# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型真的只能走“预测下一个token”的路子吗?
继何恺明之后,字节也给出了同样的回答:NO。
并且,两边都不约而同地盯上了同一个方向——在连续语义空间中建模语言。
更关键的是,字节这次直接开源开到底,论文、代码、模型权重、中文博客通通释出。

帮大家快速回忆一下。就在上周,何恺明团队推出首个扩散语言模型ELF——
它跳过token层,把整个生成过程留在连续embedding空间里完成,仅用105M参数就跑赢一众主流扩散语言模型,第一次证明连续路线在语言生成上真有潜力。
而字节这次带来的Cola DLM(Continuous Latent Diffusion Language Model),则进一步佐证了这一趋势。
他们同样选择跳出离散token的束缚,把生成过程交给连续空间,结果是:
在~2B参数、约2000 EFLOPs的严格对照实验下,Cola DLM展现出了比自回归模型和主流离散DLM更稳定的scaling趋势。
然而,正当你以为这不过是又一个“把图像扩散模型搬进语言领域”的故事时,字节却告诉你:错了。
Cola DLM的motivation从来不是diffusion。
啊??不是为了diffusion,结果做了个diffusion language model?
事实上,真正的主角藏在这句话的后半段:
Cola DLM的motivation从来不是diffusion,而是representation(表征)。
在字节看来,真正重要的是表征,Token这种tokenizer工程和历史演化的副产物,仅仅是表征被实现出来的一种形式而已。他们还大胆给出了一个暴论:
Token是人类语言系统的表层载体,不是语义本身。
简单看一个例子你就懂了,比如我们用不同的话表达同一个意思:
token差了一大堆,但语义还是那一个。
放在以前,主流大模型通常会把这些不同说法,当成几套不同的表达分别去学——明明背后是同一个语义,模型偏偏要在token这个表层挨个对齐。
所以字节的判断是,如果模型内部存在一种更稳定、更抽象的“语义状态”,那这些本质相同、只是说法不同的句子,其实没必要被分别记忆,而是可以在内部收敛到相近的表示。因此本质上而言:
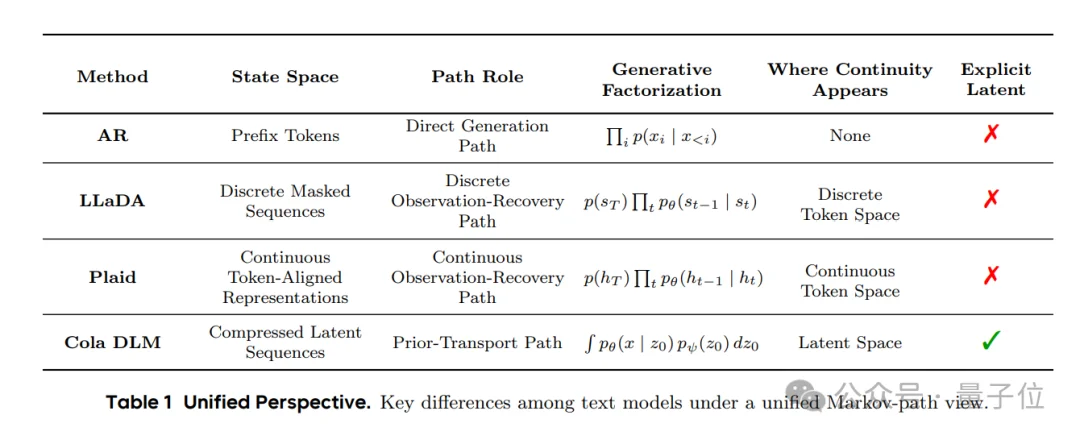
Cola DLM的diffusion不是在恢复token,而是在transport一个latent prior。
怎么“transport一个latent prior”?字节选择直接把语义和实现分层。
具体方法论指路论文3.1.1,这里我们简单翻译过来就是:
Cola DLM的生成模型,本质上只有两部分。一个latent prior,负责生成“潜在语义”; 一个decoder,负责把这些语义翻译成具体文字。 看上去就像是把“生成一句话”拆成了两件相对独立的事。
而且关键在于,整个diffusion/flow matching过程,其实都发生在latent空间里,而不是token空间里。
就是说,Cola DLM干的不是把一堆脏token慢慢去噪成干净token,而是先在连续语义空间里,把一团随机语义慢慢组织成有意义的潜在表达,最后再统一翻译成文字。

所以在它的生成路径里,其实根本没有token的逐步生成过程,token只在最后一步才出现,前面学的都是“语义怎么形成”。
这也是Cola DLM和很多扩散语言模型最大的不同。
很多DLM,本质上还是围绕token在做“修修补补”,比如恢复被mask的token、逐步还原离散文本。但Cola DLM直接把diffusion从“文字层”搬到了“语义层”,diffusion不再负责“生成token”,而是负责“组织语义”。在字节看来:
这不是包装上的差异,而是改变了diffusion在模型里到底干什么。
方法论我们知道了,那Cola DLM真正“和传统连续DLM拉开差距”的地方到底在哪?
答案,就藏在几个很工程化但很关键的设计选择里。
首先是latent是怎么来的。很多人一听“连续语言模型”,第一反应是——不就是在word embedding上做扩散嘛。
但Cola DLM偏偏没这么做,它专门搭了一套Text VAE:
差别在哪?token embedding还是和token一一绑定的,每个token一个向量,本质上还是token序列。
而Cola DLM要的latent,是一个可以连续变化、可被概率建模的随机变量。
这样一来,模型处理的对象就不再是“下一个token”,而是“整段文本对应的语义状态”。
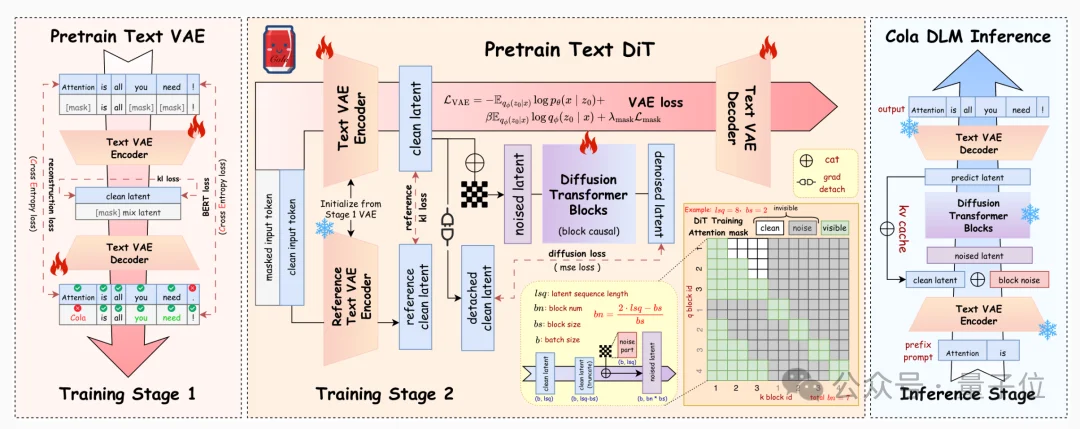
Cola DLM用的不是大家熟悉的“加噪→去噪”那种diffusion,而是一个叫block-causal DiT+Flow Matching的组合。
组合看不懂不要紧,知道这个组合做的事就行了:
说白了就是,不靠反复去噪,而是直接学一条“最优路径”,把噪声平滑地引向有意义的语义。
更妙的是,它在这个语义路径上还引入了block结构——
块内并行搞定局部语义的快速组织,块间按因果顺序保证整体逻辑不乱。
整体相当于在语义层重新搭了一套生成框架,“局部快、整体顺”,两样都没丢。
连续扩散语言模型有一个常见问题:
语义表示latent很容易被diffusion带偏,最后退化成一个“穿了马甲的token”,即表面是连续向量,但骨子里还是在记词,根本没形成真正的语义抽象。
所以Cola DLM的做法是——把两个任务彻底分开。
而且训练时,Encoder在diffusion阶段基本“冻结不动”。
为什么不让它也跟着学?因为一旦让Encoder去适应diffusion,它就会为了降低loss而偷懒,把语义表示悄悄滑向“好预测的token形式”,最后又回到老路上。
字节想要的是一个稳定的语义空间,而不是一个被任务污染的中介层。所以他们反其道而行之,让prior去适应语义空间,而不是让语义空间讨好prior。
此外,他们还加了一个语义约束(BERT-style mask loss),防止encoder在重建时“语义坍塌”。
实验证明,没有这个约束,latent确实会为了降loss而漂走。
如果说前面三点更像工程上的巧思,而这第四点就是Cola DLM在理论上的硬功夫。
字节把训练目标拆成了三个可以单独看、单独诊断的子任务:
这样拆的好处在于,传统自回归把所有东西都糊在一个“预测下一个词”的损失函数里。
生成效果不好时,你根本不知道是哪里出了问题,不知道是理解错了、记忆不够,还是生成路径歪了。
而Cola DLM把账算得清清楚楚,哪里不行分别看指标就知道。
这也它能跑出稳定scaling趋势的底层原因——
不是瞎蒙,而是每一个环节都能单独诊断、单独优化。
最后鉴于篇幅原因,这里我们直接放上字节Cola DLM研究的成果省流版(详细内容指路博客):

而说到这里,我们很难不把字节Cola DLM与何恺明团队的ELF放在一起看。
很有意思的是,两份工作几乎同期,都在挑战一个被默认了二十年的假设——
语言模型必须建立在离散token上。
为什么这个假设开始受到质疑?
一方面,自回归大模型走到今天,“预测下一个token”这条路的瓶颈越来越明显——推理慢、长程依赖弱、训练目标和真实生成质量之间存在结构性gap。
另一方面,扩散模型在图像、视频生成上的成功,让大家开始反思:离散token真的是语言智能必须依附的载体吗?还是只是历史选择的一种习惯?
这两年扩散语言模型的探索(LLaDA、Dream-7B、MDLM等)已经把这个问题拉到了台面上,但大多数工作还停留在“离散派”——还是在token上做扩散。
直到ELF和Cola DLM出现,两边几乎同时给出了同一个答案——不必绑在token上。
只不过具体解法上有所不同。
我也去对比了两项研究之前的区别,用图片展示如下:
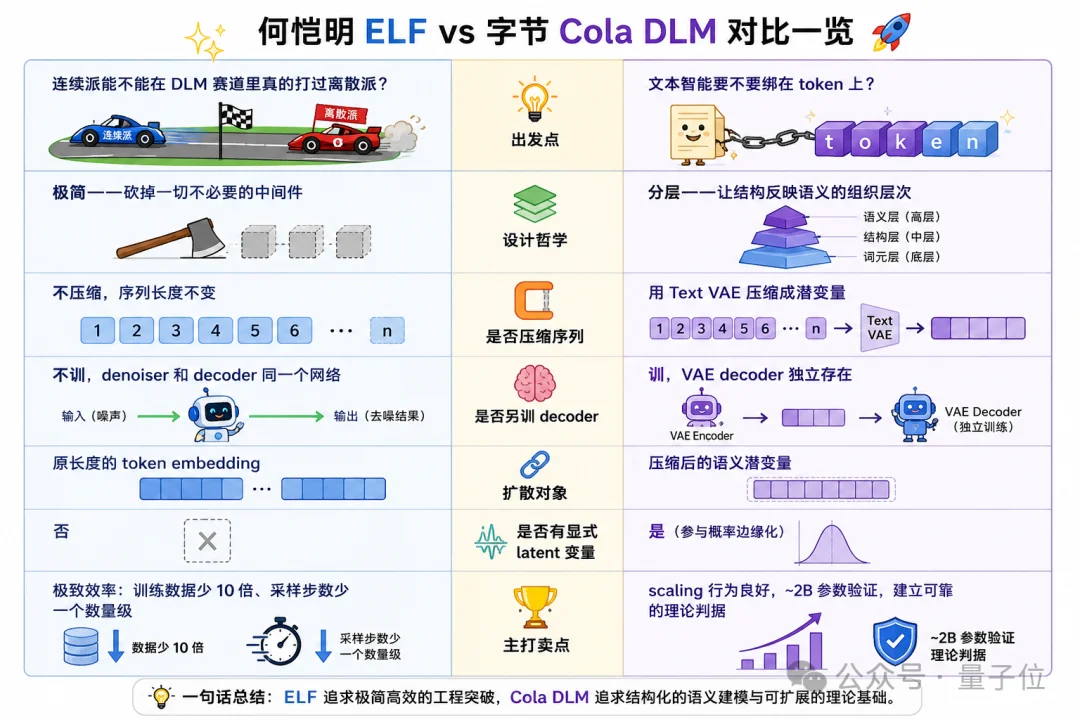
简单说,ELF像一个人从头干到尾,在原长度embedding空间里反复琢磨,到最后一步才落笔成字。
Cola DLM则像两个分工部门,语义部先讨论“要表达什么”,文字部再负责“具体怎么写”。
两条路线方法上虽然不同,但底层关切完全一致——
让建模发生在最适合语言本质的表示空间里,不要被“token=语义”这个默认框架限定。
本质上而言,它们其实是同一个问题的两种回答。
而这也代表着一种趋势——是时候重新认识连续扩散语言模型了。
过去两年,扩散语言模型的舞台几乎一直由“离散派”占据。但ELF和Cola DLM这一前一后两次出手,让“连续路线”第一次以一种严肃、可被对比、可被复现的姿态站到了台前。
更值得注意的是,Cola DLM还顺手指出了一件更大的事——长期以来“统一多模态”卡住的核心障碍之一,就是文本是离散的,而图像、视频、音频天然偏连续。
如果想让它们真正进入同一个“latent世界”,必须有一个把文本映射到连续语义latent的接口。
而Cola DLM恰好扮演了这样的角色。而这,或许才是字节这次出手的真正野心——
不是在扩散语言模型的赛道里再添一名选手,而是为语言模型造一座桥,把它接入连续多模态的世界。
当然,Cola DLM团队自己也很克制,他们在博客最后写道:
Cola DLM只是这条路上的一次早期尝试,但这条路本身值得继续走下去。
最后按照惯例介绍一下这项研究的作者。
整个团队由字节跳动Seed团队主导,集结了来自港大、人大、北大、北邮、澳国立多所高校的研究者,覆盖语言建模、扩散模型、视频生成等多个方向。

第一署名Hongcan Guo(郭泓灿),目前是北邮人工智能学院大四本科生,从2025年6月起在字节Seed实习。
研究兴趣集中在生成模型与推理模型的数学基础和学习动力学,Cola DLM的博客正是出自他手。

通讯作者Yan Zeng(曾妍)则是字节Seed内部的“大牛级”人物,她是字节爆款视频生成模型Seedance系列的研发负责人。有资料显示,这位西安交大校友2021年以校招生身份加入字节后,仅用了五年就从算法工程师晋升至4-2职级。
这次Cola DLM里很多“分层潜变量+diffusion prior”的思路,与视频生成领域长期采用的latent diffusion路线存在明显相通之处。
团队里还有一位很有意思的“跨界选手”——Shen Nie。他是人大高瓴AI学院李崇轩组的代表性研究者,同时也是离散扩散语言模型LLaDA的第一作者。而LLaDA恰恰也是Cola DLM在论文里重点比较的一条离散扩散路线。
某种意义上,这件事本身就挺有意思:一位离散扩散路线的代表人物,也参与到了连续latent路线的研究里。某种程度上也说明,Cola DLM这次真正想讨论的,已经不只是“扩散怎么生成文本”,而是更底层的:
文本智能到底应该建立在什么样的状态空间之上?
其他几位核心作者同样来头不小。
Hengshuang Zhao是香港大学计算机系助理教授,曾在MIT CSAIL、牛津Torr Vision Group做博士后,长期活跃于计算机视觉与生成建模领域。
Qiushan Guo则来自港大MMLab羅平组,同时也是字节Seedream图像生成模型的重要研发成员之一。
其他署名作者还有:Qinyu Zhao、Yian Zhao、Rui Zhu、Feng Wang、Tao Yang、Guoqiang Wei。
实际上,如果把整份作者名单放在一起看,其实会发现一个非常有意思的现象——
字节这次做语言模型,某种程度上几乎是把“视频/视觉生成”那套核心思路整体带了进来:
做latent diffusion的、做视频生成的、做图像prior的、做离散DLM的,最后一起重新思考“文本到底该怎么建模”。
这或许也是为什么Cola DLM整体看上去,会和传统语言模型路线呈现出非常不同的气质。
因为它从一开始关注的,就不只是“如何更好地生成文本”,而是在尝试把语言重新放回连续语义空间里,变成一种能够与图像、视频、音频自然对齐的模态。
而这,也许才是Cola DLM最值得关注的地方:
当文本不再只是token序列,而成为连续世界中的一种语义状态后,多模态智能又会长成什么样。
抱抱脸地址:https://huggingface.co/ByteDance-Seed/Cola-DLM
GitHub地址:https://github.com/ByteDance-Seed/Cola-DLM
论文:https://arxiv.org/abs/2605.06548
博客:https://hongcanguo.github.io/posts/2026-cola-dlm-zh.html
文章来自于"量子位",作者 "一水"。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
