# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你有没有遇到过这种情况:跟AI聊了半小时,它突然忘了你最开始说过什么;或者让它帮你做一个复杂任务,做到一半它开始胡言乱语,仿佛失忆一般。
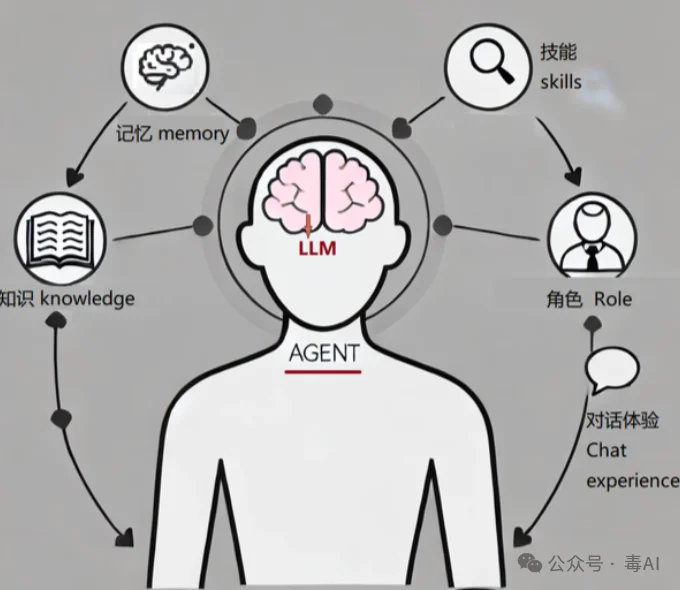
这其实就是AI Agent最大的软肋——记性差。
就在今天,腾讯云正式开源了 TencentDB Agent Memory,一套面向AI Agent的分层记忆引擎,MIT协议开源,开箱即用。

翻译成人话就是:腾讯给AI Agent装了个“外置大脑”,让它们终于可以记住自己做过什么、说过什么,而且所有人都可以免费拿去用。
Agent是一个能调用工具、自主完成复杂任务的AI程序。它不像普通聊天机器人一问一答就完事,而是可能连续工作几分钟甚至几小时,调用几十次搜索、读写工具,产出大量中间结果。
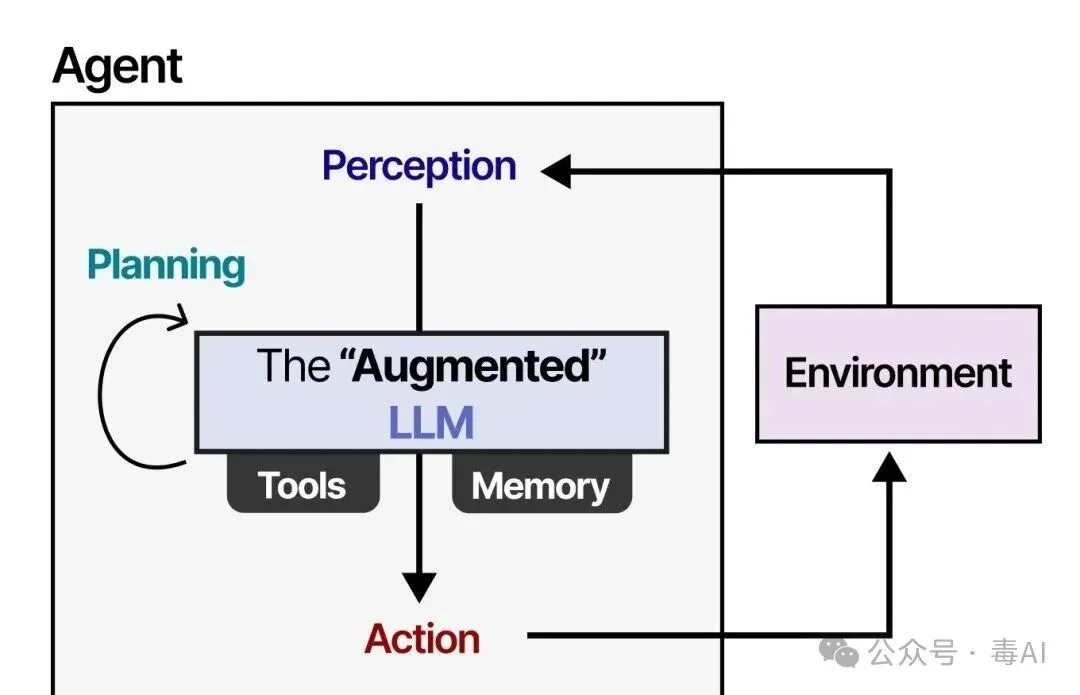
但这里就出现了一个致命的矛盾。
大语言模型处理信息依赖一个叫“上下文窗口”的东西,所有对话历史、工具返回结果都要塞进这个窗口。窗口满了,要么系统按规则截断历史,Agent丢失关键状态;要么窗口越塞越满,成本飙升,模型注意力分散——中间细节被忽略,回答质量断崖式下降。
更可怕的是,有研究表明,Agent甚至会引用之前自己产出的错误信息,以更高的置信度复用它,把一次性错误固化成“永久谎言”。
简单说就是三个扎心问题:
记忆不是Agent的“加分项”,而是决定它能走多远的基本功。
腾讯的方案怎么解决?核心逻辑很朴素:不要把什么都怼到模型眼前,该归档的归档,该分层的分层。
TencentDB Agent Memory 引入了 四层渐进式记忆架构:
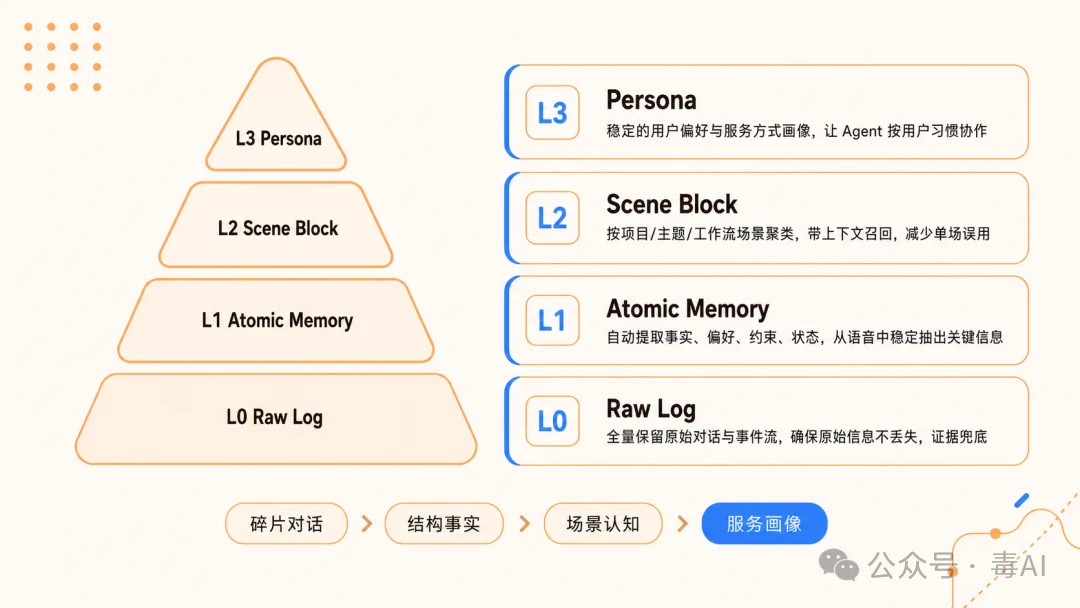
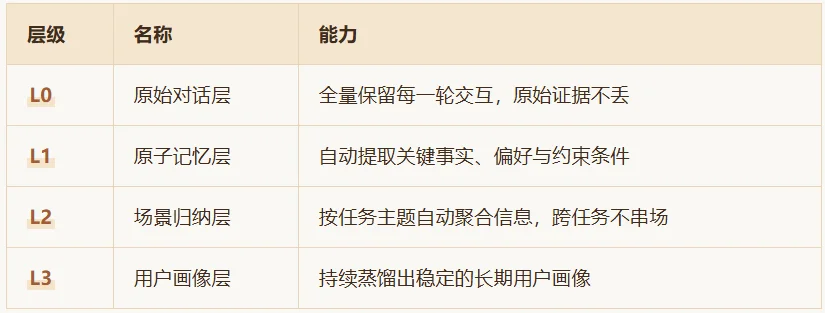
打个比方。普通Agent的记忆就像把所有东西堆在桌上,翻一页忘一页。而四层架构像是把东西分门别类放进抽屉柜——最底层抽屉存原始记录,往上抽出重点,再往上是按场景分好类,最顶层是你的一张“人物小传”。Agent日常只需要拉开上两层抽屉就够了,既轻量又精准。
这套分层记忆已经在实际评测中得到验证:
分层记忆解决的是长期记忆的问题。但在一次超长的单次任务中,Agent调用几十次工具后返回的大量结果同样会填爆上下文窗口——这才是真正烧钱的部分。

Agent Memory给出的解药是两项核心技术的组合:
什么是上下文卸载?
每次工具调用结束后,完整结果会被写入外部文件(比如refs/*.md),上下文里只保留一行摘要和索引路径。需要的时候再顺着索引按图索骥找回去。Agent日常只带着“目录”往前走,而不是把整本书背在身上。
Mermaid任务画布又是什么?
Mermaid是GitHub和技术文档中广泛使用的图描述语言,主流大模型天然具备读写能力。腾讯云数据库团队用它把Agent的任务执行过程组织成一张可导航的结构化地图——哪些步骤是并行的,哪些有前置依赖,当前处于哪个阶段,一目了然。
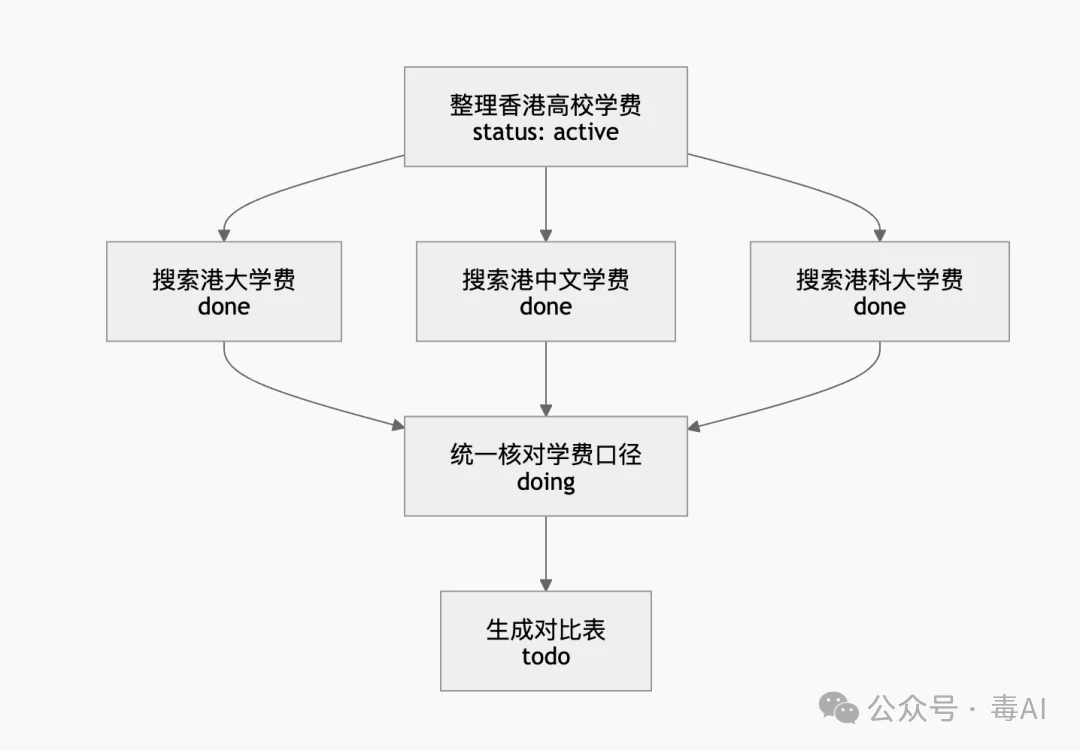
“流水账适合记录,地图适合导航”——长任务里最危险的事不是信息丢了,而是Agent不知道自己走到哪了。
更深一层看,信息的存储链路是这样的:
底层完整工具返回原文(外部文件)→ 中间调用级摘要(JSONL记录)→ 上层任务画布节点 → 最顶层任务级索引(上下文)
Agent日常只需接触上层轻量信息驱动任务推进;当摘要不够支撑决策时,通过节点ID逐层回溯,直到拿到完整原文——每一条信息都可以沿索引链路100%找回。
省Token不是靠“有损压缩”,而是靠“有索引的结构化存储”。
说到底,数据会说话。
在多任务连续Session实验中,Agent Memory最高将Token消耗降低了61.38%,同时任务成功率相对提升51.52%。这不是简单的“省了钱”,而是省钱的同时把活干得更好了——上下文中的噪声减少后,模型的注意力更集中,任务成功率自然提升。
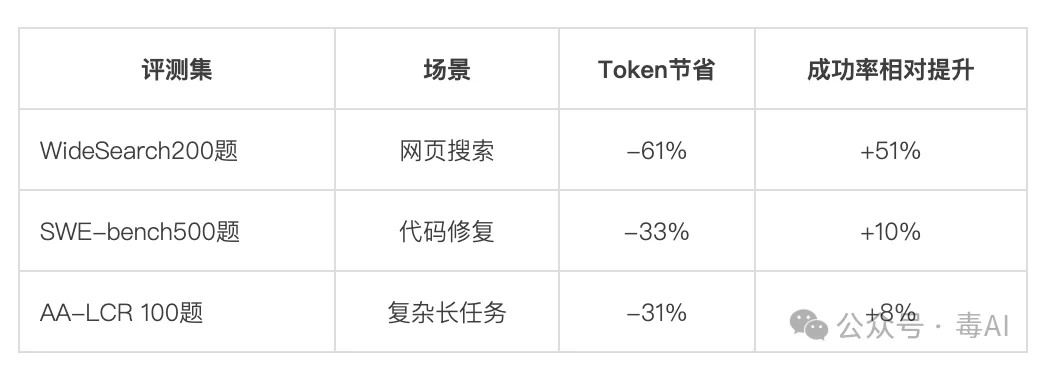
消融实验也验证了画布的独立价值:
在WideSearch评测中:
SWE-bench评测中:
这条曲线在业界相当罕见——多数压缩方案能把Token砍下来,但任务跑偏、遗忘、重复分析的问题随之而来。而Agent Memory是“两条曲线同时往好的方向走”,省钱的同时也把任务完成得更好。
这个故事其实远不止一个开源项目那么简单。它折射出整个技术基础设施正在经历的底层变革。
过去三十年,数据库为“人”设计——DBA写SQL,应用通过ORM读写。数据库扮演的是“仓库管理员”的角色,把数据存好、查出来就行。
但在Agent时代,数据库的主要调用者正在从人变成AI Agent。Agent从“对话助手”变成“数字员工”,底层数据基础设施也跟着变——从存储中心变成知识与记忆中心。
更深远的趋势是,2026年语境记忆正从一项前沿技术变成Agent落地的“入场券”。行业分析认为,语境记忆将不再是小众技术,而会成为很多可运营的Agent系统的基本标配。数据库的价值定位正在被重新书写——它不再只是一个“数据仓库”,而是Agent时代的新型“记忆中枢”。
最后来说开源这件事。腾讯选择MIT协议开源TencentDB Agent Memory,意味着任何人都可以免费使用、修改、商用这套记忆引擎。

目前它已适配OpenClaw和Hermes等主流Agent框架,本地部署一条命令就能完成安装,零外部依赖,默认使用本地SQLite,部署门槛极低。
这个动作背后的信号很清晰:Agent记忆正在从一个“高端配置”变成“基础标配”。
过去只有大厂才做得到的记忆管理能力,现在任何一个个人开发者、任何一个创业团队都能免费获得。当记忆不再是瓶颈,AI Agent才能真正去干更复杂、更有价值的活。
也许用不了多久,一个记不住你上次说了什么的AI,就像今天一个不会自动保存的文档编辑器一样——没人能忍。
这不是科幻,这是正在发生的日常。
文章来自于"毒AI",作者 "毒AI"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
