# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在联邦学习中,如何同时兼顾模型性能、数据隐私和通信开销,是一个亟需解决的挑战。
在实际应用中,各客户端往往采用不同的模型架构,例如部分客户端使用卷积神经网络,而其他客户端则采用Transformer,形成典型的模型异构场景,这进一步增加了联邦学习的优化难度。
为解决上述难题,来自中国信通院泰尔英福公司、清华大学等高校的联合研究团队,提出了一种基于表征纠缠的联邦学习框架(Federated Representation Entanglement,FedRE)。
该框架在保证模型性能的前提下,有效保护数据隐私并降低通信开销,同时可适配模型异构与模型同构两类联邦学习场景。

论文标题:FedRE: A Representation Entanglement Framework for Model-Heterogeneous Federated Learning
论文链接:https://arxiv.org/pdf/2511.22265
代码仓库:https://github.com/AIResearch-Group/FedRE
在模型异构场景下,多个客户端采用不同架构的表征提取器(如ResNet,ViT),但分类器架构保持一致(即任务一致),因此无法像FedAvg那样直接进行模型参数的聚合。
为解决这一问题,一个可行思路是利用客户端表征在服务器端训练全局分类器,同时兼顾隐私保护与通信效率。
一种朴素的方法是FedAllRep,该方法将每个客户端的所有样本表征上传至服务器用于训练全局分类器。
由于能够充分利用所有样本的表征,该方法通常能够获得较好的模型性能(如Figure 2左图所示),但其通信开销较大,并且容易受到表征逆向攻击进而泄漏隐私。
为缓解此问题,FedGH采用类别原型作为客户端知识上传至服务器训练全局分类器。
该方法能够有效降低通信成本并增强隐私保护能力。但由于类原型主要刻画类别中心信息,可能导致全局分类器过度关注类别原型,进而形成较为尖锐的决策边界(如Figure 2中间所示),最终影响模型性能。
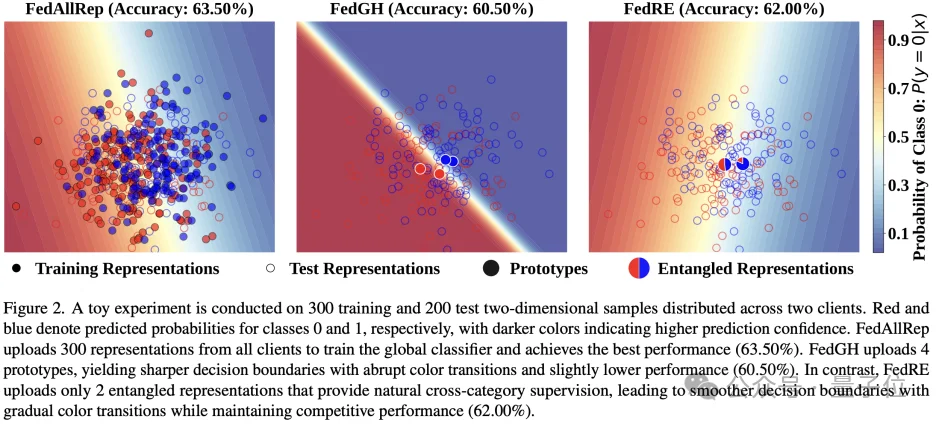
上述方法的局限性启发了FedRE的设计,其引入纠缠表征作为一种新的客户端知识表示方式。
具体而言,在每个客户端,FedRE通过随机加权的方式,将来自不同类别的本地表征融合为一个纠缠表征,并生成对应的纠缠标签编码。
随后,每个客户端仅需上传一个纠缠表征及其纠缠标签编码至服务器,用于训练全局分类器。
由于纠缠标签包含跨类别的监督信号,且在每一轮通信中都会重新采样权重以增加多样性,全局分类器在训练过程中能够同时考虑多个类别,从而避免对单一类别过度自信,学习到更加平滑的决策边界(如Figure 2右图所示)。
此外,一个纠缠表征融合了客户端的所有本地表征,增加了表征逆向攻击的难度;同时,每个客户端仅上传一个纠缠表征,也进一步降低了通信开销。
如图所示,FedRE框架主要包含三个步骤:
第一,各客户端利用本地数据完成局部模型训练更新。
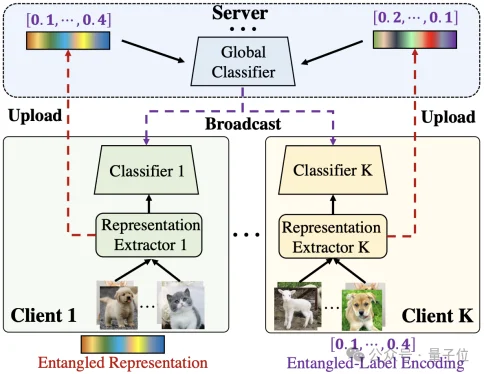
第二,各客户端对本地所有表征进行聚合(具体方法请参考原文,可采用多种策略),生成统一的纠缠表征,同时聚合对应的标签编码形成统一的纠缠标签编码,并上传至服务器。
最后,服务器利用收到的纠缠表征训练全局分类器,并将更新后的全局模型下发给各客户端,用于替换局部模型的分类器,进入下一轮迭代。
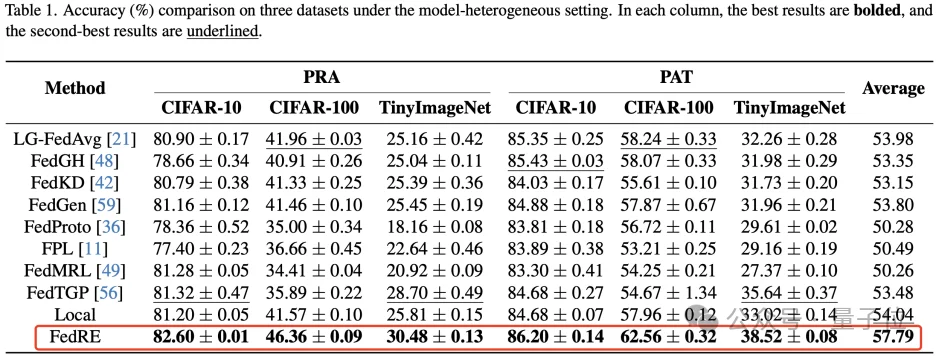
Table 1展示了模型异构设置下的实验结果(模型同构结果请参见原文附录)。
整体来看,FedRE取得了较为优异的性能表现,并优于FedGH。
这在一定程度上表明,相较于基于类别原型的方法,采用纠缠表征训练全局分类器可能更加有效。
为评估隐私保护能力,分别对原始表征、类别原型与纠缠表征进行表征逆向攻击重建原始样本。
Figure 4展示TinyImageNet结果:原始表征可较清晰恢复轮廓,存在较高攻击风险;类别原型可一定程度上恢复类别信息(如鱼类轮廓)。
而纠缠表征重建结果几乎不可辨识,表明其通过多类别信息融合显著降低了样本可恢复性。

Table 2可以看到,FedRE在上传阶段的通信开销最低,因为每个客户端只需上传一个纠缠表征及其对应的标签编码。
在广播阶段,其通信开销与基于分类器的方法(如LG-FedAvg)和基于原型的方法(如FedProto)大致相当。
在数据要素流通与隐私合规要求日益严格的背景下,如何兼顾数据价值挖掘与敏感信息防护,已成为行业面临的核心挑战。
为此,本文提出FedRE方法以解决模型异构的联邦学习问题,在性能、隐私保护与通信开销之间实现了较为均衡的权衡,为数据要素安全流通提供了一种可行路径。
文章来自于"量子位",作者 "FedRE团队"。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
