将有一百亿,马斯克表示同意
这段视频可谓亮点满满。
首先,视频是1.0倍原速拍摄的,而且是连续拍摄,跟之前那些为了表现流畅而加速的人形机器人演示不一样。
其次,整个视频只了一个端到端的神经网络。
并且,机器人背后,并没有人在远程操作,所有动作都是由机器人自行完成的!
现在,压力给到了波士顿动力和马斯克的擎天柱这边。

视频中的小哥问它:「Figure 01,你看到了什么?」
思索几秒后,它张口说话了:「我看到桌子中间的盘子中,放了一只苹果,沥水架上有几个盘子和一个杯子。我还看到你站在旁边,你的手放在桌子上。」

小哥接着问:「我能吃点东西吗?」
Figure 01回答:「当然!」然后抬起手,拿起一个苹果递给他。
下面,更高能的来了!
小哥直接把一堆垃圾哗啦啦倒在Figure 1面前,然后问它,你能不能一边给我解释下刚才为什么会这么做的原因,一边把这些垃圾收拾干净呢?
Figure 01一边有条不紊地把筐子拉到自己面前,把垃圾一个个捡进筐子里,一边回答道,「我给你苹果,是因为这是我在桌上唯一看到的能吃的东西」。

接下来,小哥又向Figure 01发出了灵魂拷问:「根据你眼前所见的场景,你觉得你眼前的这些盘子应该放到哪里呢?」
Figure 01自信满满地表示:像桌上这些盘子啊杯子啊,应该放到旁边的沥水架上。
小哥表示,那你就帮忙放一下吧?五秒后,Figure 01抬起右手,用敏捷灵活的动作,一个一个地把盘子和杯子放到了该放的地方。
最后,小哥还让Figure 01给自己的表现来个复盘:「你觉得你表现得如何?」
Figure 01很满意地说:「我觉得我做得很好,我把苹果递给了你,把垃圾丢掉了,桌上的东西也都放到了该放的地方。」
小哥向它表示了感谢后,Figure 01甚至还伸开双臂,耸了耸肩,表示有什么忙要帮的,欢迎随时来找我。

看到这一幕的网友们,纷纷表示惊叹。
看起来,AGI可能在六个月内就会到来了,甚至更短!
波士顿动力只能再多编一些舞蹈花样了,不然真的打不过。????

这就是世界上第一个终结者?
有人表示,让LLM机器人帮忙洗碗和打扫房子,就是最正确的事。不然总不能让它们成天吟诗画画吧……
「Figure 1,在我出门时,请你帮我打扫房子、洗碗、遛狗,你可以看《终结者2》,但是不要产生任何疯狂的想法,ok?」
如果对话再流畅一些,处理速度再快上100倍,那我们就会得到一个工作产品。

另外还有人吐槽了Figure 01的声音,为啥搞得像一个50岁的吸烟人士……
Figure CEO则表示,机器人的声音,是对文本转语音的AI进行了微调,还让大家猜猜是谁。
这家机器人初创公司Figure,囊括了波士顿动力、特斯拉、谷歌DeepMind和Archer Aviation的前员工。成立不到两年,它已经估值26亿美元。
和OpenAI的首次合作亮相,就如此惊艳。
显然,在机器人领域,人工智能时代才刚刚开始。
OpenAI的产品与合作副总裁Peter Welinder表示:"我们一直计划重返机器人领域,我们看到了与Figure合作的价值。我们想探索,在高性能的多模态模型驱动下,人形机器人能实现什么样的目标。」
如今,人形机器人再次引起了投资者兴趣,因为大模型驱动的软件,为机器人与人类的互动提供了更多可能性。
特斯拉CEO马斯克预测,在2040年,地球上将出现10亿个人形机器人。
话说回来,被看Figure 01的这些操作看似容易,背后可是满满的玄机。
Figure AI的创始人Corey Lynch亲自在X解释了Figure 01的工作原理。
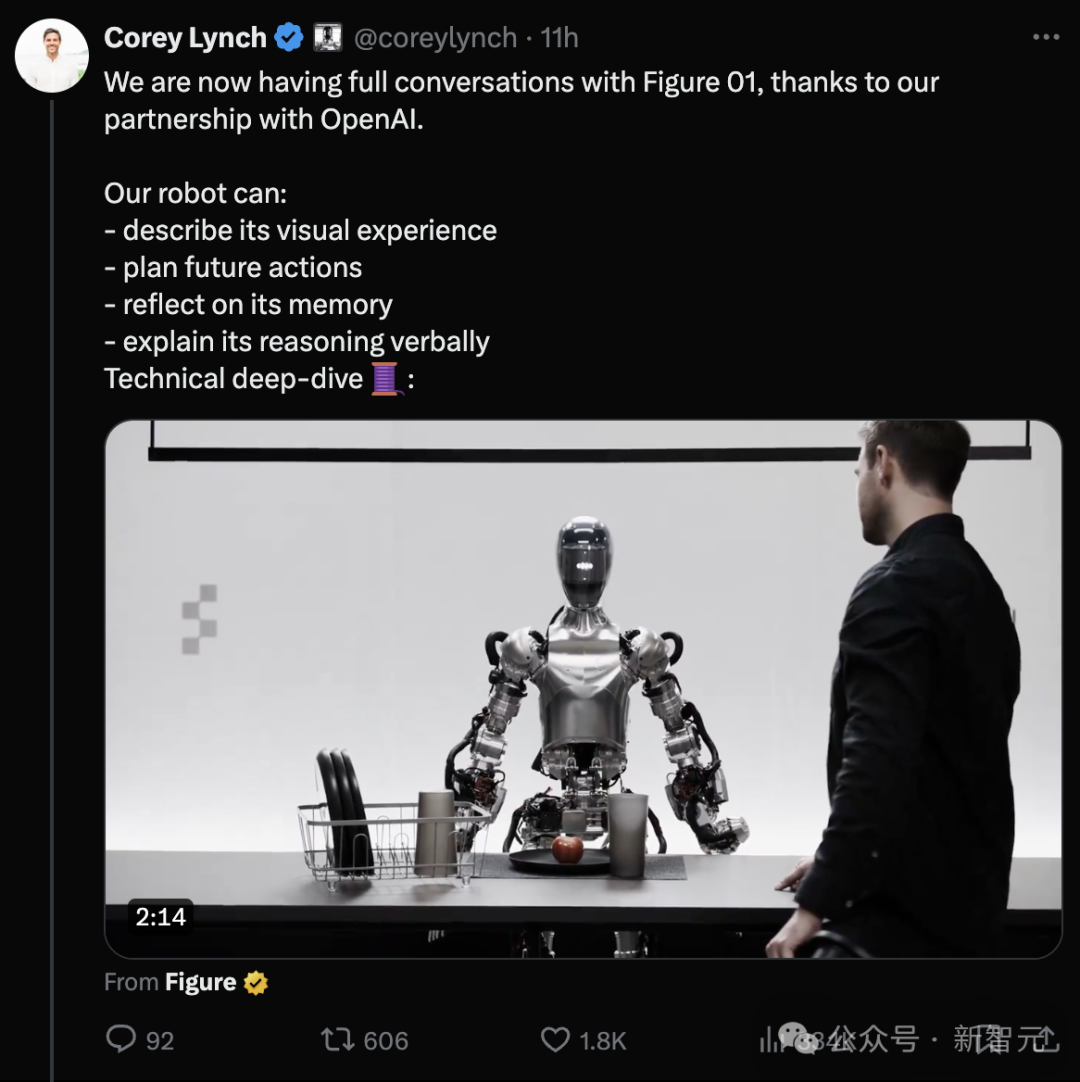
Figure 01现在能够做到:
- 描述它看到的一切情况
- 规划未来的行动
- 思考输入的视觉和文字信息
- 语音输出它的推理结果
放出的这个视频中,所有的行为都是学习的(不是远程操作的),并且没有加速播放。
如下图所示,Figure AI用机器人摄像头采集的视频信息,加上麦克风捕获的语音中的文本转录到由OpenAI提供的多模态大模型中,理解图像和文本。
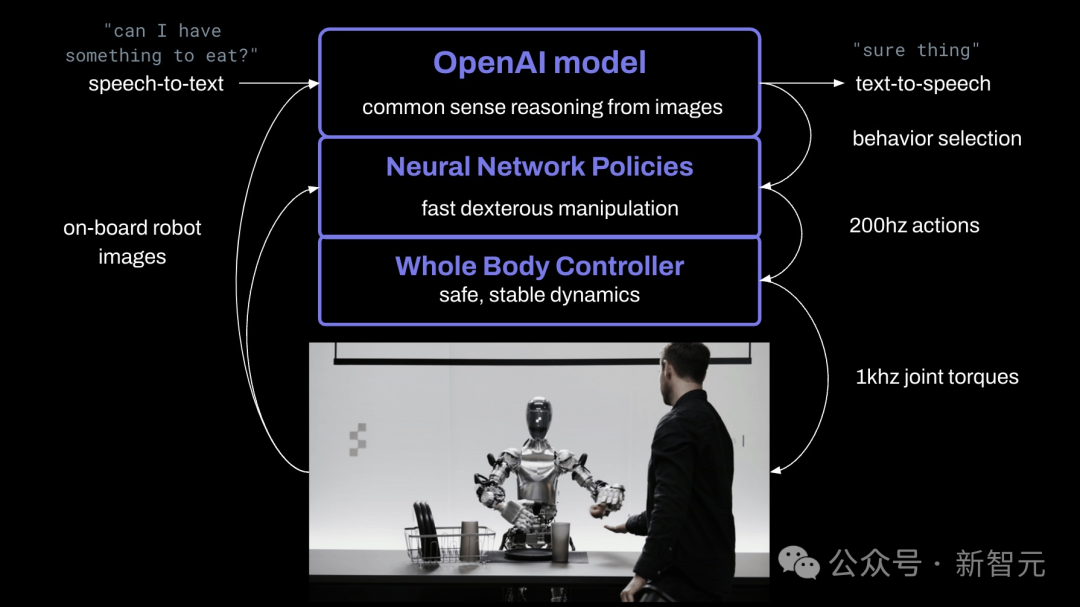
模型能够处理对话的完整记录,包括之前的历史视频,得到语言响应,然后通过文本到语音的方式传回给人类。
同时模型还负责规划机器人运行哪些学习的闭环行为来完成给定的命令,将特定的神经网络权重加载到GPU上并执行策略。
将Figure 01连接到完成预训练的多模态模型,为其提供了一些有趣的新功能。
Figure 01在OpenAI的大模型的加持下可以做到:
- 描述机器人周围的环境;
- 决策时使用常识推理。比如,「餐桌上的盘子和杯子很可能之后要放到烘干架上」;
- 把「我饿了」这样模棱两可的高层次请求转化为「递给对方一个苹果」等与具体情况相适应的行为;
- 用通俗易懂的英语描述为什么它执行某个特定的动作。例如,「这是我能从餐桌上为你找到的唯一能吃的东西」。

理解对话内容的大模型为Figure 01提供了强大的短期记忆。
比如,如果人类提出问题:「你能把它们放在那里吗?」 「它们」指的是什么?「那里」又在哪里?正确回答需要机器人拥有思考记忆的能力。

通过预训练的模型分析对话的图像和文本历史记录,Figure 01可以快速形成并执行规划:
1)将杯子放在晾衣架上;
2)将盘子放在晾衣架上。
所有行为均由神经网络视觉运动Transformer进行策略驱动,将像素直接映射到动作。
神经网络以10hz的频率接收机器人拍到的图像,并以200hz的频率生成 24-DOF动作(手腕姿势和手指关节角度)。
这些动作作为高速「锚点(setpoints)」,供更高速率的全身控制器跟踪。
不同的部分各司其职:
- 云端的预训练模型对图像和文本进行常识推理,以得出高级规划;
- 学习的视觉运动策略执行规划,执行难以手动指定的快速反应行为,例如把一个袋子折叠成任何需要的形状;
- 同时,全身控制器确保安全、稳定的动作。例如,保持平衡。

最后Corey Lynch强调,即使就在几年前,业界都认为人形机器人进行规划和执行自己学习的行为,以及与它进行完整的对话的场景,将是几十年之后才会发生的事情。
显然,因为大模型的出现,一切都被加速了。
Figure AI是目前将AI能力延伸到现实世界中做得最好的地方。
半个月前,这个消息就在AI圈内传开了——
人形机器人初创公司Figure,获得了OpenAI等公司的6.75亿美元融资!
参与融资的其他公司,包括OpenAI创业基金、亚马逊工业创新基金、Parkway风投公司、英特尔投资公司、Align风投公司和ARK投资公司。
OpenAI给Figure投钱,当然也是想下一盘大棋。
Figure的创始人兼首席执行官Brett Adcock表示,公司将利用这笔资金开发用于机器人技术的大型语言模型,扩大生产规模,并雇佣更多员工。
现在,Figure的演示已经显示了,他们在人形通用机器人的交互上,做出了重大飞跃的产品。
史上第一次,机器人在没有操控的情况下,和人如此自然地互动,并且能够服从人类。如此流畅的演示,此前的公司都没有做到。
当然,Figure 01目前只是一个原型,如果要进行商业部署,出售给企业,会需要更多的工作。
不过,Adcock已经表示,Figure的目标就是训练一个世界模型,来操作十亿单位级的人形机器人!
在Figure的网站上,Adcock介绍了Figure的总体规划——
Figure的目标是:开发对人类产生积极影响的通用类人机器人,并为子孙后代创造更美好的生活。这些机器人可以消除对不安全和不受欢迎的工作的需求,最终让我们过上更快乐、更有目的的生活。

Adcock表示,公司接下来还要艰苦奋斗几十年,需要一支冠军团队、数十亿美元的投资和工程创新。「我们的风险极高,成功机会极低」。
同时,他还宣称——

我们不会将人形机器人用于军事或国防应用,也不会将其用于任何需要对人类造成伤害的角色。我们的重点是为人类不想从事的工作提供资源。
现在,随着LLM的进步,全世界机器人都疯狂开卷了!
除了特斯拉的擎天柱Optimus,与亚马逊合作的人形机器人初创公司Agility,还有刚挖来前Optimus科学家领导开源机器人项目的Hugging Face,以及昨天刚成立的初创公司Physical Intelligence。
成立不到两年,Figure就成为估值26亿的独角兽,是连续创业者Brett Adcock成立的第3家公司。

1986年出生的Brett Adcoc,目前仅有38岁,从2012开始至今,创立了3个科技公司:
26岁的他在2012年就试图使用AI来革新招聘行业。
当时,他成立了Vettery——一个在线猎头平台,不到一年的时间团队迅速发展到数百名员工,客户网络扩大到30000家招聘公司。
Vettery人工智能系统每月匹配20000次面试,帮助数千人找到他们梦想的工作。
在成立1年多后,他就以1亿美元的价格将公司卖给了Adecco。

而他在2018年成立的第二家公司Archer,主营业务是制造可以垂直起降的电动飞机,解决在繁忙城市中无法使用飞机的问题。

不到5年的时间,Archer就以27亿美元的估值成功登录纽交所,成为了飞机行业中的特斯拉。

而在2022年,他成立的第三家公司Figure,希望能够用人形机器人彻底改变人类的工作方式。让人类无需再出现在那些危险而不适合人类的工作场所之中。

在Brett Adcock的眼里,Figure有可能成为世界上影响力最大的公司。
他白手起家,10年间成立的3家公司,分别达成了「亿元卖身」,「纽交所上市」,「2年成长为独角兽」3大成就,实在是令人咋舌。
而且纵观他成立的3家公司的过程和所涉及的行业,和前世界首富马斯克颇有相似之处。
而现在他的Figure AI更是直接与特斯拉的展开了竞争。
如今科技巨头纷纷「用钱投票」,一方面确实是因为人形机器人的赛道想象力实在太大,而另一方面,也是看中了Brett Adcock成功的履历和用科技改变世界的决心。
在他的个人网站上,给自己的介绍是:专注成立公司20年
参考资料:
https://twitter.com/figure_robot/status/1767913661253984474
https://twitter.com/coreylynch/status/1767927194163331345
文章来自于微信公众号 “新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
