# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026 年,“世界模型” 正在成为具身智能行业的高频词。越来越多公司开始将自己的技术路线表述为机器人世界模型,试图用可学习的环境模型提升机器人训练效率。
灵初智能(PsiBot)也常被放入这一叙事中。但在灵初联合创始人陈源培看来,世界模型并不是灵初的核心方向,而是服务于数据迁移的工具。“我觉得做世界模型不算转型。世界模型只是个工具。我们从 Day one 开始,就是在做人类数据。”
灵初真正关注的问题是:真实人类操作数据,能否规模化转化为机器人训练数据?
在灵初成立前,陈源培已经开始探索用人类手部运动数据训练灵巧操作。这项工作后来发表于 CoRL 2024,也成为灵初押注 human data 路线的重要技术来源。如今,灵初在更大规模的数据实践中给出了一个更明确的判断:在 10 万小时量级上,人类数据已经可以大幅替代真机采集数据。
这一路线里,VLA、世界模型、强化学习、外骨骼手套都不是单独的终点。它们共同指向同一件事:构建一套从人类数据到机器人 policy 的转化管线。
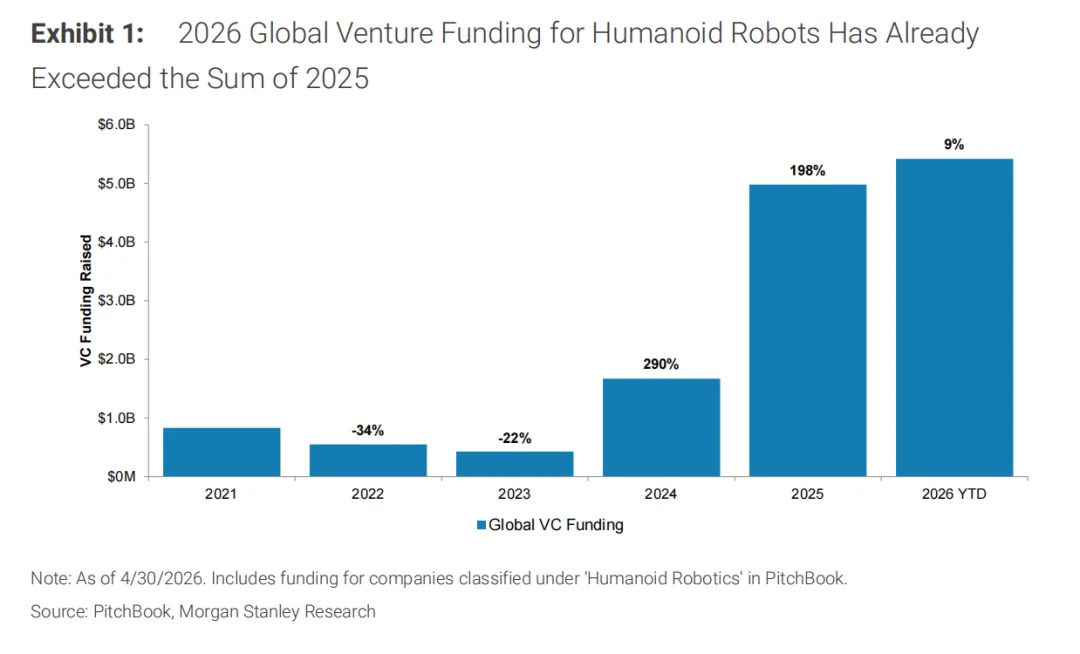
Morgan Stanley Research 统计显示,截至 2026 年 4 月底,2026 年全球人形机器人 VC 融资额已超过 2025 年全年。资本加速进入后,具身智能行业的数据、模型与落地能力正在被重新定价。
具身智能的数据问题,本质上是规模、质量和迁移效率之间的权衡。
过去几年,行业主流路线之一是 teleoperation。通过同构或近似同构的遥操作设备,让人直接控制机器人或影子臂采集数据。这类数据与机器人本体更接近,迁移难度低,训练链路相对直接。
但 teleoperation 的问题也很明显:采集成本高、设备重、场地依赖强、操作员需要训练,很难获得足够大的数据规模。对于试图训练通用机器人能力的公司来说,素材场式的数据生产方式很快会遇到上限。
另一类路线是 ego data,即用摄像头采集人类第一视角操作数据。它的成本更低,也更接近真实人类行为,但新的问题随之出现:人和机器人之间存在天然 gap。人的关节结构、骨骼自由度、动作习惯、视觉视角都与机器人不同。直接把这类数据用于机器人训练,往往会遇到迁移效率低、噪声大、动作不规范等问题。
灵初的判断是:迁移问题可以通过模型和算法管线解决,但数据规模问题必须在采集方式上解决。
“我们当时设计这套手套,一个很核心的原因就是能尽量不影响人的日常工作。比如让一个收银员戴上我们的手套工作,他基本上不会有什么影响。但你让他拿着两个夹爪工作,扫码都扫不了。”
这意味着,灵初想进入的不是专门搭建的机器人素材场,而是真实劳动场景:物流、仓储、收银、工厂等持续产生人类操作行为的场景。
这一路线与 UMI 等 robot-centric 方案形成对比。Robot-centric 方案通过形态更接近机器人夹爪的设备采集数据,迁移效率更高,但操作者动作会受到限制,很难进入真实劳动场景。灵初选择 human-centric,接受更高的迁移难度,换取更大的数据规模上限。
目前,灵初并行采集两类人类数据。
第一类是外骨骼手套数据。它通过机械连接捕捉手部和手臂动作,不依赖 IMU,精度更高,也可以记录更完整的双手双臂自由度。
第二类是纯视觉数据, 也就是英伟达和模型厂商押注的 EGO 路线:通过头部和腕部摄像头记录人类操作过程,不使用手套,成本更低,规模化能力更强,但动作精度相对弱一些。
在灵初的设计里,手套的自由度尽可能做高,并不只是为了适配自家的灵巧手,而是为了提升数据的跨本体迁移能力。换句话说,灵初想采集的不是绑定某一个机器人硬件的数据,而是未来可以迁移到不同机器人本体上的人类操作数据。
人类数据路线的核心难点,不是采集,而是迁移。
人类动作天然带有噪声和不规范性,人的动力学也不同于机器人。灵初的解决方式是:用强化学习,在世界模型中完成迁移。
灵初的系统主要由两个模块构成:W0 和 R2。
R2 是 policy,最终部署到机器人上,负责实际执行操作。W0 是 world model,更准确地说,是一个 action-conditioned world model:给定当前状态和动作,预测下一帧状态。
在训练阶段,W0 扮演可学习的仿真器。R2 不直接在真实机器人上大量试错,而是在 W0 构建的环境里通过强化学习在线迭代。W0 提供环境反馈,R2 在其中不断探索,把人手动力学迁移到机器人动力学上,并生成新的训练数据,再反哺 R2,形成闭环。
部署阶段,W0 退场,机器人上只运行 R2。
“如果模型训好了,自然就不需要 W0 了。W0 是个仿真器,它是个提升的过程,不是部署的一部分。”
这也是陈源培不愿意把灵初简单定义为 “世界模型公司” 的原因。在他的理解里,世界模型不是单独的方向,而是数据转化管线中的一个中间模块。它的作用不是替代真实世界,而是帮助人类数据完成到机器人 policy 的迁移。
“算法本身没那么重要,哪个好用就用哪个。我们更核心的还是人类数据,以及把这套数据转移成高质量机器人数据的管线。”
在这一体系中,数据质量也不完全依赖人工审核。灵初将判断权交给模型本身:一条数据能不能在世界模型里成功转换,能不能让 policy 跑通,就是筛选标准。能跑通的数据留下,跑不通的数据丢掉。随着模型能力提升,数据筛选边界也会动态变化。
陈源培认为,灵初在人类数据路线上的一个关键阶段性结果,是 10 万小时量级的内部验证。
“我们基本没有真机的素材场,真机数据非常非常少,靠人类数据也能做出来跟那些采了几万小时 teleoperation 数据的公司差不多的效果。”
这指向一个更核心的问题:机器人基础模型是否必须依赖大规模真机 teleoperation 数据?
陈源培的判断是,真机数据仍然重要,但它不一定是唯一燃料。如果人类数据采集足够规模化,迁移管线足够有效,那么大量真机数据可以被人类数据部分替代。真机数据更像是校准、验证和少量 fine-tuning 的补充,而不是全部数据来源。
这并不意味着人类数据天然等同于机器人数据。相反,人类数据要真正可用,必须经过采集系统、世界模型、强化学习、数据筛选和 policy 训练的完整管线。
灵初试图建立的,是这套系统能力。
截至 2026 年 5 月 13 日,灵初智能 SynData 数据集在 Hugging Face 上下载量已达约 1.46 万次。
Hugging Face链接:https://huggingface.co/datasets/PsiBotAI/SynData
这是基于 R2 和 W0 体系的新一代大规模真实世界多模态数据集,覆盖视觉、语言、动作等维度。依托自研外骨骼手套系统,SynData 能够捕捉双手双臂完整自由度的高精度操作数据,同时结合裸手数据与自然人类交互行为,面向动作建模、操作学习、道具学习及多模态智能研究开放使用。
对灵初而言,SynData 是其技术路线的一次阶段性外化:以真实人类操作数据为底座,通过世界模型和强化学习完成迁移,再训练出可部署到机器人上的 policy。
但从商业化阶段看,陈源培并不认为行业已经进入 “通用基模” 阶段。
他把灵初当前的位置分为几层。
第一层是产能期。现阶段,灵初的收入主体仍然来自硬件,包括外骨骼手套、采集系统以及素材场建设。数据收入预计要到明年才会逐渐成为主体。
第二层是调 policy 期。当前机器人进入具体客户场景,仍然需要针对任务、环境和节拍要求调整 policy。“真正不需要调的通用基模,还要大概三五年左右。”
第三层才是基模期。这是目标,但不是当下。
这也解释了灵初为什么选择做 “小全栈”。陈源培对 “小全栈” 的定义是:以模型为核心往下做,关键环节自己掌握,但做到核心零部件为止。比如触觉传感器、精密减速器这类零部件,灵初选择外采,不会自研。
原因并不是为了展示全栈能力,而是落地需要。“你要做落地,硬件的稳定性、节拍要求,跟硬件高度耦合,现在没办法,只能自己做。” 在现阶段,机器人落地不是单纯的软件问题。一个 policy 能否稳定运行,取决于机器人本体、执行器、传感器、控制系统、任务节拍和场景约束。模型和硬件仍然高度耦合,只做模型很难完成真实交付。
对于行业其他路线,陈源培的判断也比较明确。关于 Genesis 等近期受到关注的机器人 demo,他认为不需要神化,也不应否定。“如果我们拿那套硬件训一下,他们那些 demo 我们也都能做出来。”
关于仿真,他相对悲观。在他看来,仿真是重要工具,但如果期待仿真本身出现巨大突破,并单独解决真实物理世界中的接触、长尾和高精度操作问题,概率并不高。
那么,human data 路线会不会被证伪?
陈源培认为,如果这条路线最终被证伪,大概只有两种可能:第一,仿真出现巨大突破,可以低成本生成足够真实、足够多样、足够可迁移的数据;第二,某家公司拥有足够强的资金和工程能力,把真机数据飞轮真正跑起来。
相比之下,他认为第二种可能性更高。
在他看来,human data 路线真正要证明的,不是人类数据比真机数据更干净,而是在规模、成本、迁移效率和泛化能力之间,是否能形成更优的综合解。
这一路线的护城河也不只是数据量。
“算法其实没有秘密。但数据,包括整个数据梳理的管线、积累和处理的方法,会影响你很长一段时间。有些人踩了三年的数据,你想马上追上来,非常难。”
数据之外,还有组织能力。
“整个组织的文化、结构、价值观,也很重要。”
从论文到公司,陈源培认为灵初做的一直是同一件事:让人类数据能被机器人用起来。VLA、世界模型、强化学习都是工具,真正的方向是通用机器人能力。
文章来自于"机器之心",作者 "机器之心"。



