# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
按这个趋势,今天的大模型已经能够一口气读完整套《哈利・波特》,未来甚至可能直接分析整个大型代码仓库。
但数字背后也隐藏着一个关键问题:上下文越长,模型就越「记不住」。
这并非模型不够聪明,而是 Transformer 架构本身的工程约束。当模型处理长文本时,需要为每个 token 保存 Key-Value(KV)状态,用于后续生成时的注意力计算。这个缓存区域被称为 KV Cache。
KV Cache 的大小会随上下文长度线性增长:输入越长,占用的 GPU 显存越多,推理速度也越慢。对于百万 token 级别的输入,在大型模型和高精度推理场景下,KV Cache 的内存开销可达到数十到数百 GB,远超单张顶级 GPU 的显存容量。
上下文窗口的竞赛,本质上是一场显存的战争。
面对这一困境,研究者们已经开发出多种「事后压缩」方案,也就是在模型训练完成之后,用各种算法对 KV 缓存进行精简。这些方法确实有效,但它们都遗漏了一个更根本的问题:如果模型在最初学习的时候,就没有被引导去生成「容易被压缩」的内部表示,那么后期无论怎么压缩,效果都将受到天花板限制。
就在这一背景下,来自牛津大学、以色列理工学院、AITHYRA 和英伟达的联合研究团队提出了一个新的思路:与其事后弥补,不如训练时就让模型主动学会「压缩友好」的记忆方式。

他们将这套方法命名为 KV-CAT(KV 压缩感知型训练,KV-Compression Aware Training)。

要理解这项研究的价值,先得弄清楚一个直觉上看似奇怪的事实:两个输出完全相同的模型,其 KV 缓存可能一个极易压缩,另一个根本无法压缩。
这听起来很反直觉。我们通常认为,如果两个系统的「结果」相同,它们的内部过程应该没有本质区别。但在神经网络世界里并非如此。
研究团队用一个简单的例子来说明这一点:「词频统计」。给模型输入一段文字,让它统计每个字母出现了多少次。这是一个只依赖「汇总信息」的任务,与每个字母出现的顺序无关。
同样完成这个任务,可以有两种截然不同的内部实现方式。
第一种是「自然而然」的实现:模型对每个 token 进行独立编码,最后通过注意力机制对全部 token 做平均,得出统计结果。这种方法简单直接,但存在一个致命缺陷:任何对 KV 缓存的压缩都会打破平均计算,导致最终结果出错。研究团队从数学上证明了:这种实现方式,在理论上对任何程度的压缩都不具备容错能力。
第二种是「结构化」的实现:模型在处理每个 token 时,额外记录序列的位置信息(即这段前缀有多长),当 KV 缓存被压缩成一个单一的向量时,模型可以利用位置信息对压缩后的汇总值进行重新校准,从而恢复正确的统计结果。这种实现方式,理论上可以将任意长度的前缀压缩到仅剩一对 KV 向量,同时保持零误差。
两种实现,相同的输出,截然不同的压缩性。
关键在于:标准的模型训练过程,完全没有激励让模型去选择第二种更结构化的实现。因为在没有压缩的场景下,两种方式效果完全一样,训练信号无从区分。
认识到这一点后,研究团队设计了 KV-CAT 训练方案。核心思路极为直接:如果你想让模型学会在 KV 缓存被压缩的情况下正常工作,就在训练时模拟这种压缩压力。
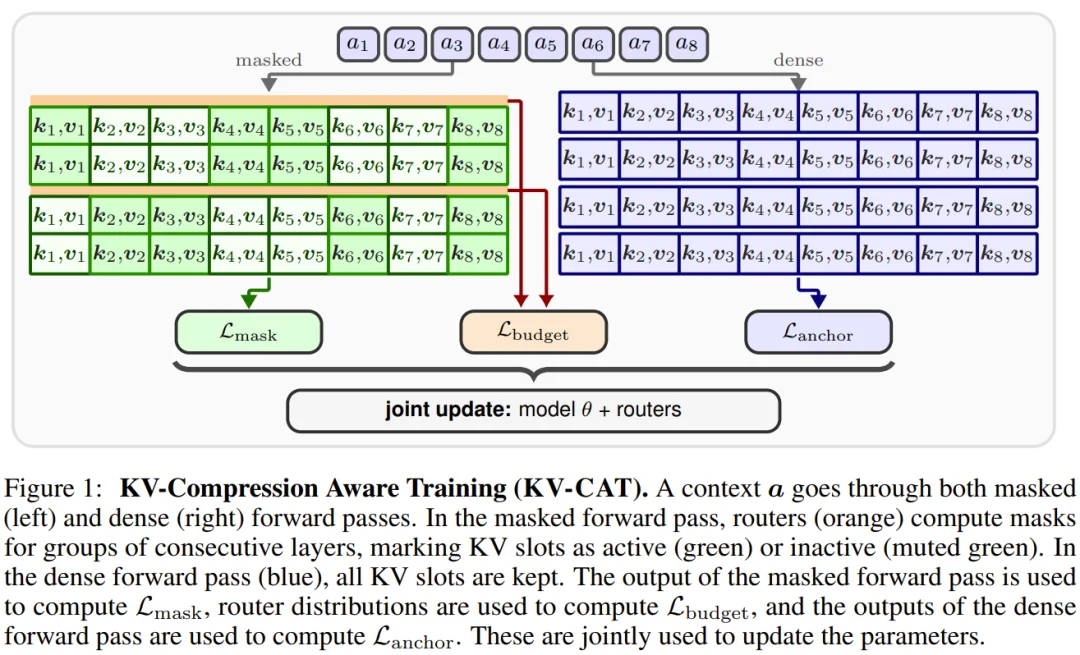
这类似于一种「记忆障碍训练」。普通的模型训练就像让学生在考试时可以带着完整的笔记本作答 —— 当然表现优异。而 KV-CAT 则是在训练时就没收大部分笔记,逼着学生将最重要的信息内化成真正的「理解」,而非对笔记的依赖。
具体来说,KV-CAT 在原有的预训练模型基础上,引入了一组轻量级的「路由器」模块。这些路由器在训练的每一步会动态判断哪些 KV 槽位是必要的、哪些可以被屏蔽,目标是保留约 50% 的 KV 缓存。每次前向传播,模型需要同时进行两次计算:一次是正常的「全量」计算(所有 KV 槽位都可见),一次是「压缩」计算(仅保留路由器选中的 KV 槽位)。
训练目标由三部分组成:
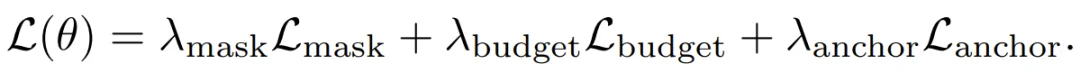
整个流程完成后,路由器模块在推理时会被关闭。输出的是一个标准的 Transformer 模型,它的参数与原模型相同,但其内部已经被训练成一种「天然压缩友好」的表示形式。后续可以搭配任意现成的 KV 压缩方法使用。
详细的数学描述请访问原论文。
研究团队将 KV-CAT 应用于 Qwen2.5 的两个规模版本(0.5B 和 1.5B 参数),并在多个维度上对其进行评估。
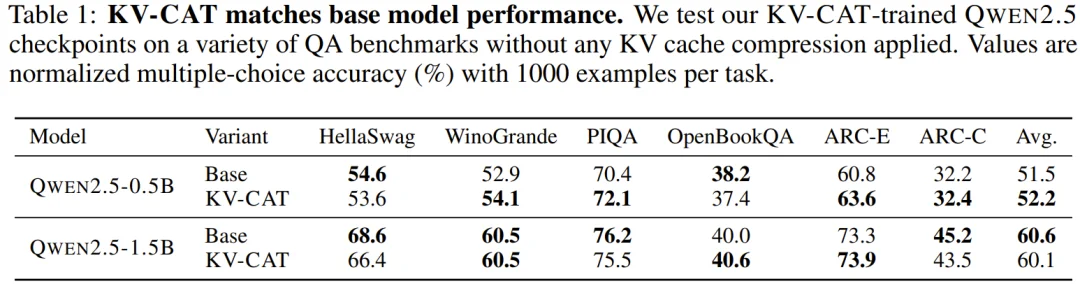
首先,基础能力没有损失。 这是最关键的验证。在六个标准多选题基准测试上(包括 HellaSwag、WinoGrande、ARC 等),KV-CAT 训练后的模型与原始模型几乎持平:0.5B 版本平均提升了 0.7 个百分点,1.5B 版本平均下降了 0.5 个百分点,均属于正常的训练波动范围。这说明 KV-CAT 没有以牺牲通用能力为代价换取压缩性能。
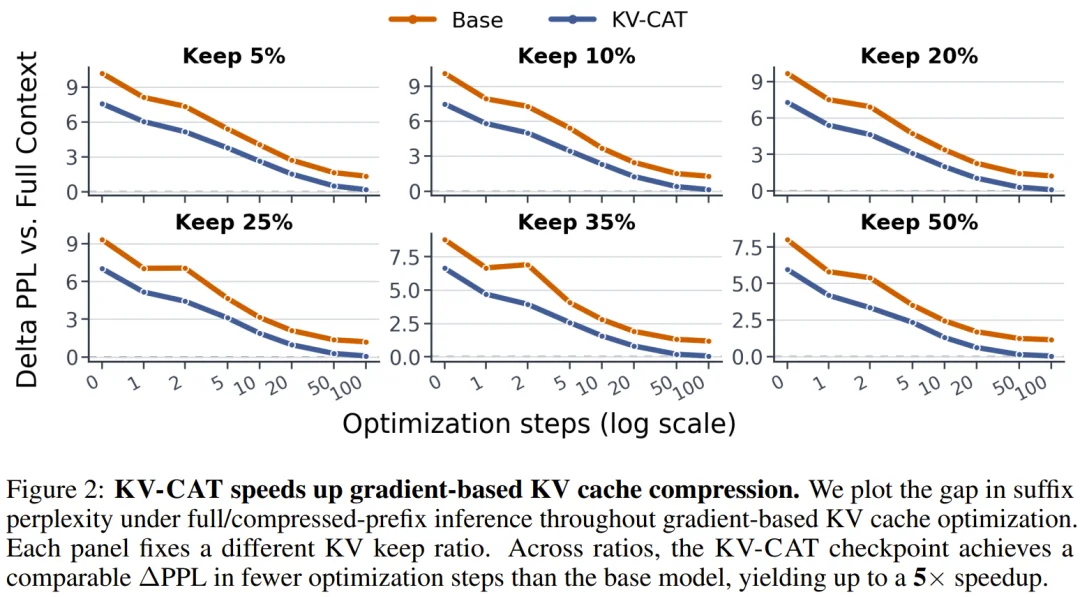
其次,后期 KV 压缩的效果大幅改善。 在同等压缩预算下,与原始基础模型相比:
第三,「大海捞针」检索准确率显著提升。 研究团队设计了一个经典的长文检索测试:在一段充满干扰项的长文本(约 1024 个 token)中藏入一个六位数的「密码」,然后将文本的 KV 缓存压缩后,测试模型能否正确回忆出这个密码。
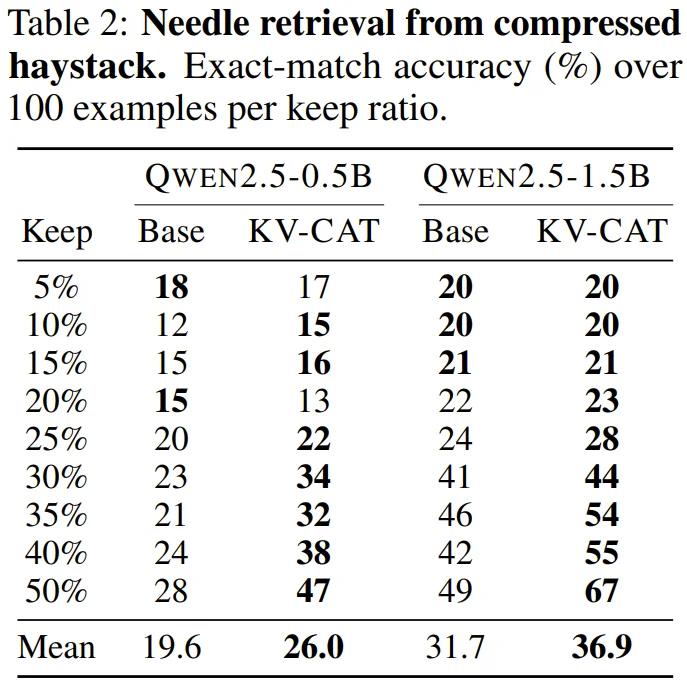
在保留 50% 的 KV 槽位的情况下,KV-CAT 版本的 Qwen2.5-0.5B 检索准确率从 28% 跃升至 47%,Qwen2.5-1.5B 则从 49% 提升至 67%,提升幅度接近 68%。即使在极端压缩(仅保留 10% 的 KV)的情况下,KV-CAT 版本的性能也与基础模型在轻度压缩时相当。
第四,长文问答任务也有明显改善。 在 LongBench v2 的七项长文本问答任务上,KV-CAT 模型在各压缩比例下的平均准确率均高于基础模型,最大提升幅度达到 39%。
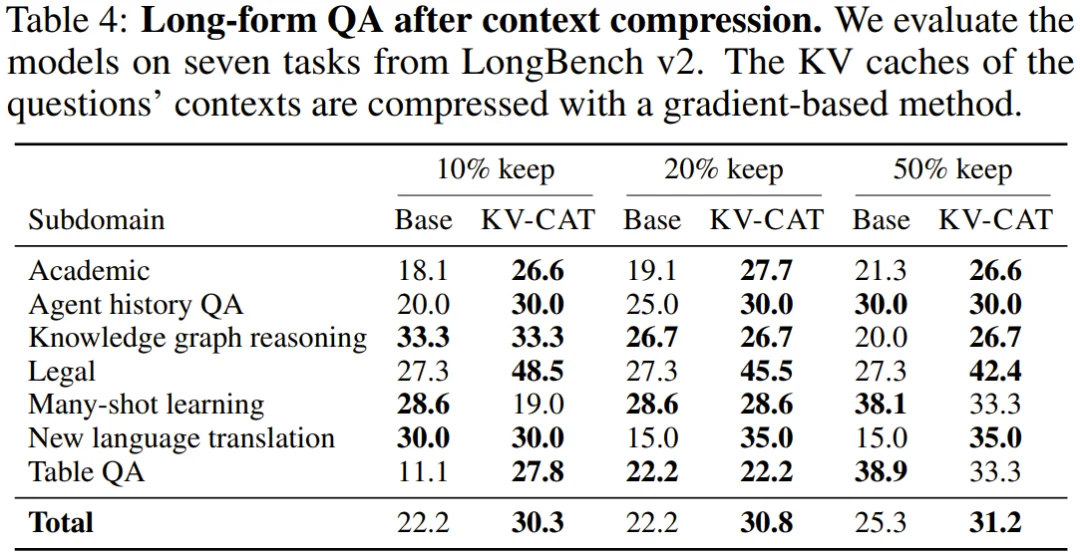
KV-CAT 并不声称要取代现有的压缩算法。研究团队明确指出,它的目标是成为现有压缩方法的「底层增强」:同样的压缩算法,作用在 KV-CAT 训练过的模型上,效果更好、速度更快。
这种「训练时为推理做准备」的思路,在 AI 系统工程领域并不陌生。但将其具体应用于 KV 缓存的可压缩性,并从理论上证明这种属性完全由模型的学习表示决定,是这项工作的核心贡献。
当然,这套方案也有其代价:继续预训练引入了额外的训练开销,路由器模块增加了实现复杂度,目前的实验规模也仅限于 0.5B 和 1.5B 两个相对小型的模型。研究者坦承,这套方法能否平滑扩展到百亿甚至千亿参数的大模型,仍是一个开放问题。
但这一方向的逻辑是成立的。随着上下文窗口的竞赛不断推进,显存瓶颈正升级为制约 AI 系统规模化部署的核心挑战。让模型从一开始就「学会压缩」,而不是生成了难以压缩的表示之后再亡羊补牢,将是未来大模型训练工程中越来越值得重视的设计维度。
文章来自于"机器之心",作者 "机器之心"。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
