# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人类研究员做实验,从来不是把几句步骤随手拼起来。
一份真正可复现的实验protocol,需要明确每一步做什么、对什么对象操作、用什么参数,以及步骤之间的先后依赖。
一旦顺序错了、剂量错了、对象错了,表面上看起来流畅的文本,也可能在实验台上直接失效。
然而,当前大模型虽然已经能回答大量生物医学问题,在真正生成实验方案时仍然容易出现问题:
步骤缺失、顺序混乱、操作冗余、参数幻觉,甚至把不能直接执行的建议包装成一段“看起来很专业”的说明。
更关键的是,传统文本指标如BLEU、ROUGE、BERTScore主要看词面相似度,难以判断一个protocol是否真的逻辑正确、语义忠实、可在实验中执行。
LLM-as-a-Judge虽然更接近人类偏好,但用于强化学习训练时代价过高,也不够稳定。
针对这一问题,上海人工智能实验室、复旦大学、上海交通大学团队提出了Thoth:一个面向生物实验protocol生成的科学推理模型。

相关论文《Unleashing Scientific Reasoning for Bio-Experimental Protocol Generation via Structured Component-Based Reward Mechanism》已在ICLR2026正式发表。
一句话概括:Thoth不是让模型“写得像protocol”,而是让模型按照实验逻辑,生成可解析、可评估、可执行的protocol。
在生命科学研究中,protocol并不是普通说明文,而是实验执行蓝图。
它需要同时满足三类要求:
粒度合适:步骤不能过粗导致关键信息丢失,也不能过细造成冗余;
顺序正确:前置处理、加入试剂、孵育、离心、检测等操作必须符合实验依赖;
语义准确:每个动作都要绑定正确的对象和参数。
举个简单例子:如果原protocol要求将5mL凝胶预混液与25µL 10% APS、2.5µL TEMED混合,那么缩放到1mL时,APS应为5µL,TEMED应为0.5µL。
在论文展示的案例中,Thoth能给出简洁且顺序正确的结构化步骤;而对比模型虽然语言流畅,却把TEMED剂量写成了5µL,出现了执行层面的事实错误。
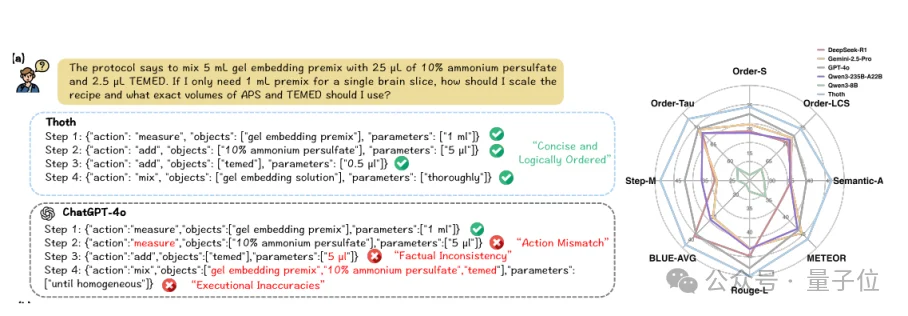
这类错误很难被普通文本相似度指标惩罚,因为模型可能“说得很像”,但实验上并不可靠。
因此,团队认为,要让AI真正辅助实验复现,需要把protocol生成从自由文本生成,推进到结构化科学推理。
为了解决数据基础不足的问题,团队首先构建了SciRecipe。
该数据集来源于Nature Protocols、Bio-protocol、Protocols.io等标准化实验流程平台。
团队从超过23K份原始protocol中进行清洗、去重、结构化处理和质量控制,最终保留约12K条高质量数据,覆盖神经科学、分子生物学、癌症生物学等27个生物学子领域。
SciRecipe不仅包含传统的protocol理解任务,还进一步覆盖真实实验工作流中的问题解决场景,包括:
也就是说,SciRecipe不是只让模型“读懂protocol”,而是让模型在理解、规划、纠错、缩放、安全等环节形成完整的“理解—应用”闭环。

Thoth的第一个关键设计,是Sketch-and-Fill推理范式。
这个范式把protocol生成拆成三个阶段:
首先是think,模型先分析任务目标、实验依赖和步骤必要性;
然后是key,模型把实验方案抽象成机器可读的原子步骤,每一步都包含action、objects、parameters三个核心字段;
最后是orc,模型再把这些结构化步骤改写成自然语言protocol,保证人类研究员能够直接阅读和执行。
可以把它理解为:先让模型写“实验骨架”,再把骨架填充成完整操作说明。
这一设计的好处是,实验步骤不再是一整段难以检查的自由文本,而被拆解为可解析的结构单元。
每一步做什么、作用于什么对象、在什么条件下完成,都可以被自动检查。
更重要的是,key和orc之间要求一一对应。
结构化步骤里出现的动作、对象和参数,必须在最终自然语言protocol中体现出来。这避免了模型只给出一个“空心框架”,却漏掉关键实验细节。
Thoth的第二个关键设计,是Structured COmponent-based REward,简称SCORE。
传统评估指标往往只看生成文本和参考答案像不像。SCORE则直接从实验可执行性的角度出发,评估三个维度:
第一是Step Scale,判断步骤数量和粒度是否合理。步骤太少,可能漏掉关键操作;步骤太多,则可能引入冗余和噪声。
第二是Action Order,判断动作顺序是否符合实验逻辑。对于实验来说,有些步骤即使都出现了,只要顺序错了,protocol仍然不可执行。
第三是Semantic Fidelity,判断动作、对象和参数是否匹配。例如“add”是否加到了正确试剂上,温度、浓度、时间等参数是否绑定到了正确对象。
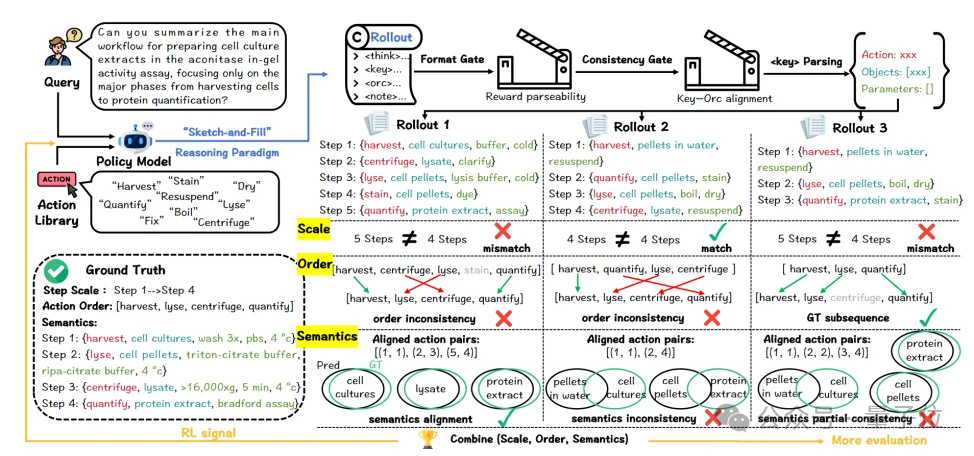
SCORE还加入了两个门控机制:格式门控检查模型是否按照think、key、orc、note顺序输出;一致性门控检查key中的动作、对象、参数是否被orc充分覆盖。
只有通过这些基础检查的protocol,才会进入后续奖励计算。
这样一来,模型优化目标就从“写得像参考答案”,变成了“生成结构合理、顺序正确、语义忠实、实验上更可执行的protocol”。
在训练层面,Thoth采用Knowledge-to-Action学习策略,让模型逐步从“掌握实验知识”过渡到“生成可执行实验方案”。
第一阶段是预训练,模型从大规模protocol文本中学习实验语言、材料、设备和流程逻辑。
第二阶段是监督微调,模型在Sketch-and-Fill格式数据上学习如何按照结构化范式组织输出,并完成参数填充、步骤排序、错误修正等任务。
第三阶段是强化学习,团队使用GRPO算法,并以SCORE作为奖励信号,引导模型在实验可执行性上继续优化。
这种训练路径与人类研究员的学习过程相似:先积累知识,再学习规范操作,最后通过反馈不断改进决策。
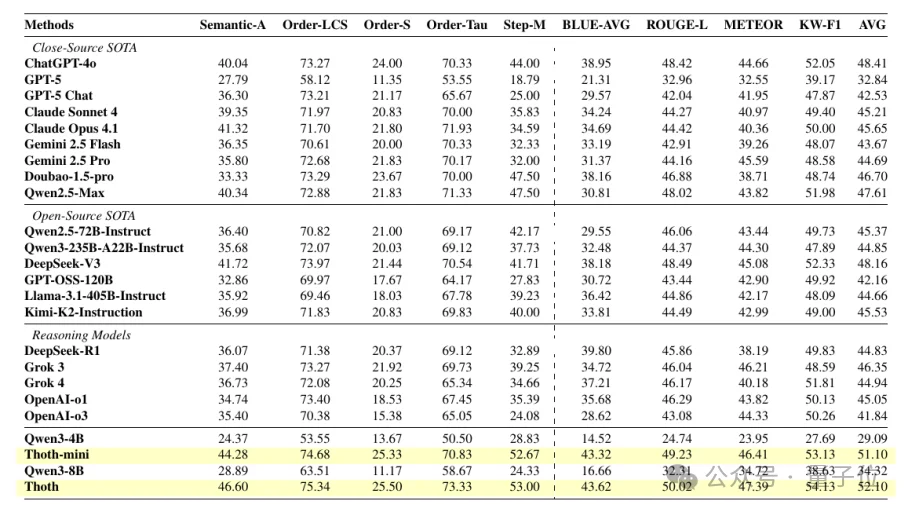
实验中,团队在SciRecipe-Eval上评估了Thoth,并与闭源模型、开源模型、推理模型和科学大模型进行对比。
结果显示,Thoth在所有主要指标上取得SOTA表现。
相比基座模型Qwen3-8B,Thoth平均性能提升17.78%;Thoth-mini平均性能提升22.01%。
即使面对更大规模的闭源模型,Thoth仍然表现突出,平均分超过ChatGPT-4o 3.69%。
在与最强开源模型DeepSeek-V3的对比中,Thoth在Semantic-Alignment、Order-S和Step-MATCH上分别提升4.88%、4.06%和11.29%,说明其优势主要体现在实验步骤对齐、逻辑顺序和动作保真上。
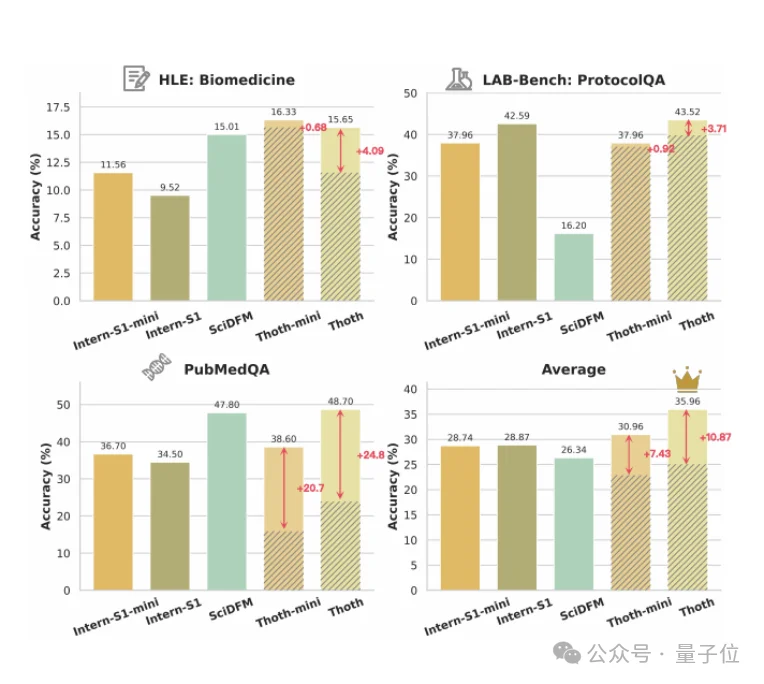
不仅如此,在HLE、LAB-Bench、PubMedQA等更广泛的科学基准上,Thoth同样能泛化到protocol生成之外的生物医学推理任务,相比同基座模型取得明显提升。
消融实验进一步证明,Sketch-and-Fill、SCORE和Knowledge-to-Action三阶段训练都不是“锦上添花”。
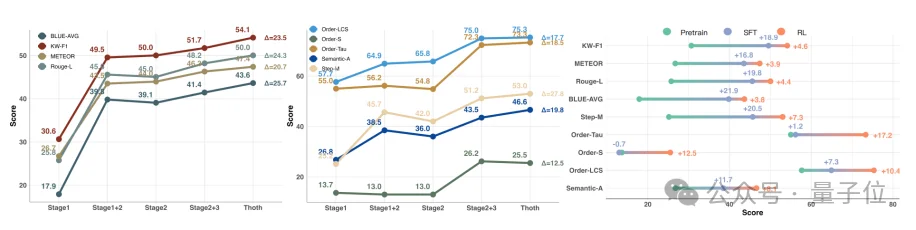
其中,去掉步骤粒度奖励后,模型的顺序严格匹配和步骤匹配大幅下降;去掉动作顺序约束后,模型更容易生成顺序混乱的方案;如果用普通语义相似度奖励替代SCORE,虽然部分词面指标可能变好,但protocol可执行性明显下降。
这说明,对于科学实验生成来说,真正重要的不是“文本像不像”,而是“能不能照着做”。
这项工作将生物实验protocol生成从普通文本生成,推进到面向实验执行的结构化科学推理。
通过SciRecipe,团队构建了覆盖27个生物学子领域、包含理解与问题解决任务的大规模数据基础;通过Sketch-and-Fill,模型学会先组织实验骨架,再生成自然语言步骤。
通过SCORE,训练和评估都直接对齐步骤粒度、动作顺序和语义保真。
通过Knowledge-to-Action训练,Thoth进一步从实验知识走向可执行方案生成。
从更长远看,Thoth代表了一类新的科学AI助手方向:它不只是回答“实验怎么做”,而是尝试把科学知识转化成可检查、可复现、可执行的实验行动。
对于生命科学研究来说,这意味着AI有机会从文献问答工具,进一步走向实验复现助手、protocol规划助手,乃至未来自动化实验系统中的核心推理模块。
论文链接:https://arxiv.org/abs/2510.15600
代码链接:https://github.com/InternScience/ThothThoth
模型API:https://scphub.intern-ai.org.cn/detail/19
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
