# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当下视频生成模型正在快速逼近真实世界的画面质感,但一个现实瓶颈也越来越突出——
那就是分辨率越高,生成所需要的时间就越长。
此外如果为了提速强行压缩步骤、降低计算量,又很容易破坏模型原本的生成风格与运动逻辑。
所以如何在推理速度与生成质量之间找到平衡,成为高清视频生成走向实用的关键。
当前,来自香港大学与快手可灵团队的研究者提出了一个新的高分辨率视频生成加速框架——SURF。

△SURF在保留基础模型生成特征的同时,实现720p与1080p高分辨率视频生成。
它要解决的问题,不只是让模型跑得快。
而是既要快,也要像原来的那个强模型。
让视频在高速推理的同时,尽可能保留基础模型原本的signature:语义、运动、构图和整体生成布局。
这下,高清视频生成也能 「又快又稳」了~
过去,视频生成加速常见的思路,大多是减少去噪步数、稀疏化注意力计算,或者训练一个蒸馏后的快模型。
这些方法确实能缩短时间,但副作用也很明显。
主体动作可能变僵,肢体结构可能跑偏,语义一致性下降,颜色和纹理上还可能出现奇怪伪影。最后的结果就是:视频出得更快了,但看起来也更不像原来的强模型了。
SURF的出发点很直接:视频生成慢,核心受两件事影响——分辨率和去噪步数。
与其让模型在整个生成过程中都用同一种尺度硬算,不如顺着去噪过程本身的规律,把不同阶段交给最适合的分辨率和模型来完成。
研究者将这个流程概括为:OptimRes→LowRes→HighRes
具体来说,就是先在基础模型最擅长的分辨率上确定全局内容,再切换到低分辨率快速完成预览,最后用轻量级 Refiner 把预览提升到目标高清结果。

△AI生成
这样一来SURF既能借到强大预训练模型的“脑子”,又不用在每一步都付出高分辨率推理的昂贵成本。
具体来看,SURF把整个视频生成任务拆成了两个阶段。
第一个阶段是预览阶段。
基础视频生成模型先负责决定视频的整体内容、布局、语义和运动。SURF会让模型在早期关键去噪步骤中,仍然运行在它最擅长的分辨率上。
因为这些步骤决定了视频最终“会长成什么样”,等到整体结构、主体关系和运动方向基本稳定后,SURF再将latent 下采样到低分辨率,在保留全局结构的前提下,快速完成预览。
第二个阶段是精修阶段。
一个约1B参数的轻量级Refiner会接过低分辨率预览,用更少的去噪步骤补充细节、修正伪影,并生成目标高分辨率视频。
通过学习低清预览与高清目标之间的生成式映射,可以把这个流程理解成一套更高效的创作分工:
这套分工的关键在于,SURF没有粗暴替换原模型,而是把原模型最有价值的生成先验保留下来,再把昂贵计算集中用在真正需要的地方。
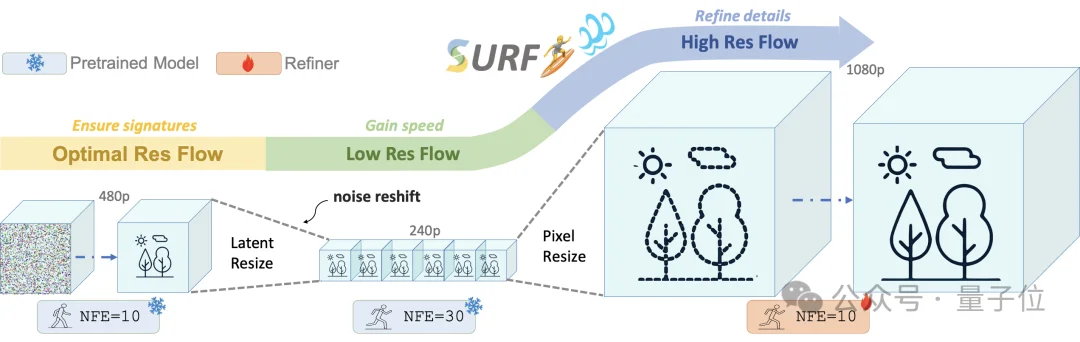
△SURF整体流程:最优分辨率保留signature,低分辨率预览提速,高分辨率Refiner补足细节
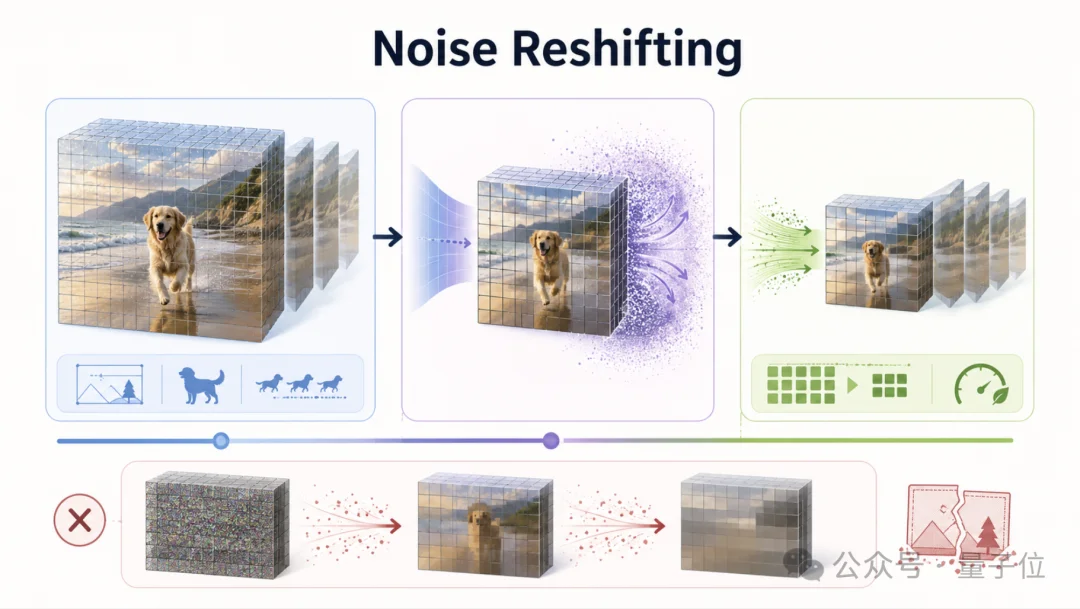
SURF的第一个关键技术,是Noise Reshifting。
直接让一个在高分辨率上训练好的模型跑低分辨率,听起来很省计算,但实际很容易翻车。
原因在于,每个预训练模型都有自己的“舒适区”,通常接近它的训练分辨率,一旦分辨率不匹配,模型原本学到的布局、语义和运动先验,就可能被破坏。
SURF提出的Noise Reshifting,正是为了解决这个问题——
它会先让模型在最优分辨率上完成早期去噪,让视频主体内容和整体结构先稳定下来。
到达转折步k后,系统再估计干净latent,将其下采样到低分辨率,并重新注入与当前时间步匹配的噪声,让后续去噪过程在低分辨率上继续推进。
这样一来,SURF既避免了一开始就低分辨率推理造成的先验损失,又能在后半段大幅减少token数和计算量。
 △AI生成
△AI生成
论文中的消融实验也显示,转折步的选择非常关键。
切换太早,会影响布局和运动质量;切换太晚,加速收益又会下降。实验中,10-30步区间在质量与速度之间取得了更好的平衡。
第二个关键技术,是轻量级Refiner。低分辨率预览解决了“快”和“像原模型”的问题,但最终输出还需要高清细节。
为此,SURF训练了一个轻量级Refiner,它从线性上采样后的预览latent出发,学习低分辨率latent到高分辨率latent 的flow mapping,只需少量去噪步骤,就能补足高清纹理。
为了让Refiner在长视频和大分辨率下依然高效,研究者在模型结构上强调局部时序建模与跨帧信息连接。
也就是说,精修阶段既要补纹理,也要维持动作连贯性。
训练上,SURF使用了10万组低清-高清视频帧对,并结合像素级和latent级退化,让Refiner学会处理模糊、结构缺失和细节不足等问题。
它的目标也很明确:把一个可快速预览的低清结果,变成真正可用的高清成片。

△从预览到完整方法,SURF在运动连贯性、纹理细节和结构修正上带来明显提升
SURF最直观的优势,就是速度。
在Wan2.1 14B上,生成一段5秒、16fps、720p视频时,SURF将推理时间从约58分钟压缩到278秒,实现约12.58倍加速,同时PFLOPs从658.5降至34.3。
在HunyuanVideo上,SURF也取得了约8.7倍加速;而在1080p设置下,相比直接运行Wan 2.1,速度提升达到约43倍。
这意味着,高分辨率视频生成终于开始从“漫长等待”,走向更接近真实创作流程的效率。
另一个优势,是保留基础模型的signature。
很多加速方法的代价,是结果逐渐不像原来的强模型,主体可能变得僵硬,颜色出现噪点,肢体和物理关系也可能变得不合理。
SURF的思路则是保留基础模型早期去噪阶段的全局决策,让生成视频在布局、语义和运动上尽量接近原模型,再通过Refiner补齐高清细节。
 △AI生成
△AI生成
这也带来了一种更实用的交互方式,用户可以先快速生成多个低分辨率预览,挑选满意的构图和运动,再进入高清精修。
此外在实验部分,论文也从效率、质量、人类偏好、模型兼容性和消融实验等多个角度验证SURF——
在720p Wan 2.1评测中,SURF在Quality Score、Aesthetic Quality、Dynamic Degree、Motion Smoothness、Overall Consistency等指标上,保持了与原始Wan 2.1相近,甚至部分更优的表现,同时实现了约12.58倍加速。
在1080p生成相关比较中,SURF在DINO、LAION、DOVER等指标上也取得了较强表现,并且推理时间显著低于多种扩散式视频增强方法。
更重要的是,SURF还具备插件式兼容能力。
它可以接入不同基础模型和加速方法,比如与HunyuanVideo结合时达到8.7倍加速,与AccVideo结合时也能进一步带来1.3倍提速。
这也说明了SURF并非只服务于单一模型的小技巧,更像是一种通用的高分辨率视频生成加速范式。
当视频模型迈向更长时序、更高分辨率和更复杂场景时,如何保留强模型的signature,同时把计算成本降下来,将成为越来越关键的问题。
在这点上,SURF给出的答案很清晰——
不要让模型从头到尾都背着同样重的负担,而要让每个阶段做最擅长的事。
先用强模型定方向,再用低分辨率快速试错,最后用轻量级Refiner做高清收尾。
这或许也是高分辨率视频生成真正走向可用的一条重要路径。
参考链接:
[1]Project Page: https://kxding.github.io/project/SURF/
[2]Github: https://github.com/kxding/SURF
[3]arXiv: https://arxiv.org/abs/2603.21002
文章来自于"量子位",作者 "香港大学&快手可灵团队"。



