# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

jina-embeddings-v5-omni正式发布,我们把 v5-text 向量模型的能力延伸到图像、音频和视频。文本侧不变,v5-omni 产出的文本向量与 v5-text逐字节一致,无需重建任何已有索引。
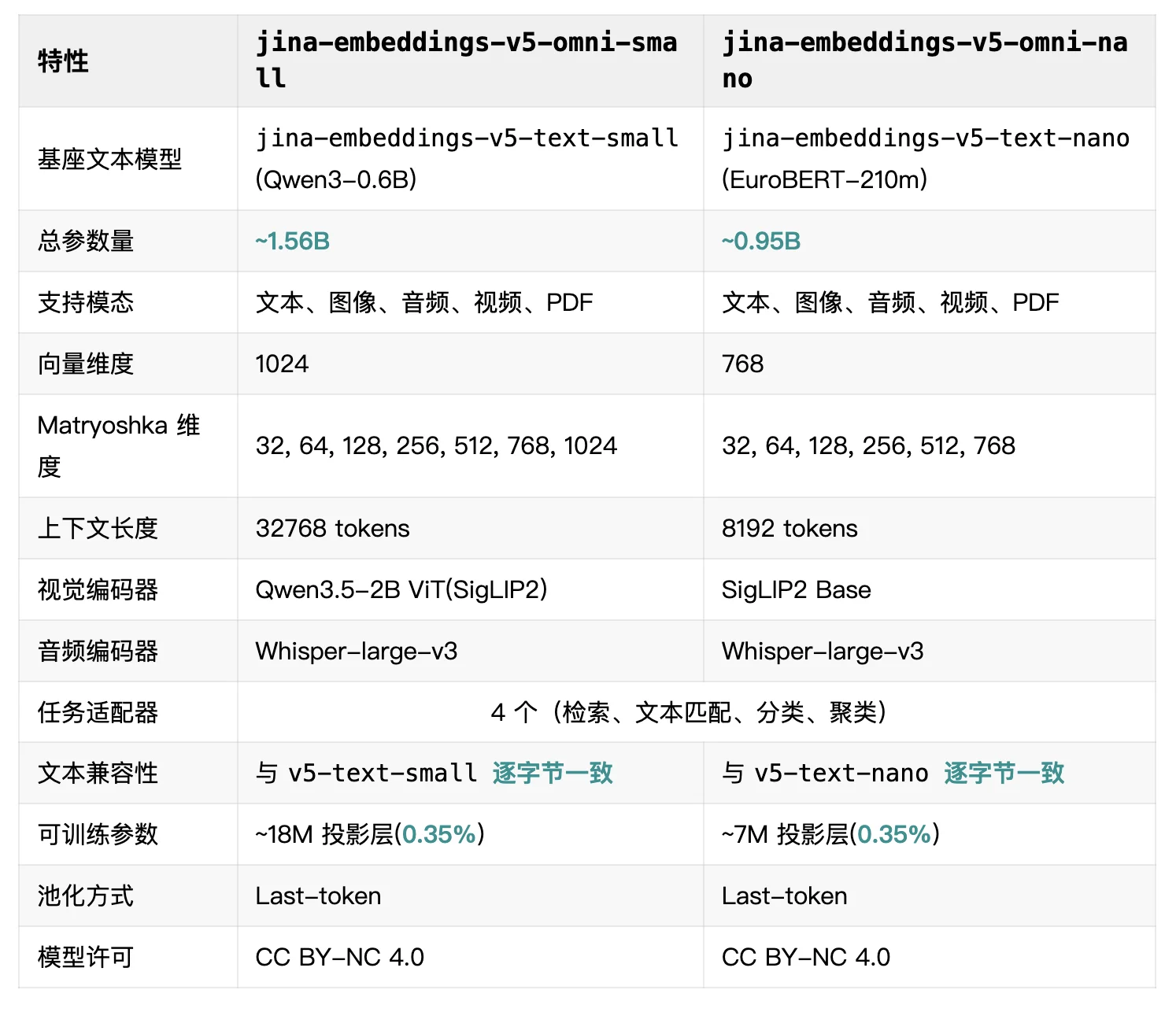
jina-embeddings-v5-omni-small 在四模态上平均得分 53.93,以 1/5.7 的参数量几乎追平 LCO-7B(54.43)。jina-embeddings-v5-omni-nano 在 0.95B 参数下,依然能在文档检索上交出有竞争力的成绩。资源链接:
HF 🤗 https://huggingface.co/collections/jinaai/jina-embeddings-v5-omni
魔搭 🧙 https://modelscope.cn/organization/jinaai
技术报告 📖 https://arxiv.org/abs/2605.08384
API 💻
https://jina.ai/embeddings/
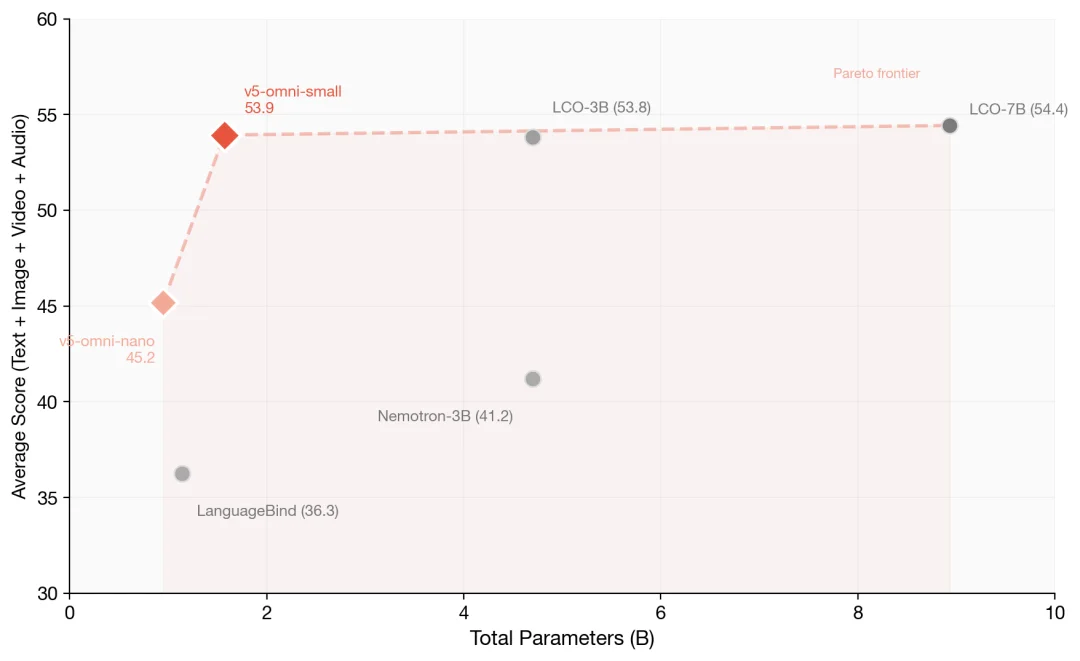
开源全模态向量模型(Omni embedding model)模型(同时覆盖文本、图像、音频、视频)的帕累托最优。
v5-omni-small(1.57B)的参数量不到 LCO-7B(8.93B)的 1/5,平均分却追平了它;v5-omni-nano(0.95B) 体量更小,但较 LanguageBind(1.14B)高出 8.9 分。横向对比基线包括 LanguageBind、Omni-Embed-Nemotron-3B、LCO-Embedding-Omni-3B 和 LCO-Embedding-Omni-7B。
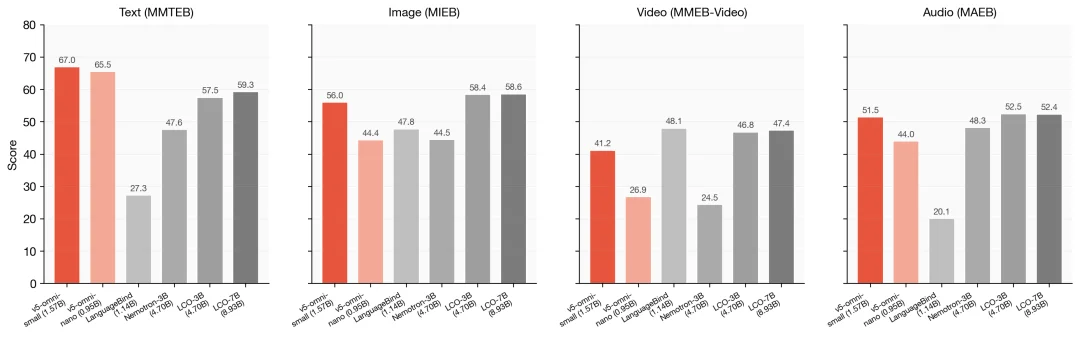
不同模态的表现
按模态拆解,我们分别在 MMTEB(文本)、MIEB(图像)、MMEB-Video(视频)、MAEB(音频)上评测。
v5-omni-small 在文本上拿到 67.0,领跑所有 Omni 模型:这一分数从 v5-text-small 原样继承,没有损失。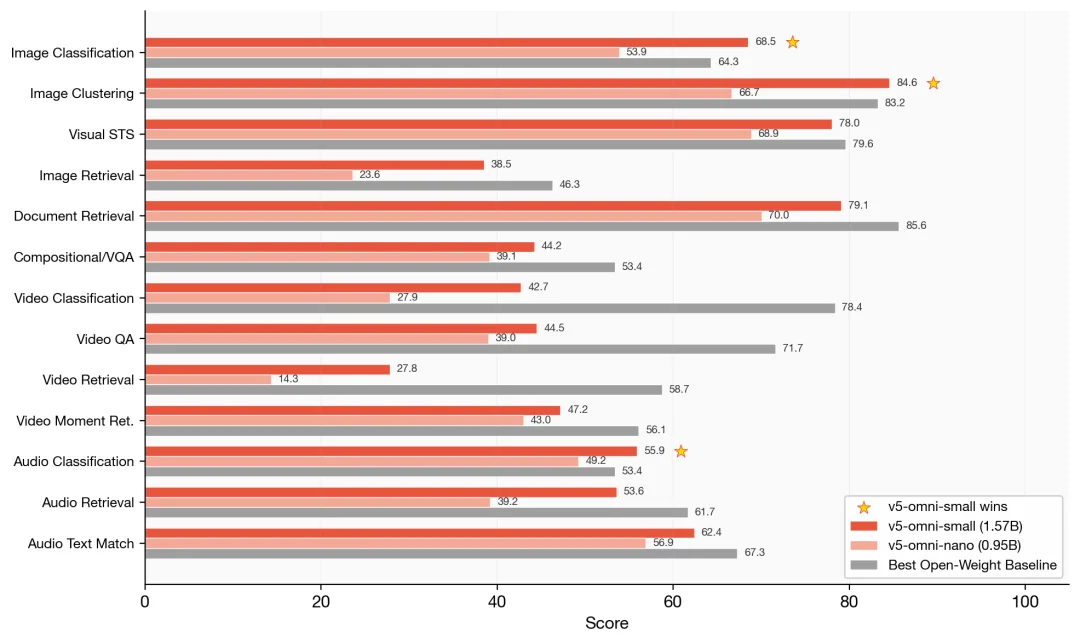
不同任务的表现
再把四个模态细拆成 13 类任务,图中星星标记的是 v5-omni-small 胜过最强开源基线(对方参数量普遍是它的 3-9 倍)的任务。
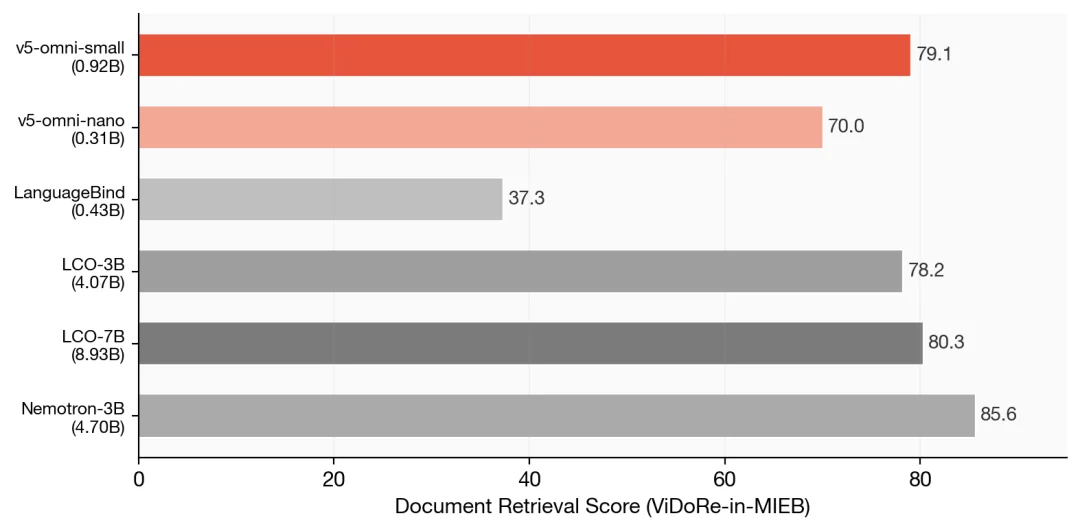
文档检索
单独看文档检索(ViDoRe-in-MIEB)。v5-omni-small 只激活 0.92B 文本 + 图像参数,就拿到 79.08,反超 LCO-3B(78.24,激活参数 4.07B)。
v5-omni-nano 更极致:0.31B 激活参数取得 70.05,把 LanguageBind(37.33)近乎翻倍。Nemotron-3B 以 85.64 暂居榜首,但参数量是 v5-omni-small 的 5.1 倍。
v5-omni 的做法是:作为文本侧底座的 v5-text、新增的视觉与音频编码器整体冻结,中间只插一层小型可训练投影层(projector),负责把不同模态的表示对齐到 v5-text 的语义空间。三个塔分别长这样:
fc_audio 把 1280 维输出投到 v5-text 的输入维度。任务侧,v5-omni 直接继承 v5-text 的四个任务专用 LoRA 适配器(检索、文本匹配、分类、聚类),每个任务变体单独训练自己的投影层权重。
这种"冻结 + 投影"的架构带来一个直接好处:完全模块化。只用文本,就只加载文本权重(内存占用与 v5-text 一模一样);要做图文,就再挂图像塔;音频、视频按需挂载,只有跑全模态时,所有塔才一齐就位。
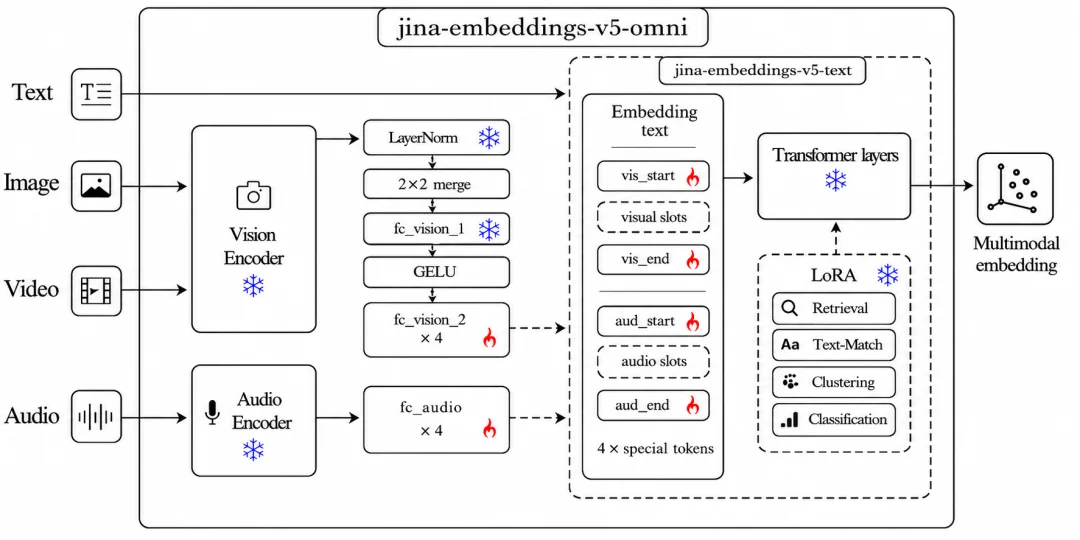
v5-omni 架构图
真正参与训练的只有中间那条小小的投影层,占总权重的 0.35%。视觉、音频、文本三个塔全部冻结。任务专用 LoRA 适配器分别处理检索、分类、聚类和文本匹配。
如果你已经在 Elasticsearch 中用 jina-embeddings-v5-text,现有的文本索引开箱兼容 v5-omni。Omni 模型对文本输入产出的向量与 v5-text 逐字节一致:同样的输入,同样的向量,无需重新 embed,无需重建索引。要把图像、音频、视频也搜起来,只需新建一个 v5-omni 索引,把多模态内容写进去就行。
用 v5-omni 作为推理端点创建一个 semantic_text 索引,EIS 会在索引和检索时自动选择对应的 LoRA 适配器:
PUT multimodal-semantic-index{"mappings": {"properties": {"content": {"type": "semantic_text","inference_id": ".jina-embeddings-v5-omni-small" } } }}
把文本、图像(base64 data URI)、音频、视频写入同一个字段、同一个索引:
// 写入文本
POST multimodal-semantic-index/_doc
{
"content": "'Kraft Dinner' is what Canadians call macaroni and cheese when prepared from a kit."
}
// 写入图像(base64)
POST multimodal-semantic-index/_doc
{
"content": "data:image/png;base64,iVBORw0KGgoAAAAN..."
}
用一条文本 query 跨所有模态搜索:
GET multimodal-semantic-index/_search{"query": {"semantic": {"field": "content","query": "Was bedeutet 'Kraft Dinner' für Kanadier?" } }}
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "jina-embeddings-v5-omni-small",
"task": "retrieval.query",
"dimensions": 1024,
"input": ["What does this image show?"],
"images": ["data:image/png;base64,..."]
}'
请前往 jina.ai/embeddings 获取 API Key。
from sentence_transformers import SentenceTransformer
import torch
model = SentenceTransformer(
"jinaai/jina-embeddings-v5-omni-small-retrieval",
model_kwargs={"dtype": torch.bfloat16},
)
# 文本向量(与 v5-text 完全一致)
text_emb = model.encode("What is knowledge distillation?",prompt_name="query")
# 图像向量
from PIL import Image
img = Image.open("photo.jpg")
img_emb = model.encode(img)
# 跨模态相似度
similarity = model.similarity(text_emb, img_emb)
我们把这套架构叫做 冻结编码器的模型组合(frozen-encoder model composition),拿一个足够强的文本向量模型做基座,把预训练好的视觉与音频编码器挂上去,中间只留一层小型可训练投影层,除此之外一律冻结。
整个联合模型只有 0.35% 的权重在训练,由此换来三件好处:1. 文本表现分毫未动:同样的输入产出同样的向量,字节级一致;2. 训练快、省显存:只训投影层,比全量训练快 1.8-3.9 倍,显存降低 42%-64%; 3. 模块化:各个塔可以独立加载。
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
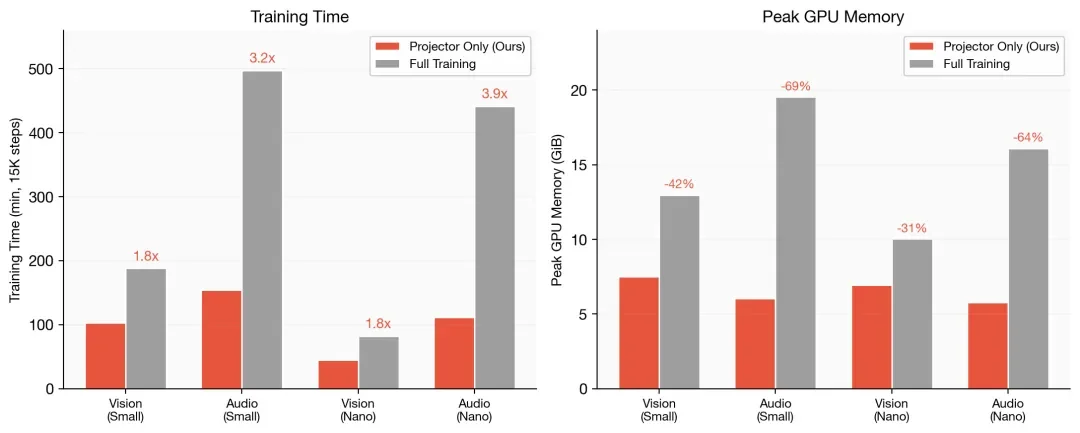
训练效率
上图是 4x H100、batch size 256、15K steps 下,投影层训练 vs 全量训练的耗时对比。音频侧的提速最明显:small 加速 3.2 倍 (154 min vs 497 min),nano 加速 3.9 倍(112 min vs 441 min)。显存能省下 42%-64%,因为冻结的编码器不需要保存梯度和优化器状态。
v5-omni 完整继承了 v5-text 的 Matryoshka 维度支持。图像与音频向量在维度截断下基本无损,视频向量在小维度下衰减更明显。
把四个模态汇总到一张雷达图上,v5-omni 各项 vs 最强基线。v5-omni-small(1.57B)在文本、图像、音频三项上的曲线 都贴住或反超基线;视频是雷达图上唯一明显凹下去的一块,也是我们下一版本要补的功课。
这是 Jina 在全模态向量模型方向上的首次尝试,我们希望换个角度思考这个问题:多模态向量模型,真的必须端到端整体训练吗?
v5-omni 给出的回答是:不一定。
v5-omni 冻结文本底座、只训练 0.35% 的权重,就足以在文本、图像、音频三项追上参数量 5-7 倍于自己的模型。我们得到的经验是:组合(composition)胜过重训(retraining)。真正难的事情是先把一个足够强的文本编码器训出来,这件事一旦做好,通过轻量投影层把视觉和音频挂上去,代价几乎为零。
但这一版最值得说的还不是 benchmark,而是这种冻结底座的设计带给生产级用户的一个直接好处:现有的 v5-text 索引一行都不用动。
如果你已经在用 v5-text,把推理端点切到 v5-omni 就行。同样的 query,同样的向量,逐字节一致;不需要重新向量化任何一条数据,就能直接获得图像、音频、视频检索能力。这是我们对多模态检索升级这件事的看法:应该是一次原地升级,而不是一次迁移工程。
jina-embeddings-v5-omni-small 是当前 20 亿参数以下最强的开源 Omni 向量模型。jina-embeddings-v5-omni-nano 在 10 亿参数量级上仍保持有竞争力的全模态检索能力
两个模型现已上线 Hugging Face 与 Jina Search Foundation API,也可以在 Elasticsearch 的原生推理端点直接调用。
我们把这套架构叫做冻结编码器的模型组合(frozen-encoder model composition),拿一个足够强的文本向量模型做基座,把预训练好的视觉与音频编码器挂上去,中间只留一层小型可训练投影层,除此之外一律冻结。
整个联合模型只有 0.35% 的权重在训练,由此换来三件好处:1. 文本表现分毫未动:同样的输入产出同样的向量,字节级一致;2. 训练快、省显存:只训投影层,比全量训练快 1.8-3.9 倍,显存降低 42%-64%;3. 模块化:各个塔可以独立加载。
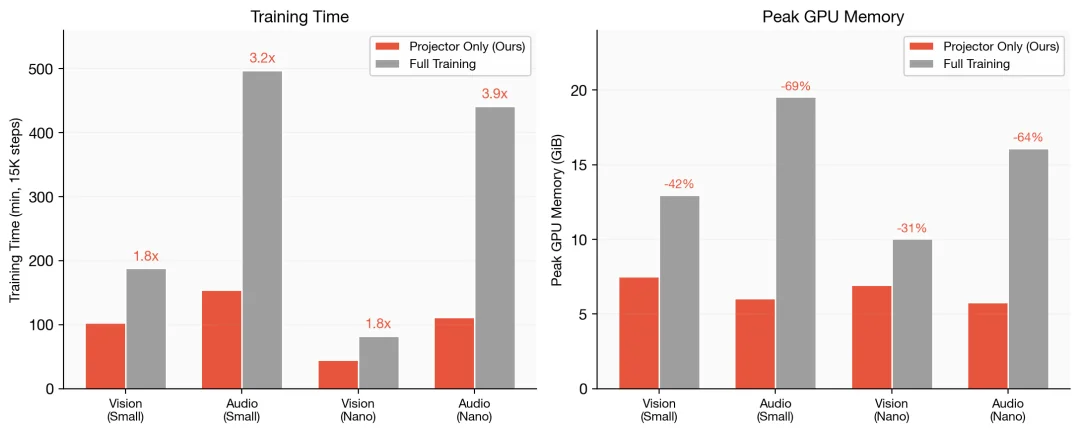
训练效率
上图是 4x H100、batch size 256、15K steps 下,投影层训练 vs 全量训练的耗时对比。音频侧的提速最明显:small 加速 3.2 倍 (154 min vs 497 min),nano 加速 3.9 倍(112 min vs 441 min)。显存能省下 42%-64%,因为冻结的编码器不需要保存梯度和优化器状态。
v5-omni 完整继承了 v5-text 的 Matryoshka 维度支持。图像与音频向量在维度截断下基本无损,视频向量在小维度下衰减更明显。
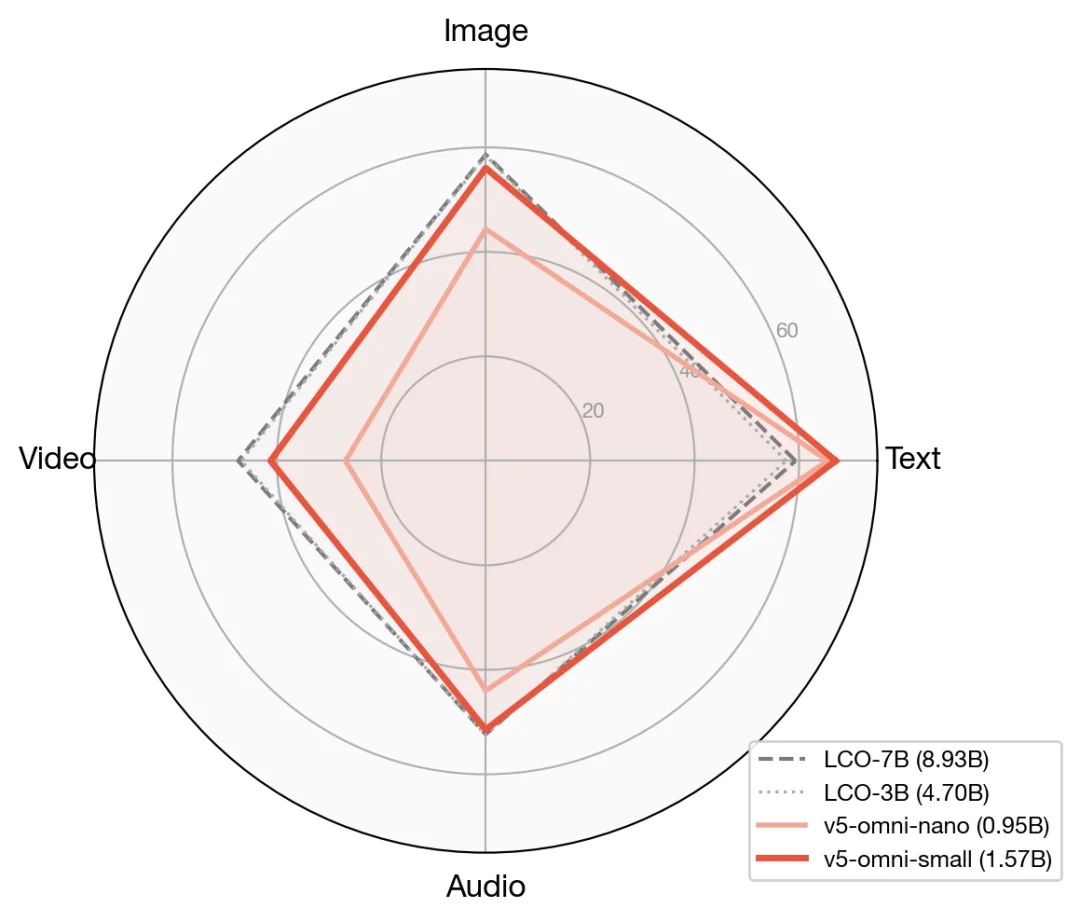
把四个模态汇总到一张雷达图上,v5-omni 各项 vs 最强基线。v5-omni-small(1.57B)在文本、图像、音频三项上的曲线 都贴住或反超基线;视频是雷达图上唯一明显凹下去的一块,也是我们下一版本要补的功课。
这是 Jina 在全模态向量模型方向上的首次尝试,我们希望换个角度思考这个问题:多模态向量模型,真的必须端到端整体训练吗?
v5-omni 给出的回答是:不一定。
v5-omni 冻结文本底座、只训练 0.35% 的权重,就足以在文本、图像、音频三项追上参数量 5-7 倍于自己的模型。我们得到的经验是:组合(composition)胜过重训(retraining)。真正难的事情是先把一个足够强的文本编码器训出来,这件事一旦做好,通过轻量投影层把视觉和音频挂上去,代价几乎为零。
但这一版最值得说的还不是 benchmark,而是这种冻结底座的设计带给生产级用户的一个直接好处:现有的 v5-text 索引一行都不用动。
如果你已经在用 v5-text,把推理端点切到 v5-omni 就行。同样的 query,同样的向量,逐字节一致;不需要重新向量化任何一条数据,就能直接获得图像、音频、视频检索能力。这是我们对多模态检索升级这件事的看法:应该是一次原地升级,而不是一次迁移工程。
jina-embeddings-v5-omni-small 是当前 20 亿参数以下最强的开源 Omni 向量模型。jina-embeddings-v5-omni-nano 在 10 亿参数量级上仍保持有竞争力的全模态检索能力
两个模型现已上线 Hugging Face 与 Jina Search Foundation API,也可以在 Elasticsearch 的原生推理端点直接调用。
文章来自于微信公众号 “Jina AI”,作者 “Jina AI”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
