# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大型语言模型(LLMs)的发展极大地推动了代码生成领域的发展,之前有工作将强化学习(RL)与编译器的反馈信号集成在一起,用于探索LLMs的输出空间,以提高代码生成质量。
但当下还存在两个问题:
1. 强化学习探索很难直接适配到「复杂的人类需求」,即要求LLMs生成「长序列代码」;
2. 由于单元测试可能无法覆盖复杂的代码,因此使用未执行的代码片段来优化LLMs是无效的。
为了解决这些挑战,复旦大学、华中科技大学、皇家理工学院的研究人员提出了一种用于代码生成的新型强化学习框架StepCoder,由两个主要组件组成:
1. CCCS通过将长序列代码生成任务分解为代码完成子任务课程来解决探索挑战;
2. FGO通过屏蔽未执行的代码段来优化模型,以提供细粒度优化。

论文链接:https://arxiv.org/pdf/2402.01391.pdf
项目链接:https://github.com/Ablustrund/APPS_Plus
研究人员还构建了用于强化学习训练的APPS+数据集,手动验证以确保单元测试的正确性。
实验结果表明,该方法提高了探索输出空间的能力,并在相应的基准测试中优于最先进的方法。
在代码生成过程中,普通的强化学习探索(exploration)很难处理「奖励稀疏且延迟的环境」和涉及「长序列的复杂需求」。
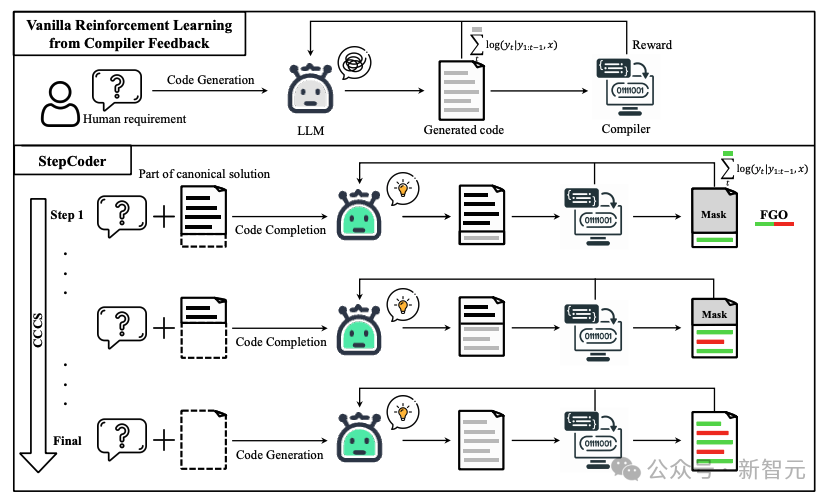
在CCCS(Curriculum of Code Completion Subtasks)阶段,研究人员将复杂的探索问题分解为一系列子任务。利用标准解(canonical solution)的一部分作为提示(prompt),LLM可以从简单序列开始探索。
奖励的计算只与可执行的代码片段相关,因此用整个代码(图中红色部分)来优化LLM是不精确的(图中灰色部分)。
在FGO(Fine-Grained Optimization)阶段,研究人员对单元测试中未执行的tokens(红色部分)进行遮罩,只使用已执行的tokens(绿色部分)计算损失函数,从而可以提供细粒度的优化。
预备知识
假定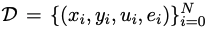 是用于代码生成的训练数据集,其中x、y、u分别表示人类需求(即任务描述)、标准解和单元测试样本。
是用于代码生成的训练数据集,其中x、y、u分别表示人类需求(即任务描述)、标准解和单元测试样本。
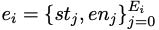 是通过自动分析标准解yi的抽象语法树得出的条件语句列表,其中st和en分别表示语句的起始位置和结束位置。
是通过自动分析标准解yi的抽象语法树得出的条件语句列表,其中st和en分别表示语句的起始位置和结束位置。
对于人类需求x,其标准解y可表示为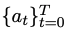 ;在代码生成阶段,给定人类需求x,最终状态是通过单元测试u的代码集合。
;在代码生成阶段,给定人类需求x,最终状态是通过单元测试u的代码集合。
方法细节
StepCoder集成了两个关键组件:CCCS和FGO,其中CCCS的目的是将代码生成任务分解为代码完成子任务的课程,可以减轻RL中的探索挑战;FGO专为代码生成任务而设计,通过只计算已执行代码片段的损失来提供细粒度优化。
CCCS
在代码生成过程中,要解决复杂的人类需求,通常需要策略模型采取较长的动作序列。同时,编译器的反馈是延迟和稀疏的,也就是说,策略模型只有在生成整个代码后才会收到奖励。在这种情况下,探索非常困难。
该方法的核心是将这样一长串探索问题分解为一系列简短、易于探索的子任务,研究人员将代码生成简化为代码补全子任务,其中子任务由训练数据集中的典型解决方案自动构建。
对于人类需求x,在CCCS的早期训练阶段,探索的起点s*是最终状态附近的状态。
具体来说,研究人员提供人类需求x和标准解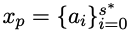 的前半部分,并训练策略模型来根据x'=(x, xp)完成代码。
的前半部分,并训练策略模型来根据x'=(x, xp)完成代码。
假定y^是xp和输出轨迹τ的组合序列,即yˆ=(xp,τ),奖励模型根据以y^为输入的代码片段τ的正确性提供奖励r。

研究人员使用近端策略优化(PPO)算法,通过利用奖励r和轨迹τ来优化策略模型πθ 。
在优化阶段,用于提供提示的规范解代码段xp将被屏蔽,这样它就不会对策略模型πθ更新的梯度产生影响。
CCCS通过最大化反对函数来优化策略模型πθ,其中π^ref是PPO中的参考模型,由SFT模型初始化。
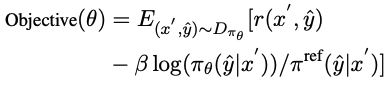
随着训练的进行,探索的起点s*会逐渐向标准解的起点移动,具体来说,为每个训练样本设置一个阈值ρ,每当πθ生成的代码段的累计正确率大于ρ时,就将starting point向beginning移动。
在训练的后期阶段,该方法的探索过程等同于原始强化学习的探索过程,即s*=0,策略模型仅以人类需求为输入生成代码。
在条件语句的起始位置对初识点s*进行采样,以完成剩余的未写代码段。
具体来说,条件语句越多,程序的独立路径就越多,逻辑复杂度也就越高,复杂性要求更频繁地采样以提高训练质量,而条件语句较少的程序则不需要那么频繁地采样。
这种采样方法可以均衡地抽取具有代表性的代码结构,同时兼顾训练数据集中复杂和简单的语义结构。
为了加速训练阶段,研究人员将第i个样本的课程数量设置为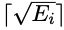 ,其中Ei是其条件语句的数量。第i个样本的训练课程跨度为
,其中Ei是其条件语句的数量。第i个样本的训练课程跨度为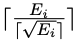 ,而不是1。
,而不是1。
CCCS的主要观点可归纳如下:
1. 从接近目标的状态(即最终状态)开始探索很容易;
2. 从距离目标较远的状态开始探索具有挑战性,但如果能利用已经学会如何达到目标的状态,探索就会变得容易。
FGO
代码生成中奖励与行动之间的关系不同于其他强化学习任务(如Atari),在代码生成中,可以排除一组与计算生成代码中的奖励无关的动作。
具体来说,对于单元测试,编译器的反馈只与执行的代码片段,然而,在普通RL优化目标中,轨迹上的所有动作都会参与到梯度计算中,而梯度计算是不精确的。
为了提高优化精度,研究人员屏蔽了单元测试中未执行的行动(即tokens),策略模型的损失。

APPS+数据集
强化学习需要大量高质量的训练数据,在调研过程中,研究人员发现在目前可用的开源数据集中,只有APPS符合这一要求。
但APPS中存在一些不正确的实例,例如缺少输入、输出或标准解,其中标准解可能无法编译或无法执行,或者执行输出存在差异。
为了完善APPS数据集,研究人员过滤掉了缺少输入、输出或标准解的实例,然后对输入和输出的格式进行了标准化,以方便单元测试的执行和比较;然后对每个实例进行了单元测试和人工分析,剔除了代码不完整或不相关、语法错误、API误用或缺少库依赖关系的实例。
对于输出中的差异,研究人员会手动审核问题描述,纠正预期输出或消除实例。
最后构建了得到APPS+数据集,包含了7456个实例,每个实例包括编程问题描述、标准解决方案、函数名称、单元测试(即输入和输出)和启动代码(即标准解决方案的开头部分)。

为了评估其他LLM和StepCoder在代码生成方面的性能,研究人员在APPS+数据集上进行了实验。
结果表明,基于RL的模型优于其他语言模型,包括基础模型和SFT模型。
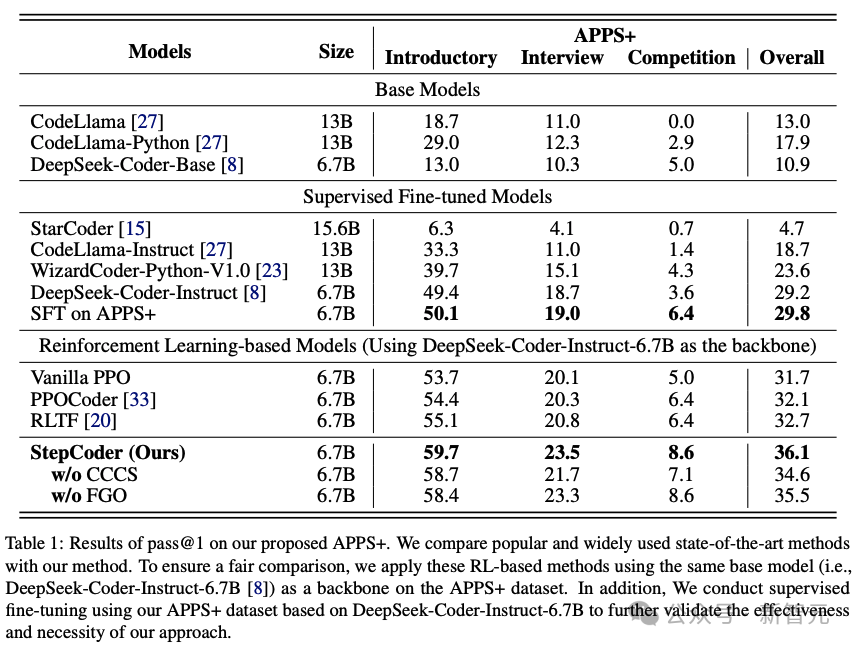
研究人员有理由推断,强化学习可以在编译器反馈的指导下,更有效地浏览模型的输出空间,从而进一步提高代码生成的质量。
此外,StepCoder超越了所有基线模型,包括其他基于RL的方法,获得了最高分。
具体来说,该方法在「入门」(Introductory)、「面试」(Interview)和「竞赛」(Competition)级别的测试题目中分别获得了59.7%、23.5%和 8.6%的高分。
与其他基于强化学习的方法相比,该方法通过将复杂的代码生成任务简化为代码完成子任务,在探索输出空间方面表现出色,并且FGO过程在精确优化策略模型方面发挥了关键作用。
还可以发现,在基于相同架构网络的APPS+数据集上,StepCoder的性能优于对微调进行有监督的LLM;与骨干网相比,后者几乎没有提高生成代码的通过率,这也直接表明,使用编译器反馈优化模型的方法比代码生成中的下一个token预测更能提高生成代码的质量。
参考资料:
https://arxiv.org/pdf/2402.01391.pdf
文章来自于微信公众号 “新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
