# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
时间序列预测在零售、金融、制造业、医疗保健和自然科学等各个领域无处不在:比如说在零售场景下中,「提高需求预测准确性」可以有显著降低库存成本并增加收入。
深度学习(DL)模型基本上垄断了「多变量时间序列预测」任务,在各个竞赛、现实应用中的表现都非常好。
与此同时,用于自然语言处理(NLP)任务的大型基础语言模型也取得了快速进展,大幅提升了翻译、检索增强生成、代码补全等任务的性能。
NLP模型的训练依赖于海量文本数据,其中数据来源多种多样,包括爬虫、开源代码等,训练后的模型能够识别语言中的模式,并具备零样本学习的能力:比如说把大模型用在检索任务时,模型可以回答有关当前事件的问题并对其进行总结。
尽管基于DL的预测器在很大程度上优于传统方法,并且在降低训练和推理成本方面取得了进展,但仍然面临着诸多难题:
大多数深度学习模型需要长时间的训练和验证周期,之后才能在新的时间序列上测试模型;相比之下,时间序列预测的基础模型可以在不需要额外训练的情况下,对没见过的时间序列数据提供「开箱即用预测」,使用户能够专注于改进零售需求规划等实际下游任务的预测。
最近,Google Research的研究人员提出了一个时序预测基础模型TimesFM,在1000亿个「真实世界时间点」上进行预训练;与最新的大型语言模型(LLMs)相比,TimesFM的规模要小得多,只有200 M参数。

论文链接:https://arxiv.org/pdf/2310.10688.pdf
实验结果表明,即使在这样小的规模下,TimesFM在不同领域和时间粒度的各种未见过的数据集上的「零样本性能」也接近于在这些数据集上明确训练过的、最先进的、有监督方法。
研究人员计划今年晚些时候在Google Cloud Vertex AI中为外部客户提供TimesFM模型。
LLMs通常以仅解码器(decoder-only)的方式进行训练,包括三个步骤:
1. 文本被分解为称为token的子词(subwords)
2. tokens被馈送到堆叠的causal Transformer层,并生成与每个输入token对应的输出,需要注意的是,该层无法处理没输入的token,即future tokens
3. 对应于第i个token的输出总结了来自先前token的所有信息,并预测第(i+1)个token
在推理期间,LLM每次生成一个token的输出。
例如,当输入提示「法国的首都是哪里?」(What is the capital of France?)时,模型可能会生成token为「The」,然后以该提示为条件生成下一个token「首都」(captial)等,直到模型生成完整的答案:「法国的首都是巴黎」(The capital of France is Paris)。
时间序列预测的基础模型应该适应可变的上下文(模型观察到的内容)和范围(查询模型预测的内容)长度,同时具有足够的能力来编码来自大型预训练数据集的所有模式(patterns)。
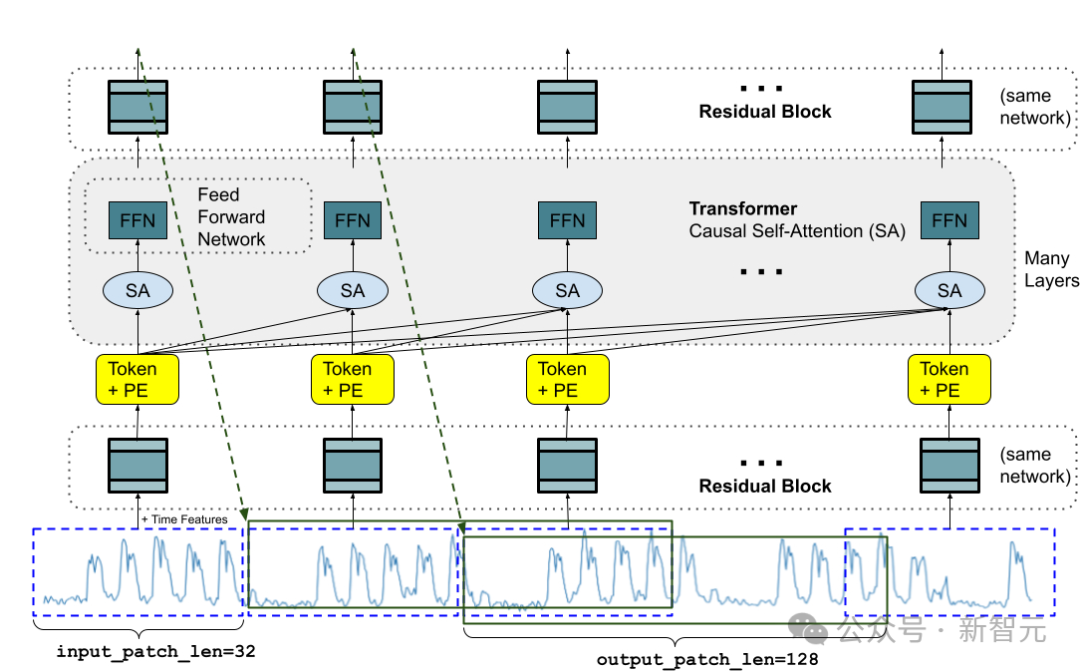
与LLMs类似,研究人员使用堆叠的Transformer层(自注意力和前馈层)作为TimesFM模型的主要构建块;在时间序列预测的背景下,把一个patch(一组连续的时间点)作为一个token,思路来源于最近的long-horizon forecasting工作:具体任务是预测在堆叠的Transformer层的末尾处,针对给定第i个输出来预测第(i+1)个时间点patch
但TimesFM与语言模型有几个关键的区别:
1. 模型需要一个具有残差连接的多层感知器块,将时间序列的patch转换为token,其可以与位置编码(PE)一起沿着输入到Transformer层。为此,我们使用类似于我们以前在长期预测中的工作的残差块。
2. 来自堆叠的Transformer的输出token可以用于预测比输入patch长度更长的后续时间点的长度,即,输出patch长度可以大于输入patch长度。
假设,长度为512个时间点的时间序列被用于训练具有「输入patch长度32」和「输出patch长度128」的TimesFM模型时:
在训练期间,模型同时被训练为使用前32个时间点来预测接下来的128个时间点,使用前64个时间点来预测时间点65至192,使用前96个时间点来预测时间点97至224等等。
假设输入数据为长度为256的时间序列,并且其任务是预测未来的接下来的256个时间点,模型首先生成时间点257至384的未来预测,然后以初始256长度输入加上生成的输出为条件来生成时间点385至512。
另一方面,如果在模型中,输出patch长度等于输入patch长度32,那么对于相同的任务,模型经历八次生成步骤而非2次,增加了错误累积的风险,因此在实验结果中可以看到,更长的输出patch长度会带来更好的长期预测性能。
就像LLMs可以通过更多token变得更好一样,TimesFM需要大量合法的时间序列数据来学习和改进;研究人员花了大量的时间来创建和评估训练数据集,发现两个比较好的方法:
合成数据有助于基础(Synthetic data helps with the basics)
可以使用统计模型或物理模拟生成有意义的合成时间序列数据,基本的时间模式可以引导模型学习时间序列预测的语法。
真实世界的数据增加了真实世界的感觉(Real-world data adds real-world flavor)
研究人员梳理了可用的公共时间序列数据集,并有选择地将1000亿个时间点的大型语料库放在一起。
在数据集中,有Google趋势和维基百科的页面浏览量,跟踪用户感兴趣的内容,并且很好地反映了许多其他真实世界时间序列的趋势和模式,有助于TimesFM理解更大的图景,可以针对「训练期间没见过的、特定领域上下文」提升泛化性能。
研究人员使用常用的时间序列基准,针对训练期间未见过的数据对TimesFM进行零样本评估,可以观察到TimesFM的性能优于大多数统计方法,如ARIMA,ETS,并且可以匹配或优于强大的DL模型,如DeepAR,PatchTST,这些模型已经在目标时间序列上进行了明确的训练。
研究人员使用Monash Forecasting Archive来评估TimesFM的开箱即用性能,该数据集包含来自各个领域的数万个时间序列,如交通、天气和需求预测,覆盖频率从几分钟到每年的数据。
根据现有文献,研究人员检查了适当缩放的平均绝对误差(MAE),以便在数据集上取平均值。
可以看到,zero-shot(ZS)TimesFM比大多数监督方法都要好,包括最近的深度学习模型。还对比了TimesFM和GPT-3.5使用llmtime(ZS)提出的特定提示技术进行预测,结果证明了TimesFM的性能优于llmtime(ZS)
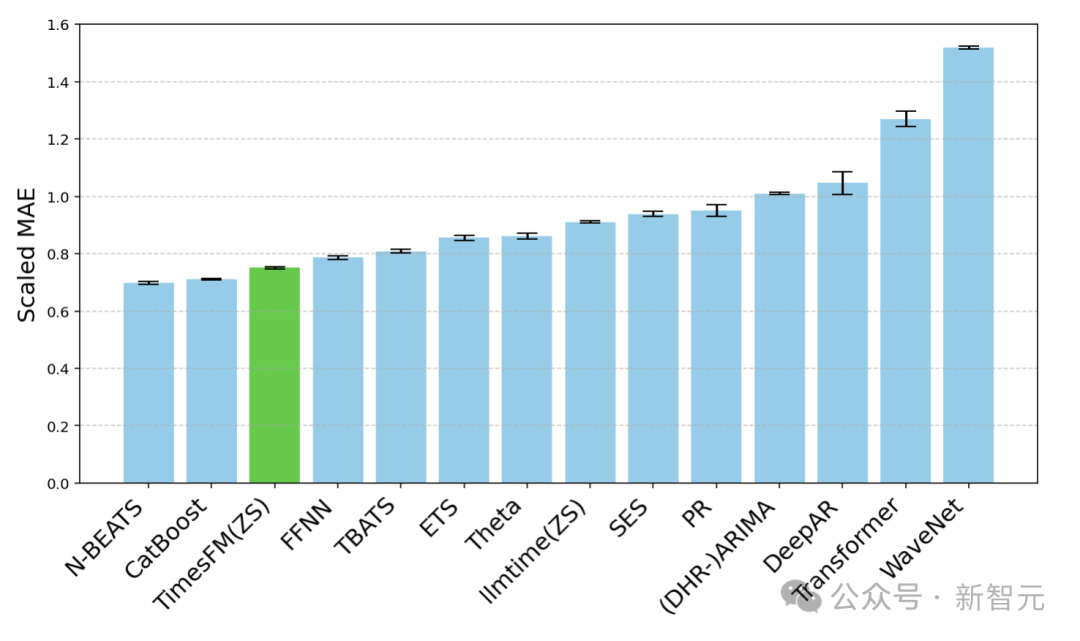
在Monash数据集上,TimesFM(ZS)与其他有监督和零样本方法的比例MAE(越低越好)
大多数Monash数据集都是短期或中期的,也就是说预测长度不会太长;研究人员还测试了TimesFM对常用基准长期预测对最先进的基线PatchTST(和其他长期预测基线)。
研究人员绘制了ETT数据集上的MAE,用于预测未来96和192个时间点的任务,在每个数据集的最后一个测试窗口上计算指标。
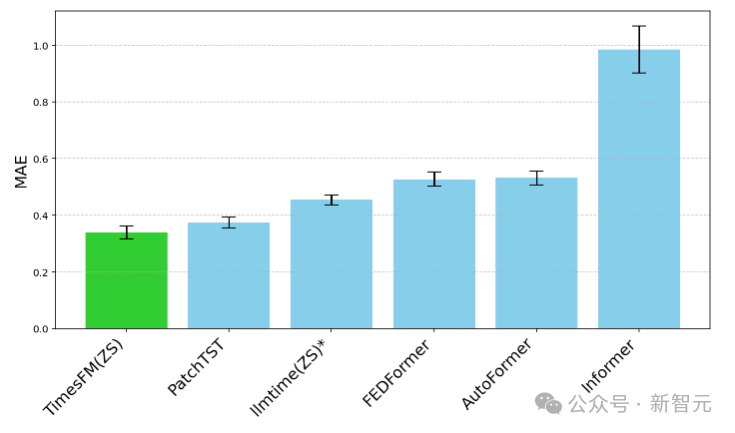
TimesFM(ZS)的最后一个窗口MAE(越低越好)相对于ETT数据集上的llmtime(ZS)和长期预测基线
可以看到,TimesFM不仅超过了llmtime(ZS)的性能,而且与在相应数据集上显式训练的有监督PatchTST模型的性能相匹配。
研究人员使用1000亿真实的世界时间点的大型预训练语料库训练了一个仅用于解码器的基础模型,其中大部分是来自Google趋势的搜索兴趣时间序列数据和维基百科的页面浏览量。
结果表明,即使是一个相对较小的200 M参数预训练模型,使用TimesFM架构,在各种公共基准测试(不同的领域和粒度)中都展现出相当好的零样本性能。
参考资料:
https://blog.research.google/2024/02/a-decoder-only-foundation-model-for.html
文章来自于微信公众号 “新智元”




【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
