# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2012 年,AlexNet 在 ImageNet 竞赛上以压倒性的优势拿下第一,正式开启深度学习时代。此后十余年,ImageNet 成为计算机视觉研究的「标准考场」:无论是 VGG、ResNet,还是 ViT,研究者们都在这同一张卷子上比拼,看谁的模型精度更高。
但这张卷子,如今已经没有评分的意义了。
今年,一批顶尖论文相继宣告:它们在 ImageNet 上的生成质量评分(FID),已经低于真实图片本身的评分。也就是说,生成的假图片,在统计上比真图片「更像真图片」。卷子刷穿了,分数失真了,这个沿用十年的基准彻底饱和。
基准饱和意味着什么?简单来说:你不再能通过分数判断一个生成模型是真的好,还是在「投机取巧」地优化指标。科学竞争,需要一把新的尺子。
就在前两天,斯坦福大学等机构发布了一个名为 GPIC(Giant Permissive Image Corpus,巨型开放图像语料库)的数据集。

项目共一作者 Keshigeyan Chandrasegaran 的推文
该项目由李飞飞团队主导构建,核心贡献者为 Keshigeyan Chandrasegaran 和 Kyle Sargen,包含整整 1 亿对图像-文本数据,总计约 28 万亿像素,并已全量托管在 Hugging Face 上,任何人都可以免费下载使用。

旧规则失灵了
要理解 GPIC 为什么重要,先要理解当前的视觉生成研究面临哪些困境。研究者们在使用已有数据集时,遭遇了三个相互叠加的麻烦。
第一个麻烦:旧基准 ImageNet 已经对不上现实。
今天的图像生成模型,训练用的是数亿张带有自然语言描述的图片,生成时也靠文字提示词驱动。而 ImageNet 是一个以「分类标签」为核心的数据集,它对应的是另一个时代的研究范式。拿一张用文字提示生成的图片,去和一个以标签分类为目标设计的数据集做比较,本质上是「用语文考卷评数学成绩」。
第二个麻烦:大多数工业级数据集不对外开放。
Stable Diffusion、Midjourney、Sora 这些一线产品背后,训练数据要么是商业机密,要么涉及版权纠纷,从未公开。学术界要复现、比较、改进这些模型,几乎无从下手。
第三个麻烦:即使有开放数据集,也不稳定。
目前学界常用的开放数据集(如 LAION、DataComp),普遍采用「URL 索引」的方式分发——也就是说,研究者下载到的,其实是一份图片网址清单,还得自己去抓取原始图片。随着时间推移,大量链接失效,不同研究团队最终用到的「同一个数据集」其实已经大相径庭,实验结果自然无法可靠比较。
GPIC 的设计,正是针对这三重失灵逐一作答。

来自 ImageNet 作者的接班人之作
构建 GPIC 的团队,来自斯坦福大学,包括李飞飞、吴佳俊以及他们的多位学生。
李飞飞是「ImageNet 时代」的缔造者之一。2009 年,她主导发布了第一版 ImageNet,后来由此衍生出 ILSVRC 视觉识别挑战赛,催生了 AlexNet 等一系列里程碑式工作,被广泛认为是深度学习革命的重要推手之一;她也因此还被《时代》杂志和 BBC 等许多媒体称为是 AI 的教母(Godmother of AI)。
图源:Time 官网
她如今是斯坦福人工智能实验室(SAIL)的联合主任,同时也是 3D 空间智能公司 World Labs 的创始人。
这一次,她带领团队打造的是视觉生成时代的「新 ImageNet」。
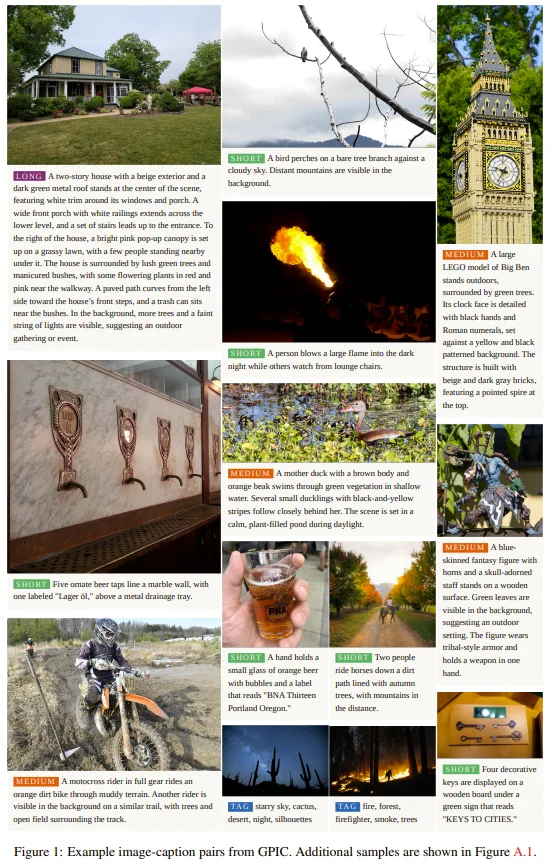
GPIC 是什么,怎么做出来的
GPIC 的构建,经过了四个严格的流程阶段。
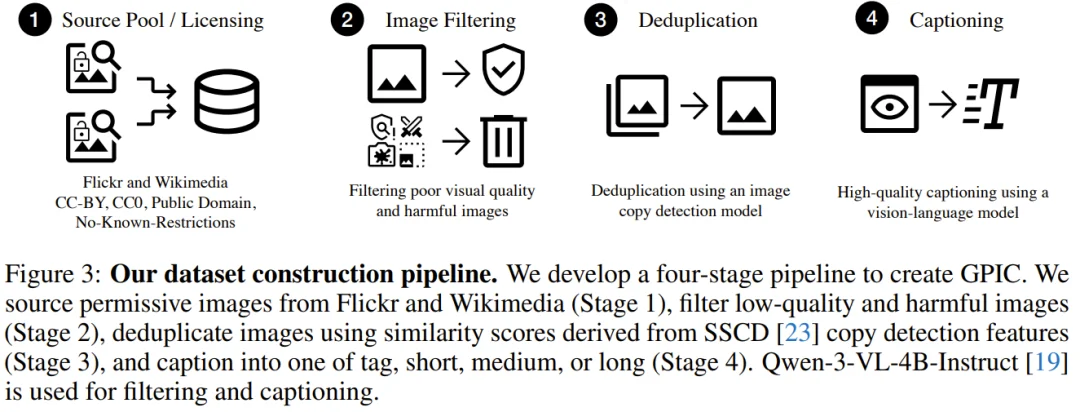
第一步:只采集有授权的图片。
研究团队仅从 Flickr 和 Wikimedia 两个平台收集图片,并严格限定在 CC BY、CC0、公有领域和无已知限制这四类授权范围内。这意味着 GPIC 里的每一张图片,都有明确的法律依据,既可用于学术研究,也可用于商业产品开发,无需担心版权风险。初始收集到的图片约 1.1 亿张,其中 87.7% 来自 Flickr,12.3% 来自 Wikimedia。
第二步:过滤低质量与有害内容。

研究团队借助视觉语言模型 Qwen3-VL-4B,自动识别并移除分辨率过低、严重模糊、过曝、近乎空白,以及被判定为不安全的图片。这两类过滤分别淘汰了约 0.3% 和 0.35% 的图片——比例看起来很小,但在亿级规模下,这意味着筛掉了数十万张问题图片。
第三步:去重。

互联网图片有大量的「重复」现象,包括同一场景的连拍、被转发的表情包、略有不同的翻版图。研究团队使用了一种名为 SSCD 的图片复制检测模型,计算每两张图片之间的特征相似度,并通过「保守去重」策略删除高置信度重复项。最终,约 101.3 万张图片留下,其中不含任何完全相同的副本。
第四步:生成高质量描述文字。
传统图片数据集的文字描述(如 alt text)质量往往很差,充斥着「photo.jpg」「未命名」之类无意义的标注。GPIC 则对每一张图片,都用 Qwen3-VL-4B 重新生成了高质量的人工智能描述,且描述按照「标签」「短」「中」「长」四种粒度分布。生成 1 亿张图片的描述,共消耗约 1500 个 H100 GPU·小时。
最终的 GPIC,包含 1 亿张训练图片、20 万张验证图片和 100 万张测试图片,总体积约 12.9 TB,整理成 8000 个分片(shard),可以直接流式传输用于大规模分布式训练。
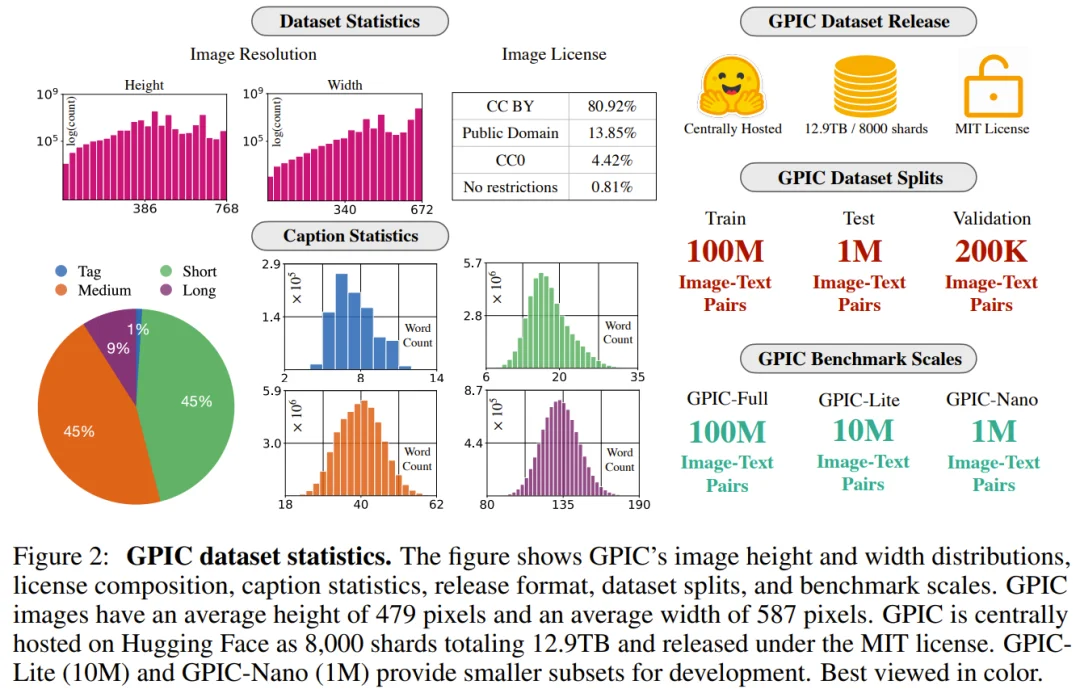
FD-DINOv2
数据集之外,GPIC 还附带了一套新的评估协议,这同样是此次发布的重要贡献。
旧的评估指标 FID(Fréchet Inception Distance)依赖一个 2015 年的图像分类网络 Inception-v3 来提取图片特征。这个网络从未为「评估生成质量」而设计,它的特征空间和人类对图像质量的感知存在明显的脱节,导致 FID 评分容易被「刷榜」——模型可以在不真正提升感知质量的情况下降低 FID 数值。
GPIC 的新基准采用 FD-DINOv2 作为主要指标。
DINOv2 是 Meta 于 2023 年发布的自监督视觉特征模型,其特征表示与人类对图像相似性的判断更为一致。
研究者们验证发现:目前所有主流生成模型(包括那些用了 DINOv2 特征训练的模型),在 FD-DINOv2 上的分数仍然高于真实图片,说明这把尺子还有足够的「余量」,不会很快被刷穿。

更重要的一点改进是:GPIC 的基准评分是与一个 独立的百万张测试集 进行比较,而不是和训练集比较。这个设计避免了一个严重的漏洞——如果拿生成图片和训练集比较,模型只需「记住」训练数据就能获得好分数,而无法反映真正的泛化能力。
给未来的研究者:参考基线
为了方便后来者对齐实验结果,研究团队还在 GPIC-Full(1 亿张训练集)上训练了一个参考基线模型。
这个基线使用了 JiT(Just image Transformers)流匹配架构,搭配 1.1B 参数的 Transformer 骨干网络,以 256×256 分辨率在单节点 8 张 H100 上训练约 40 小时(约一个 epoch)。最终,在最优的引导强度(CFG=6.25)下,基线模型的 FD-DINOv2 评分为 76.25。这个数字并不出色,但它的价值在于:所有研究者都可以以此为起点,公平地比较各自的改进效果。
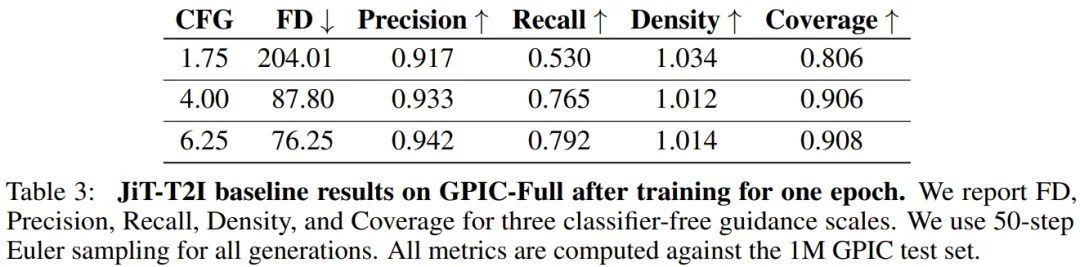

研究团队还提供了三个不同规模的训练集版本:GPIC-Nano(100 万张)、GPIC-Lite(1000 万张)和 GPIC-Full(1 亿张),方便资源有限的团队在小规模上迭代,有足够算力的团队再在完整数据集上验证。
一个开放基础设施的意义
视觉生成领域正在经历一场「军备竞赛」。Sora、Imagen、Stable Diffusion 3……前沿模型的能力每隔几个月就会跃升一级。但这场竞赛,在相当程度上是不透明的:每个实验室都在自己的数据上训练,用自己的指标评估,发布时只挑选对自己有利的数字汇报。
公开、可复现的基准,是科学进步的基础。学界在 NLP 领域已经为此付出了多年努力,逐步建立起了 GLUE、SuperGLUE、BIG-bench 等相对标准化的评测体系。视觉生成,迟迟缺少这样的基础。
GPIC 的发布是一次为这个领域补课的尝试,是为了让整个领域有一个共同的起跑线。正如李飞飞团队在论文中所写的:「我们希望 GPIC 能够推动视觉生成建模领域公开、可及、可复现的研究。」
文章来自于微信公众号 "机器之心",作者 "机器之心"


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
