# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

编辑 | ScienceAI
深度学习模型因其能够从大量数据中学习潜在关系的能力而「彻底改变了科学研究领域」。然而,纯粹依赖数据驱动的模型逐渐暴露出其局限性,如过度依赖数据、泛化能力受限以及与物理现实的一致性问题。
例如,美国OpenAI公司开发的文本到视频模型Sora因深刻理解事物在现实中的存在方式而受赞誉,被视为AI领域的飞跃。尽管能利用大量视觉数据生成逼真图像和视频,Sora却被认为未掌握物理定律,如重力和玻璃破碎等。
面对这一问题,将人类知识融入深度学习模型是一个潜在的解决方案。将先验知识与数据一起使用,能够提升模型的泛化能力,从而创建能够理解物理规律的「知情机器学习」(Informed machine learning)模型
。
然而,目前对深度学习中知识的价值仍缺乏深入理解,确定哪些先验知识(包括函数关系、等式和逻辑关系等)能有效地融入模型以进行「预学习」,已成为一项亟待解决的难题。同时,盲目地整合多项规则可能会引发模型的崩溃。这种局限性制约了对数据与知识关系的进一步探索。
针对这一问题,东方理工(EIT)和北京大学的研究团队提出了「规则重要性」的概念,并开发了一套框架,能精确计算每个规则对模型预测精度的贡献。该框架不仅揭示了数据和知识之间的复杂相互作用关系,为知识嵌入提供了理论性指导,还有助于在训练过程中平衡知识和数据的影响。此外,该方法还可用于识别不恰当的先验规则,为交叉学科领域的研究与应用提供广阔前景。
该研究以「Worth of Prior Knowledge for Enhancing Deep Learning」为题,于 2024 年 3 月 8 日发表在 Cell 出版社旗下交叉学科期刊《Nexus》上,并被 Cell Press 团队在 AAAS(美国科学促进会)和 EurekAlert!进行报道。

在教授孩子拼图时,既可以让他们通过反复试验来找出答案,也可以用一些基本的规则和技巧来引导他们。同样地,将规则和技巧——比如物理定律——融入到人工智能训练中能让它们更贴近现实,运作更高效。然而,如何评估这些规则在人工智能中的价值,一直是困扰研究者的难题。
鉴于先验知识的丰富多样性,将先验知识融入深度学习模型是一个复杂的多目标优化任务。研究团队创新性地提出了一个框架,以量化不同先验知识在提高深度学习模型方面的作用。他们将此过程视为充满合作与竞争的博弈,通过评估规则对模型预测的边际贡献来界定其重要性。首先生成所有可能的规则组合(即「联盟」),并对每个组合构建模型,并计算均方误差。
为降低计算成本,他们采用了一种基于扰动的高效算法:先训练一个完全基于数据的神经网络作为基线模型,然后逐一加入各个规则组合进行额外训练,最后在测试数据上评估模型表现。通过比较模型在包含和不包含某个规则的所有联盟中的表现,可以计算出该规则的边际贡献,进而得出其重要性。
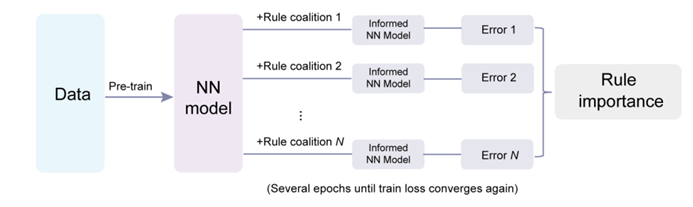
图示:规则重要性的计算流程(来源:论文)通过流体力学的算例,研究人员探讨了数据与规则间的复杂关系。他们发现,在不同任务中,数据和先验规则的作用完全不同。当测试数据与训练数据分布相近时(即 In-distribution),数据量的增加会削弱规则的作用。
然而,当测试数据与训练数据分布相似度较低时(即 Out-of-distribution),全局规则的重要性被凸显出来,而局部规则的影响则被削弱。这两类规则的区别在于:全局规则(如控制方程)影响整个域,而局部规则(如边界条件)仅作用于特定区域。
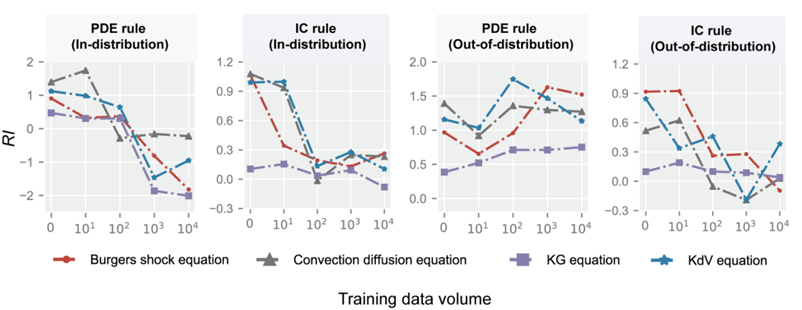
图示:规则重要性与数据量之间的关系(来源:论文)研究团队经数值实验发现,在知识嵌入中,规则间存在三种相互作用效应:依赖效应、协同效应和替代效应。
依赖效应指某些规则需依赖其他规则才能有效;协同效应表明多条规则共同作用的效果超越各自独立作用时的总和;替代效应则显示一条规则的功能可能被数据或其他规则替代。
这三种效应同时存在,并受到数据量的影响。通过计算规则重要性,可清晰展示这些效应,为知识嵌入提供重要指导。
在应用层面,研究团队试图解决知识嵌入过程中的一个核心问题:如何平衡数据与规则的作用,以提升嵌入效率并筛选出不适宜的先验知识。在模型的训练过程中,该团队提出了一种动态调整规则权重的策略。
具体而言,随着训练迭代步的增加,逐渐增大正重要性规则的权重,同时减小负重要性规则的权重。这种策略能够根据优化过程的需求,实时调整模型对不同规则的关注度,从而实现更加高效和准确的知识嵌入。
此外,向 AI 模型传授物理定律可以使它们「更加贴近现实世界,从而在科学和工程领域发挥更大作用」。因此,该框架在工程、物理和化学领域具有广泛的实际应用。研究人员不仅优化了机器学习模型来求解多元方程,还准确识别出对薄层色谱分析预测模型性能有提升效果的规则。
实验结果显示,通过融入这些有效规则,模型的性能得到了显著提升,测试数据集上的均方误差从 0.052 降低至 0.036(减少了 30.8%)。这意味着该框架可以将经验性见解转化为结构化知识,从而显著提升模型性能。
总体而言,准确评估知识的价值有助于构建更契合现实的AI模型,提高安全性和可靠性,对深度学习发展具有重要意义。

图示:通过规则重要性以识别有效的规则(来源:论文)
接下来,研究团队计划将他们的框架开发成可供人工智能开发人员使用的插件工具。他们的最终目标是开发出能够直接从数据中提取知识和规则,进而自我完善的模型,从而打造一个从知识发现到知识嵌入的闭环系统,使模型成为真正的人工智能科学家。
论文链接:https://www.cell.com/nexus/fulltext/S2950-1601(24)00001-9
AAAS 报道链接:https://www.eurekalert.org/news-releases/1036117
本文来源于 机器之心 作者 机器之心



