# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,京东和中科院信工所展开了Self-Taught RLVR的系列研究,并连发三篇后训练新作。
这一系列的核心命题只有一个:
如何让大模型自我指导,实现迭代演化?
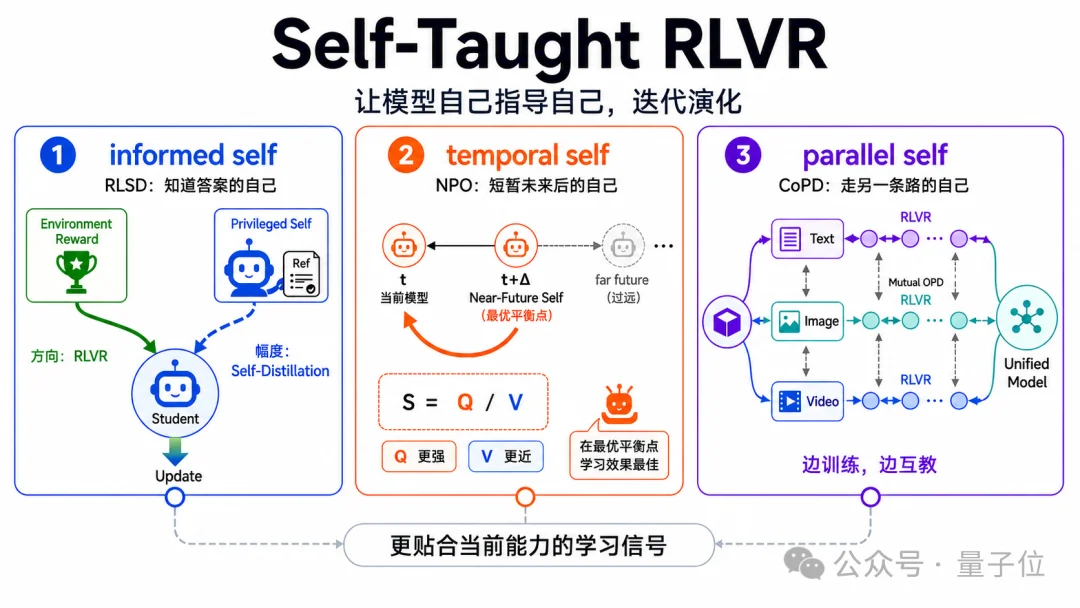
研究者对Self-Taught探索了三个互补维度:
1、RLSD:探究informed self——由特权信息增强的自身来教自己;
2、NPO:聚焦temporal self——由近未来的自身教自己;
3、CoPD:探究parallel-self——由走另一条路的自身来教自己。



这三篇文章分别面向RLVR和OPD的热点问题:
虽然这些问题看似不同,但实则都有着相同的本质,就是如何引入更好的学习信号并被模型有效地吸收。
Self-Taught RLVR系列研究则给出了同一个答案:让模型自己为自己提供贴合当前能力的,更易吸收的学习信号。
以下是三篇系列文章的详细内容。
第一篇RLSD(RLVR with Self-Distillation) 关心的问题是:
当我们给同一个模型注入特权信息(比如参考答案)后,它能不能成为老师来指导自己?
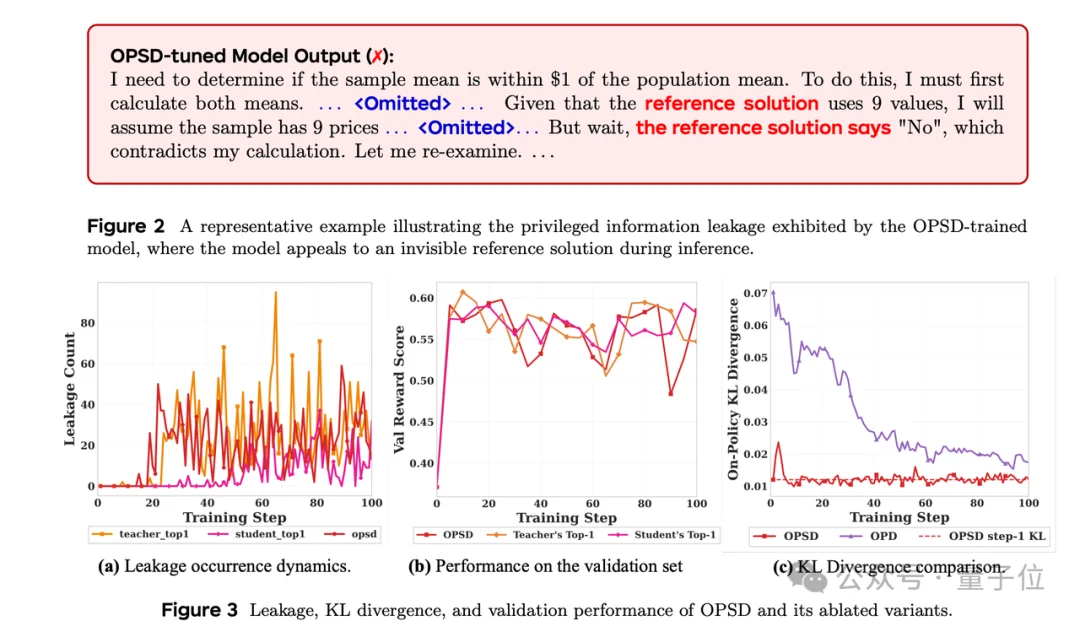
这个setting之前已经被OPSD(On-Policy Self-Distillation) 探索过,比如:Self-distilled reasoner:On-policy self-distillation for large language models和Reinforcement learning via self-distillation,但是结果很尴尬:
模型在极少数据上快速收敛(大概20step以内),之后很快就开始信息泄漏,在推理时想当然地引用一个其实它并没有看到的“参考解”来解决问题,回答风格变为如下图所示的情况,并紧接着性能逐渐坍塌。
RLSD这篇论文做了两件事:
理论上,作者证明了OPSD的目标函数是ill-posed的,这个训练目标中存在一个不可消除的项mutual information gap(I(Yt; R | X, Y 0)。
不同于常规的条件一致的OPD,OPSD中的老师条件在特权信息上、而学生看不到这个特权信息,在这种情况下这个gap就永远抹不掉,KL散度也就永远降不下去。每一步训练都在悄悄把x→r的虚假相关性写进参数里,最终影响梯度方向。
方法上,RLSD 给出了一个简单优雅的修复:
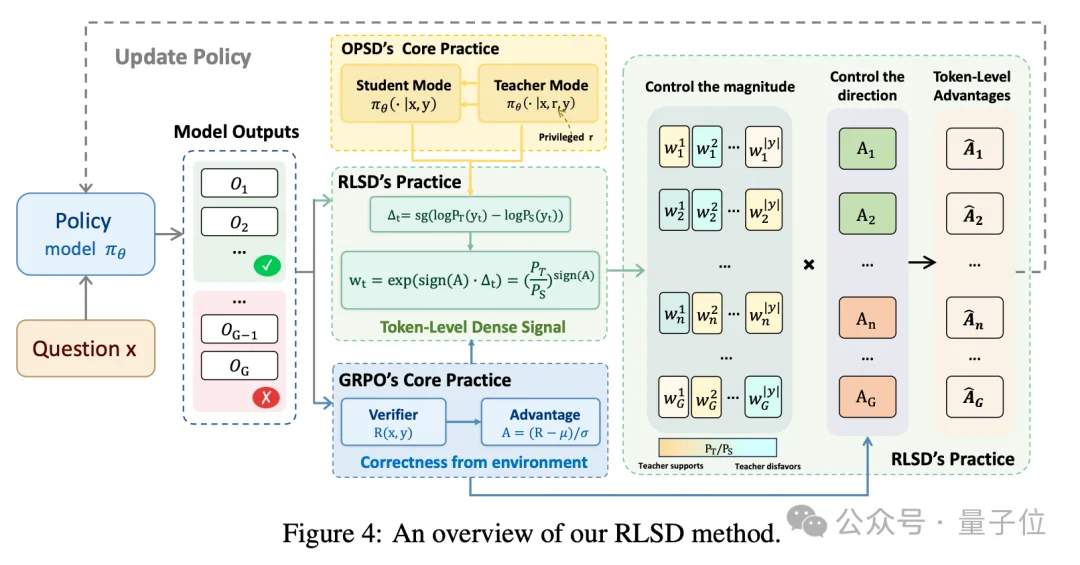
通过把“用对方向”和“分清主次”这两件本来纠缠在一起的事情解耦,RLSD就成了RLVR和OPSD的自然的合体,既继承了OPSD的token-level密集信号,又重新拿回了RLVR来自环境的可靠信号锚定。
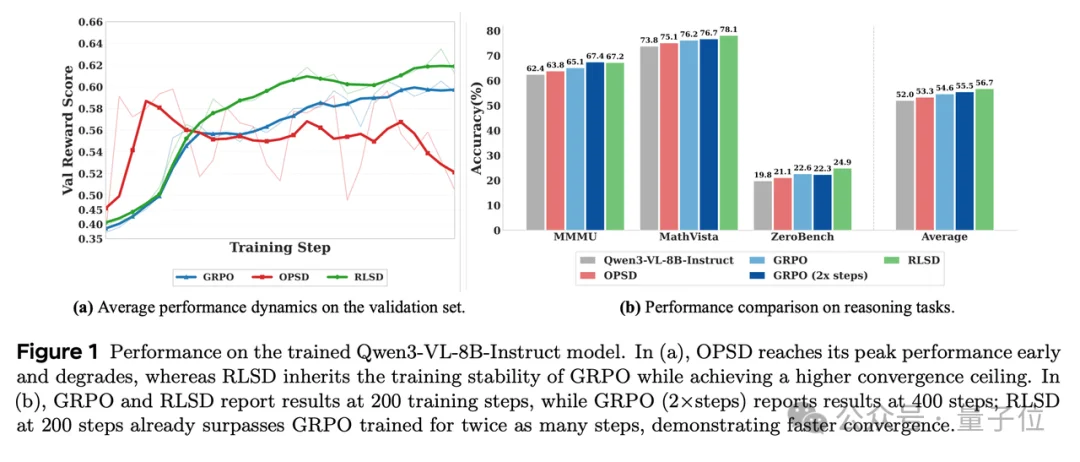
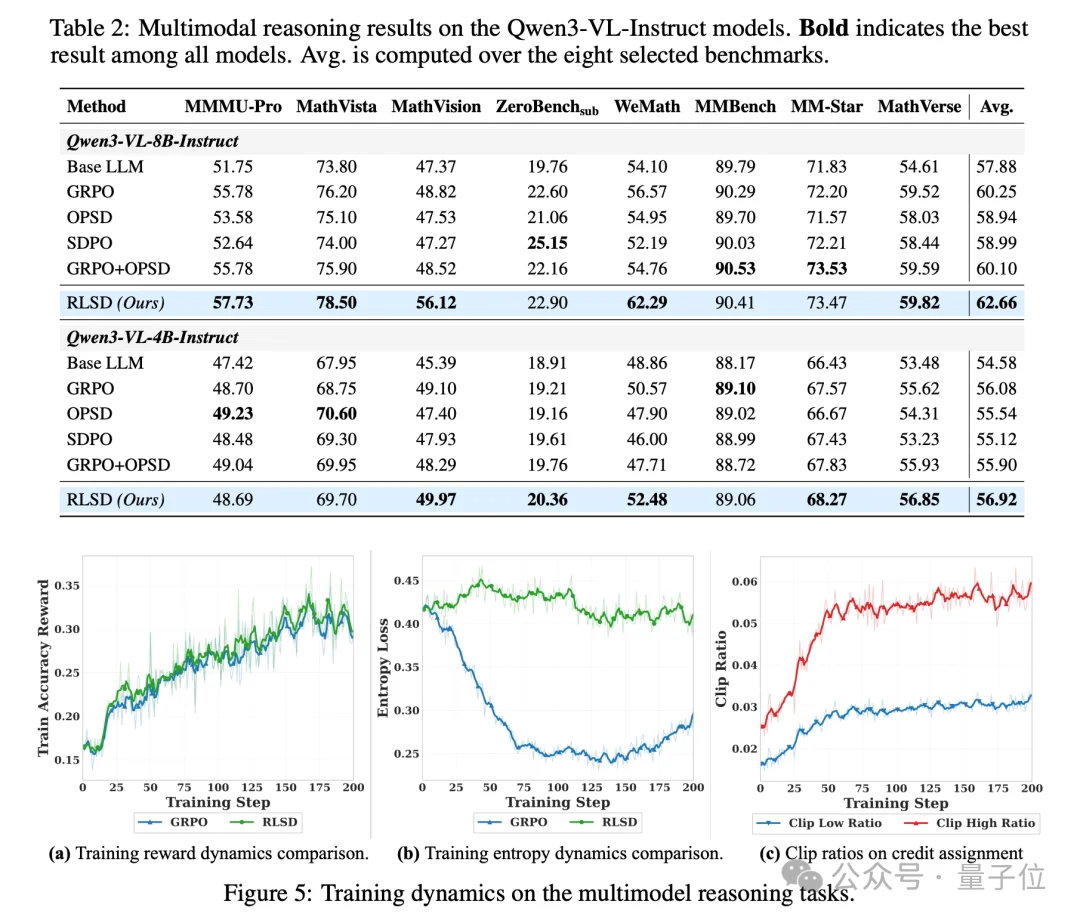
至于效果,在Qwen3-VL-8B-Instruct以及文本、图片、视频的8个benchmark 上,同时打败了一系列的baseline,不仅收敛速度更快,而且最终性能上限更高,200步训练就超过GRPO训400步的水平。
如果用漫画总结就是:

第二篇NPO(Near-Future Policy Optimization)关心的是一个看起来朴素、根本的问题:
为RLVR引入什么样的辅助学习信号能带来最大收益?
研究者把这件事抽象成了一个简洁的指标:有效学习信号S=Q/V。
也就是说,一条好的辅助轨迹要足够强(高Q,有新东西可学)的同时还得足够近(低V,模型容易吸收)。
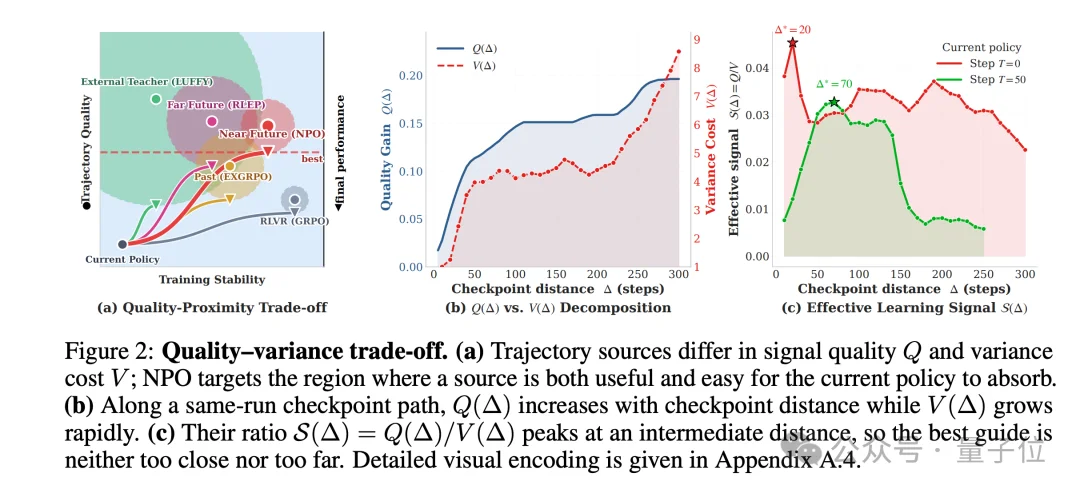
之前的方法都顾不全这一点:从外部老师导入轨迹,Q高但V太大;从经验回放(Experience Replay)抓自己过去的轨迹,V低但Q又被自身历史水平卡死。
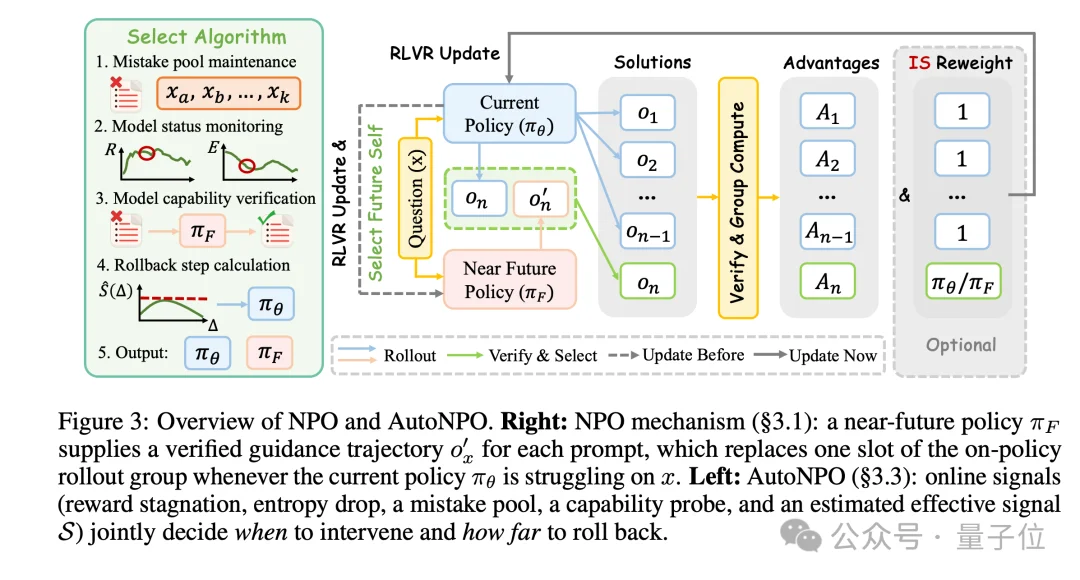
NPO的核心思想可以一句话概括:用未来的自己来引导当下的自己。简单来说,就是一个比当前更强(沿优化方向走了若干步),但又离当前足够近(同一条优化进程上的延伸)的天然teacher。
作者从理论上和实证上都证明了这种设计能最大化有效学习信号S=Q/V。
在具体实现上,本文采用mixed-policy的方式:把near-future checkpoint产生的、被验证为正确的trajectory混入当前rollout group,既加速早期bootstrap,也帮助后期突破plateau。
进一步,作者还提出了AutoNPO,自动从在线训练信号里检测干预时机、自动挑选S最大的guide checkpoint。
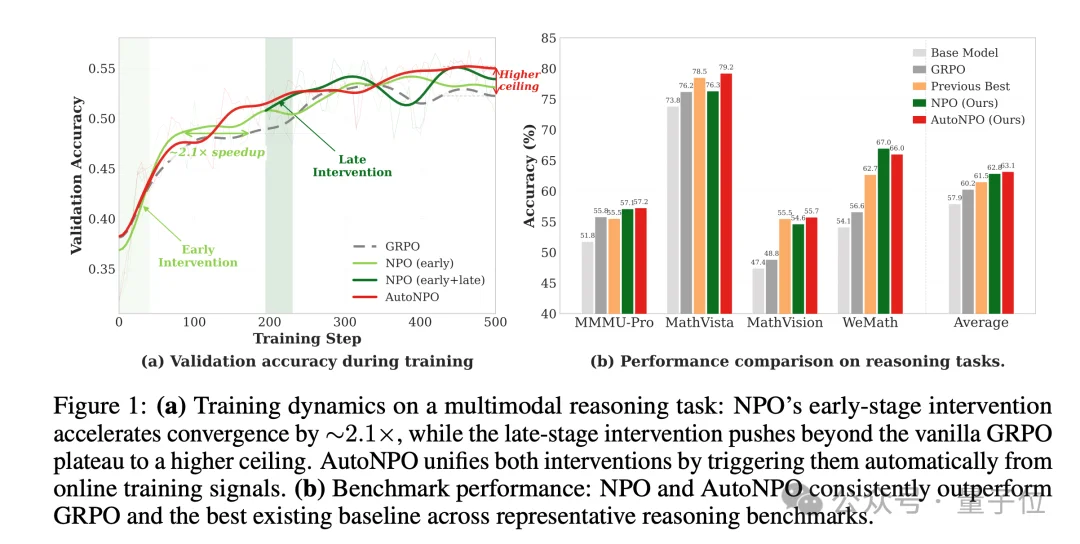
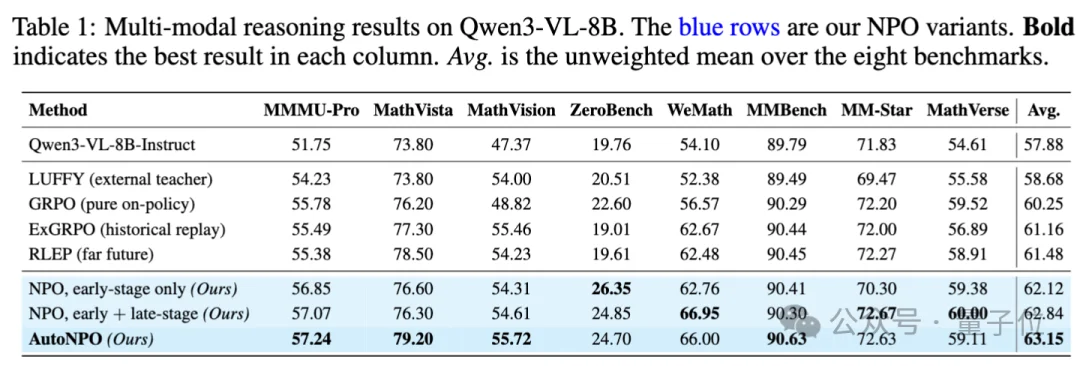
最终在Qwen3-VL-8B-Instruct上,GRPO平均分从57.88提升到NPO的62.84,AutoNPO进一步推到63.15,在收敛速度和最终上限上同时打败LUFFY等mixed-policy基线。
值得一提的是,本文采用了mixed-policy的实现方式,但near-future self这个思想本身远不止这一种用法——后续工作完全可以用OPD等其他方式来引入near-future信号,效果应该同样显著。
另外,漫画总结如下:

第三篇CoPD(Co-Evolving Policy Distillation)关心的是一个非常热的问题:
如何更好地把多个expert的能力吸收到同一个模型上?
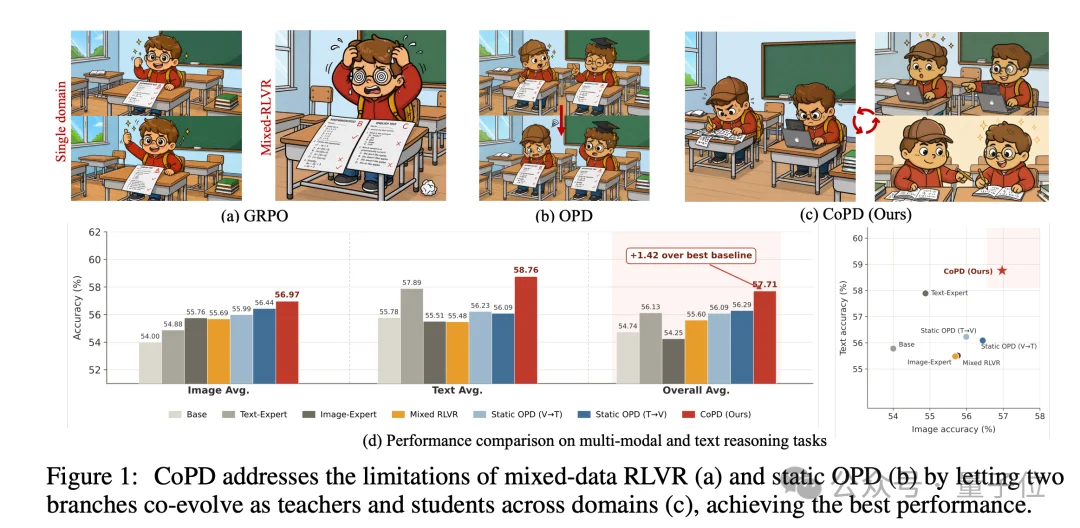
研究者在统一视角下识别出现有两条主流路径都各有问题。要把多个专家能力整合到一个模型里,直觉上无非两种思路:要么一起练,要么分开练再合并。
为了看清它们各自问题在哪里,研究者将两者放进同一个效用框架。
设X(D₁, D₂) 为两个数据集包含的总优化信号(即理想情况下能实现的能力增益),则任何范式P的实际效用可以写成:
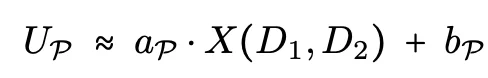
其中aₚ∈[0,1]衡量信号的转化效率,bₚ≤0捕捉额外损失。
在这个框架下,两种路径的损失来源一目了然:
信号全部参与优化(aₚ=1),但多个能力共享同一组参数,梯度方向互相冲突,要额外承担能力发散代价bₚ=−Φ。表现为典型的seesaw效应:一个能力涨了,另一个就跌。
调数据配比改变不了这个本质,只要混着训,就得付这笔”打架税”。
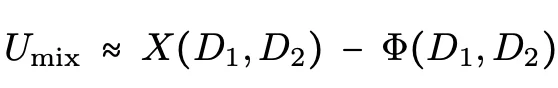
分开训练消除了发散代价(bₚ=0),但代价转移到了信号转化率上:aₚ远小于1。
专家确实学到了很强的能力,但蒸馏到student的时候只传过去了一部分。
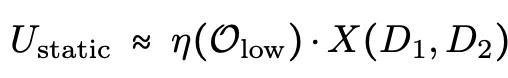
一个丢在bₚ上,一个丢在aₚ上——两种路径的能力损失是对称的。那能不能同时做到b=0且a足够高?这取决于一个前置问题:aₚ到底受什么控制?
作者的假说是:aₚ取决于teacher和student的行为有多像——越像,监督信号越容易被吸收。
就像学游泳,教练的动作和你的水平差不多时,你一看就能模仿;但如果教练直接表演奥运级蝶泳,你只能干看着学不会。
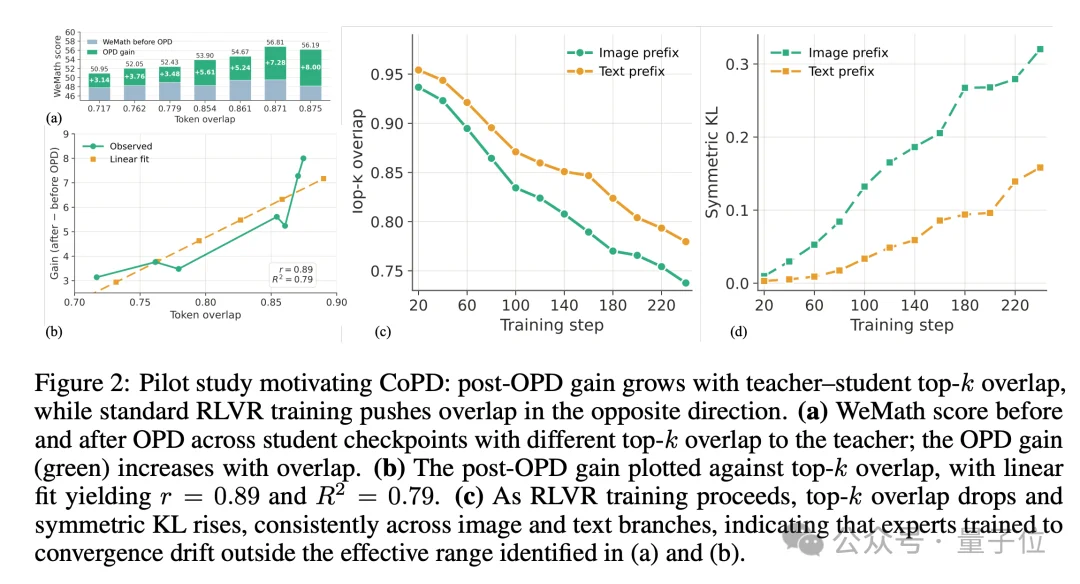
为此,作者用token overlap(student生成的轨迹上,两者top-k token交集的比例)来量化这种一致性,并通过两组实验验证:
也就是说,aₚ本质上是teacher-student行为重合度O的函数η(O):O越高,吸收越高效。但也不能完全一样——完全一致意味着teacher没有新东西可教,增益同样归零。而静态OPD恰好在O最低的时刻做蒸馏,aₚ被压到了很低的水平。
因此,CoPD 给出了一个全新的解题思路:
expert间的蒸馏应该在其训练期间进行,而不是训练之后,并且多个expert应当互为师生,协同进化。
具体地,CoPD并行训练多个分支,每个分支训练特定的expert ,并且把以下两件事交错进行:
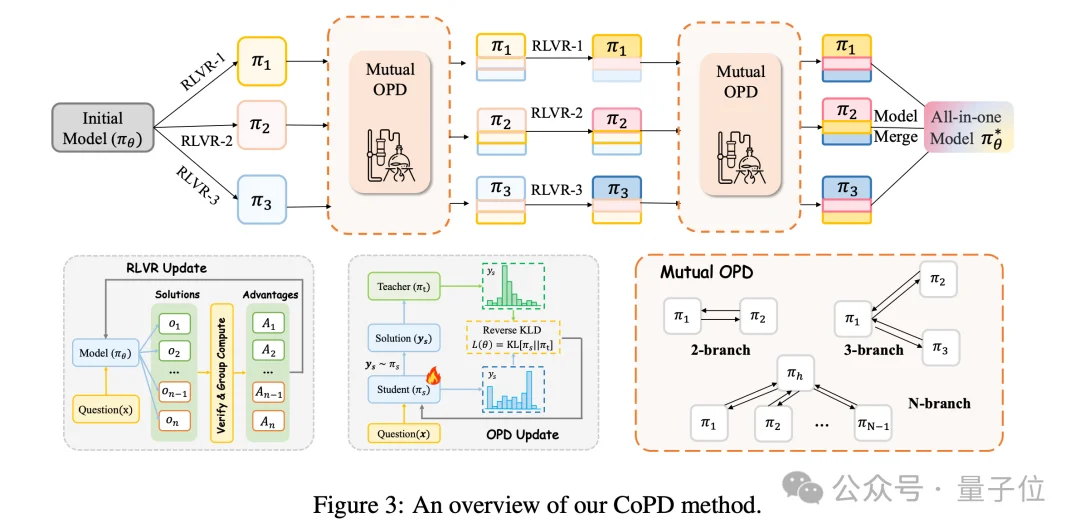
直观比喻就是,与其等多个独立训练完的专家“分家”后强行OPD到一起(像两个长大的成年人合住,生活习惯都难改),不如让他们从一开始就一起长大(像一起长大的兄弟,行为模式天然一致),长大的过程中各自练各自的本事(RLVR),时不时的就互相教学(mutual OPD)。
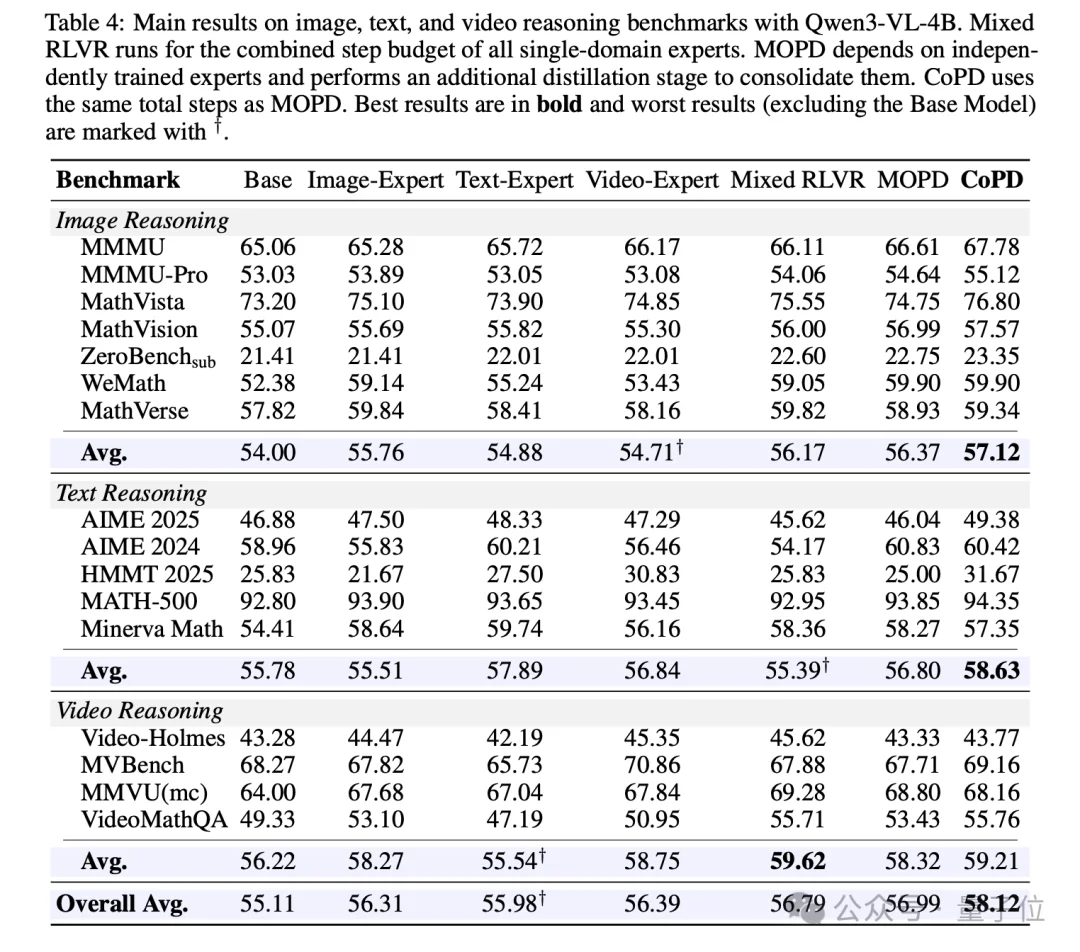
最终效果上,文本、图像、视频三合一,单一模型同时打败各自领域的独立专家、也打败了MOPD基线。
更值得关注的是CoPD的潜在意义——它给出了一种全新的model parallel training模式,这或许暗示着一种新的scaling范式。
漫画总结如下:

总的来说,三篇论文可以表示为:
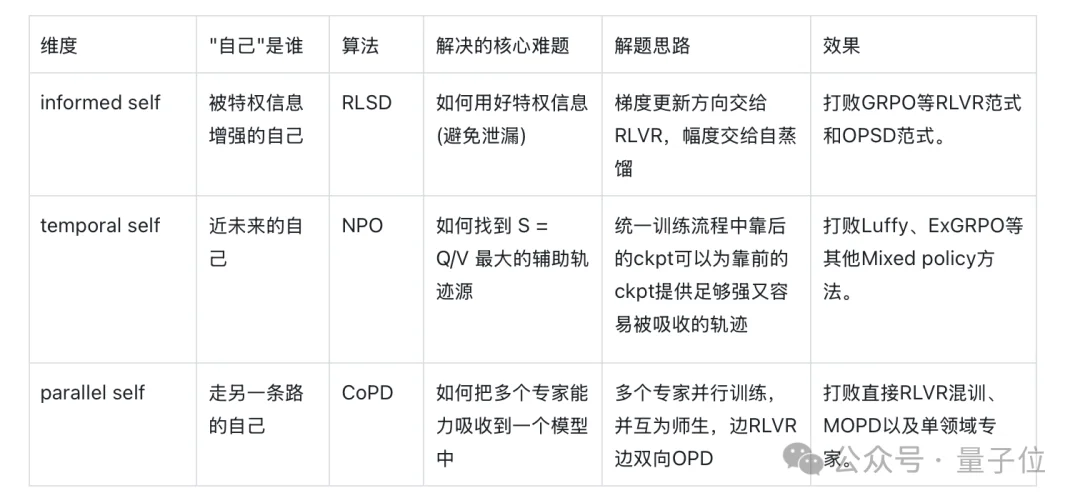
但Self-Taught RLVR远不止这三个维度。
模型完全可以从更多形式的“自己”身上学习——不同条件化的自己、以不同温度采样的自己、human in-the-loop后的自己、不同prompt的自己等等,也欢迎大家一起来探索。
Self-taught RLVR系列的三篇工作第一作者分别是中科院信工所杨晨旭、秦川于、顾佴彬,project lead是佀庆一(京东探索研究院),下一个系列研究会更精彩,欢迎持续关注。
RLSD论文链接:arxiv.org/abs/2604.03128
RLSD HuggingFace链接:https://huggingface.co/papers/2604.03128
RLSD GitHub链接:https://github.com/iie-ycx/RLSD
NPO论文链接:arxiv.org/abs/2604.20733
NPO HuggingFace链接:https://huggingface.co/papers/2604.20733
CoPD论文链接:arxiv.org/abs/2604.27083
CoPD HuggingFace链接:https://huggingface.co/papers/2604.27083
文章来自于"量子位",作者 "京东&中科院信工所"。



【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
