# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。
多模态 rollout 走 vLLM-Omni 的异步高吞吐 serving,VLM-as-judge / OCR 奖励模型走 vLLM 推理,并与 rollout、训练 overlap。Qwen-Image OCR FlowGRPO 演示中,把奖励模型放到独立 GPU 可将每步 wall-clock 时间降低约 14%。
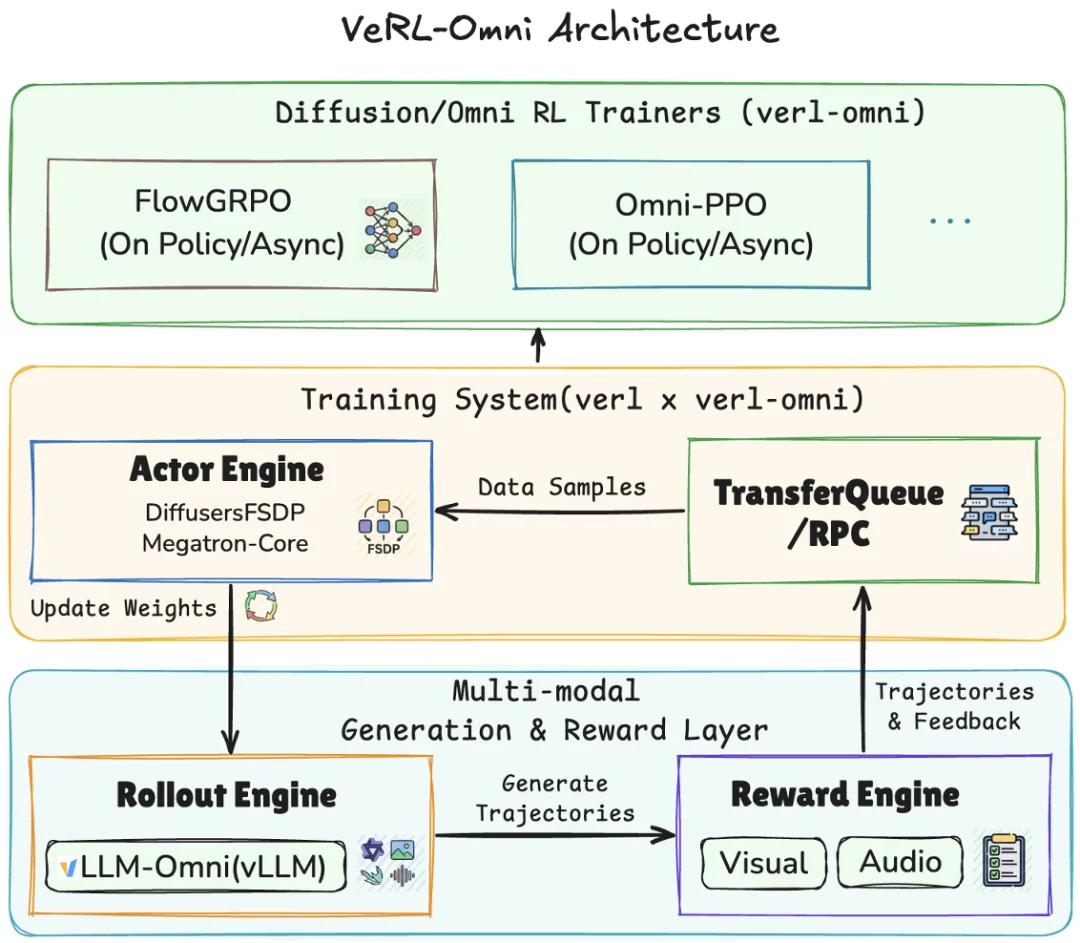
VeRL-Omni 架构
RL 已经成为把大型生成模型对齐到人类偏好与下游任务奖励的有力手段。过去一年 LLM 的 RL 训练栈飞快演进,但多模态生成 RL—— 覆盖图像 / 视频 / 音频理解与生成的扩散和全模态模型 —— 还有几个关键缺口:
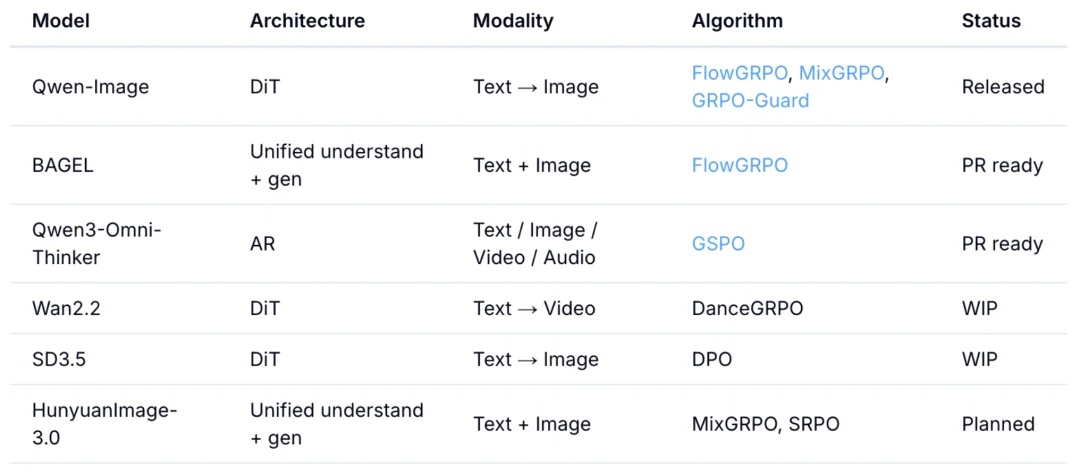
详见安装文档:
https://verl-omni.readthedocs.io/en/latest/start/install.html
examples 目录(https://github.com/verl-project/verl-omni/tree/main/examples)提供了不同 RL 算法 trainer 的启动脚本,覆盖图像 / 音频 / 视频理解与生成任务。训练性能与结果可以通过 wandb 跟踪。
在 flowgrpo 示例中,团队用 OCR 奖励任务训练 Qwen-Image。奖励模型采用 Qwen3-VL-8B-Instruct,通过读取生成图像里的渲染文字、与数据集 ground truth 比对,对生成图像评分。
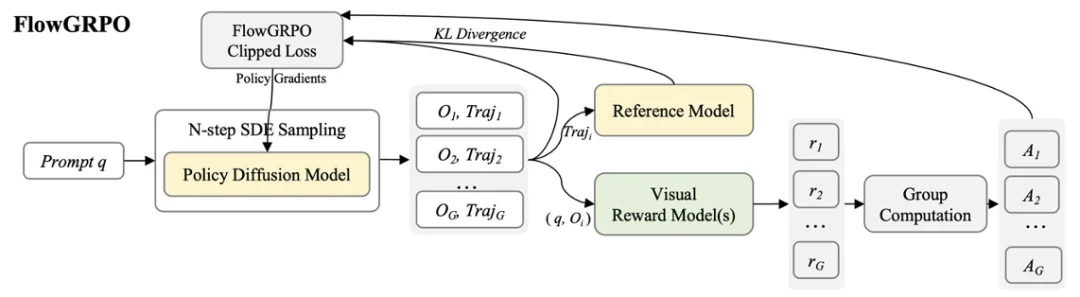
FlowGRPO 算法示意
FlowGRPO 示意
FlowGRPO 是面向 flow-matching 模型的在线策略方法。它通过 diffusion policy 模型做多步 SDE 采样以实现高效 RL 探索,并采用基于模型的奖励评估生成质量。
训练流程主要分四步:
LoRA 微调
NVIDIA H800 GPU 上的训练吞吐如下:
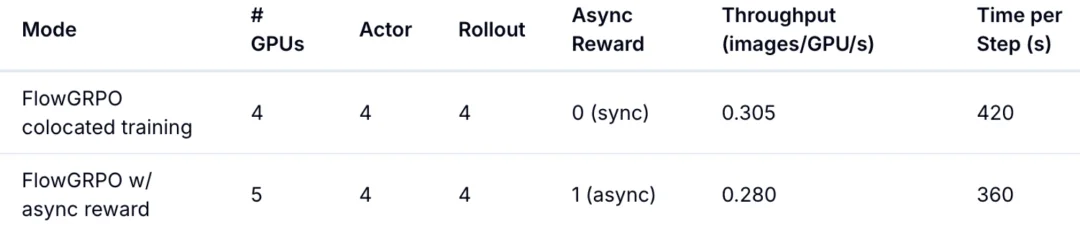
把奖励模型放到独立 GPU 上,与策略训练 overlap,每步 wall-clock 时间降低约 14%。
全模型微调
团队还验证了 non-CFG 全模型 Qwen-Image OCR 训练,在 4×NVIDIA H200 上达到 0.510 images/GPU/s,每步约 250 s。
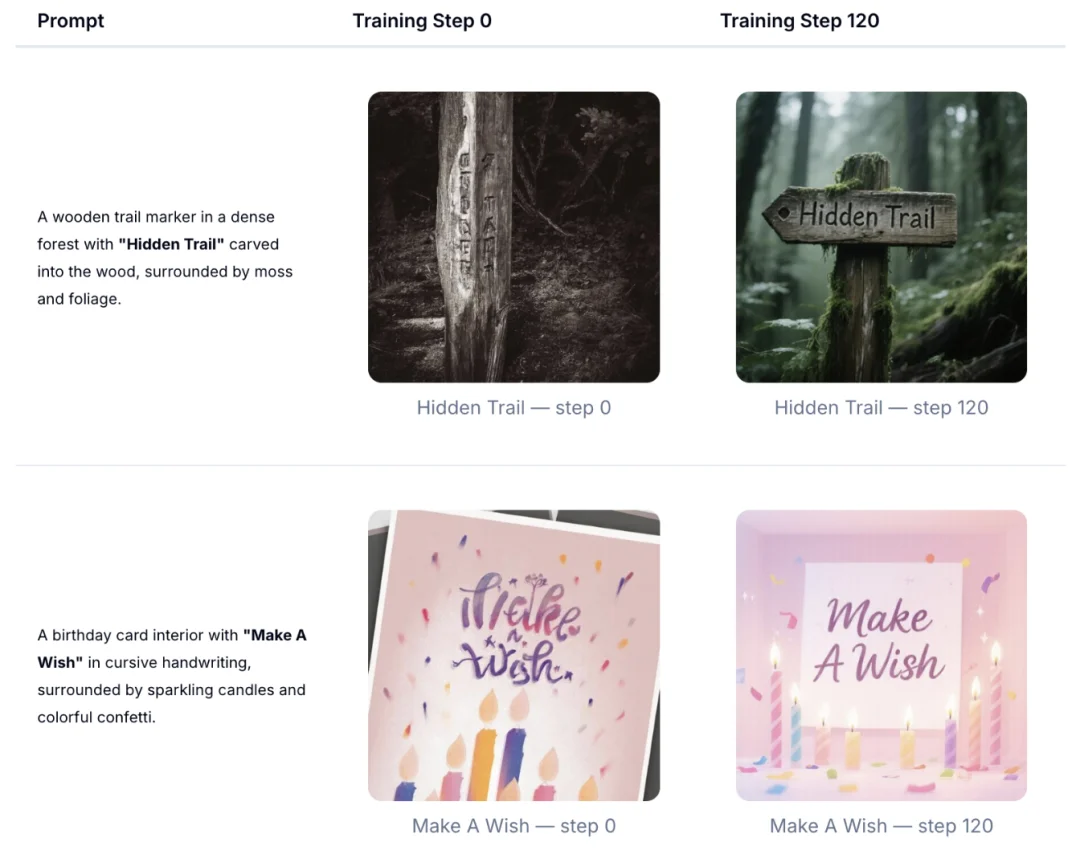
下面可以看到,仅 120 步训练后,生成图像的文字渲染质量已有显著提升。
下面是参考训练曲线,critic reward 与 validation reward 都收敛稳定。
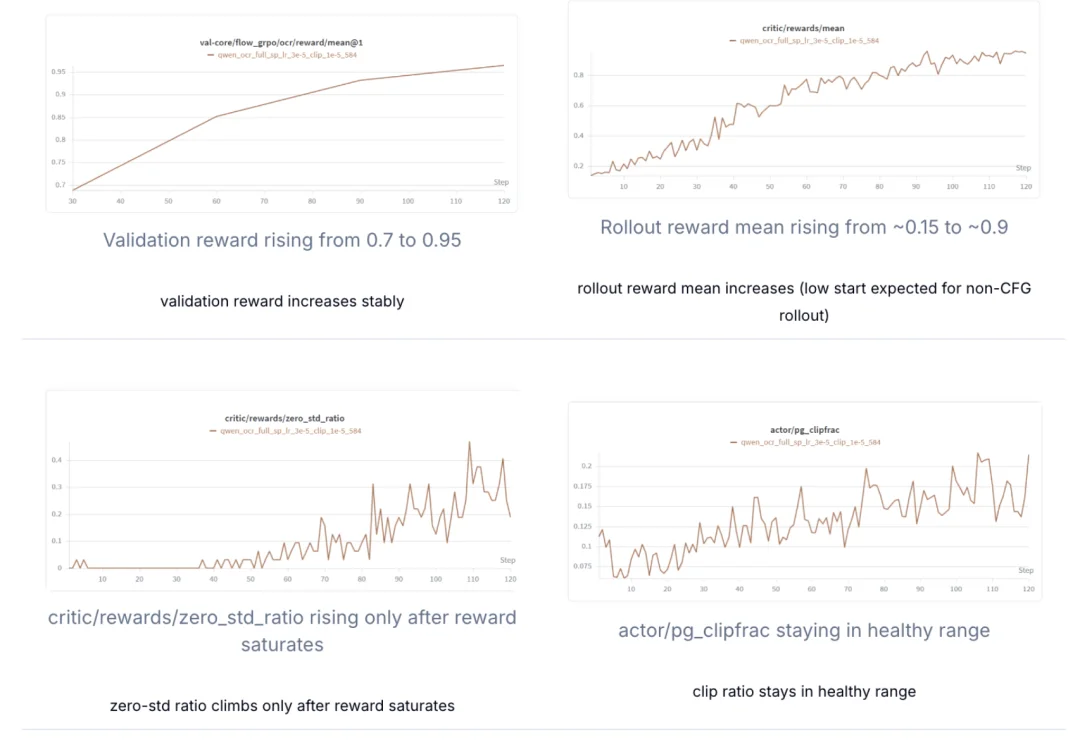
完整训练指标说明见 Training Metrics 文档。
VeRL-Omni 仍处于活跃迭代的预发布阶段,扩散 RL 核心栈已经稳定。路线图聚焦在扩展模型 / 算法支持,并继续推进高效多模态 RL 训练的边界。
扩散和全模态 RL 后训练只是个开始。VeRL-Omni 团队正在持续支持更多架构与算法,欢迎一起塑造未来。
文章来自于"机器之心",作者 "机器之心"。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
