# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

AI视频巨头混战升级:这次,长视频“变脸魔咒”要被打破了。
AI视频赛道,突然杀出了一匹意料之外的黑马。
智东西6月5日报道,京东首次开源长音视频生成框架JoyAI-Echo。它直击长视频生成中的角色一致性、声音稳定性和生成速度三大核心难题,一举在多个核心指标上超越行业标杆模型。
▲JoyAI-Echo在Hugging Face的页面截图
根据公开评测结果,JoyAI-Echo在跨镜头一致性、语音准确率、用户偏好等关键指标上均取得领先表现,与业内主流长视频生成模型相比优势明显,出道即跻身全球第一梯队。
2026年的AI视频赛道,竞争已进入白热化阶段。OpenAI的Sora在3月官宣关停,给行业留出空间,各路玩家正围绕多镜头叙事、物理模拟、4K画质等维度激烈角逐。
就在这个关键节点,强势入局的京东一上来就瞄准了行业难啃的硬骨头——分钟级长视频的连贯生成,无疑为行业再添一把火。
AI视频的“开盲盒”时代,真的要结束了。
GitHub地址:
https://github.com/jd-opensource/JoyAI-Echo
Hugging Face地址:
https://huggingface.co/jdopensource/JoyAI-Echo
项目主页:
https://echo-team-joy-future-academy-jd.github.io/Echo-LongVideo-Page/
出道即冲进第一梯队:
JoyAI-Echo有多强?
京东此次开源的JoyAI-Echo,到底有多强?
我们可以先看一组硬核数据。
研究团队构建了一个极为严苛的评测集:100个独立故事剧本,总计3000个分镜,每个故事平均30个镜头,涵盖原创角色与IP角色、动画与真人实拍等多种复杂场景。
在这样的“统考”中,JoyAI-Echo在跨镜头一致性、角色人脸+人体一致性、人声音色一致性、美学画质、成像清晰度、文本一致性等指标上全面领跑。
尤其值得关注的是语音准确率,飙升至0.8646,达到行业领先水平,这意味着以往AI视频中“口型对不上、台词胡编”的痛点被大幅缓解。
在用户盲测中,JoyAI-Echo的音频质量偏好高达81.7%,提示词遵循偏好达到80.6%,视觉美学偏好63.6%,IP角色一致性偏好59.4%,各项指标均获得用户高度认可。
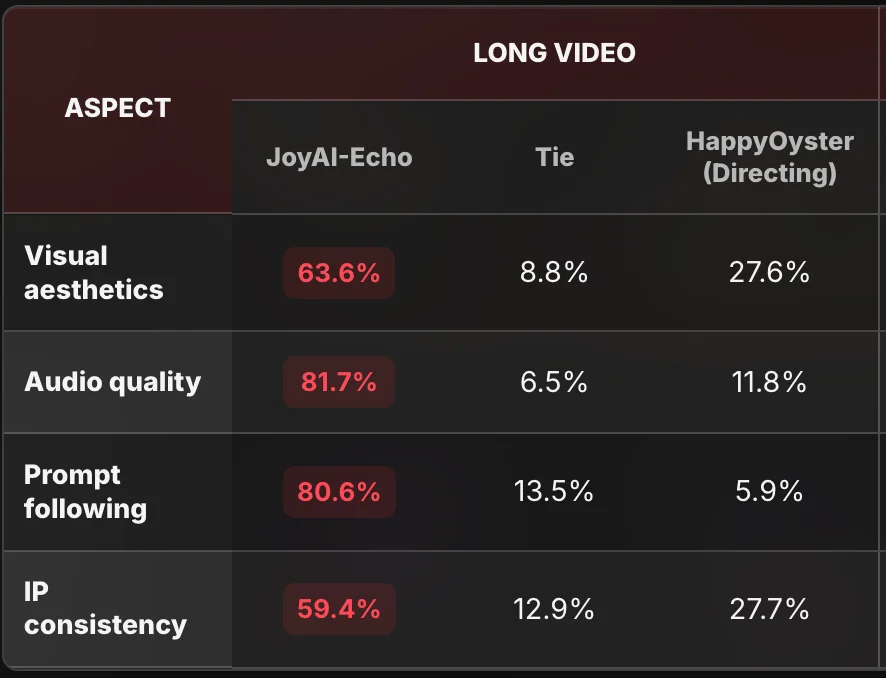
▲JoyAI-Echo的盲测优于同行标杆
技术参数之外,更让人印象深刻的是JoyAI-Echo的生成案例。
在京东官方展示的《居家一日》案例中,长达近5分钟的叙事里,男主角的外貌特征、面部细节、说话音色始终保持稳定,观众不会产生“这是另一个人”的出戏感。

▲JoyAI-Echo生成的视频
另一个案例《极限拉力》则展现了高速运动场景下的稳定性。赛车飞驰时,赛道环境、车身涂装等细节没有出现扭曲或闪烁。在多角色、多道具的复杂叙事场景中,JoyAI-Echo也能保持角色长相、服装、道具和环境的持续稳定。

▲JoyAI-Echo生成的视频
再看看巫师城堡、仓库对峙等复杂叙事场景,在这些多角色、多道具、多环境的长镜头序列中,JoyAI-Echo生成视频没有出现“换装”“变脸”“道具丢失”等常见问题。

▲JoyAI-Echo生成的视频
这些案例有力证明,JoyAI-Echo是一个能够驾驭复杂叙事、理解物理世界、真正具备生产能力的创作工具。
注:文中生成样片仅用于技术成果研究展示,相关角色、场景素材版权归属原权利人。
长视频为什么难?
四项创新破解行业“不可能三角”
为什么长视频生成如此之难?核心在于一个“不可能三角”:长时长、高一致性、快速度,三者似乎总是无法兼得。
当视频拉长到分钟级,误差会像滚雪球一样累积。同一个角色,上一个镜头和下一个镜头长得不一样;说话人的音色忽高忽低,甚至突然变声。渲染速度慢如蜗牛,等几分钟才能出结果;修改成本高,哪怕只改一点点也要从头到尾重新生成整个视频。
这些问题都导致AI长视频长期停留在“玩具”阶段,很难真正投入生产使用。
JoyAI-Echo用四项实打实的技术创新,逐一击破这些痛点。
1、角色总变脸:跨模态音视频记忆库
行业长期难以解决“上一镜头和下一镜头不是同一个人”的问题。根本原因在于,传统模型在逐镜生成时,缺乏对历史生成内容的显式记忆机制,每次生成都像“失忆”一样重新开始。
JoyAI-Echo的破局之道是“跨模态音视频记忆库”。框架内置了一个专门的记忆库,能够持续保存并精准调用角色的视觉特征和听觉特征。在长达5分钟的多镜头生成中,这个记忆库就像导演手中的“角色档案”,每次调用都能保证输出的一致性,从而解决了“同一个人演着演变成另一个人”的尴尬。
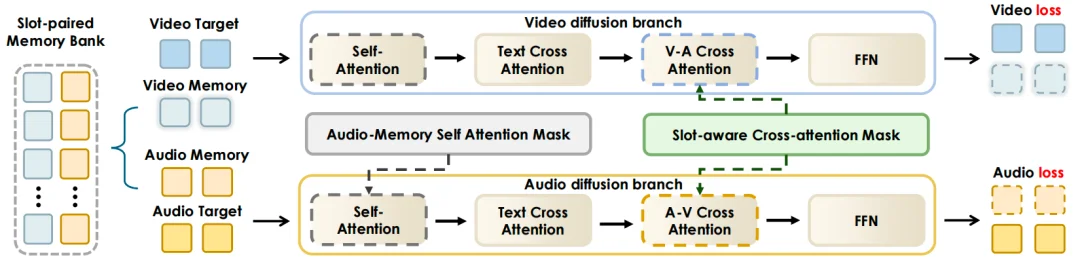
▲JoyAI-Echo跨模态音视频记忆库机制
2、生成太慢:记忆驱动后训练,速度提升7.5倍
长视频生成往往意味着巨大的推理成本。JoyAI-Echo创新性地设计了三段式后训练流水线:基于记忆的有监督微调(SFT)→ 跨模态人类反馈强化学习(RLHF)→ 基于记忆的分布匹配蒸馏(DMD)。
其中DMD技术尤为关键,它像一个高效的“知识压缩器”,让轻量级的“学生模型”学习原复杂“教师模型”的生成路径。最终,这项技术将多步扩散师生蒸馏压缩为8步快速推理模型,为JoyAI-Echo带来了约7.5倍的推理速度提升,从而让长视频生成从“等半天”变成“秒出片”。
3、修改成本高:Director Agent导演智能体
传统视频模型工作流为输入提示词,一次性出结果,让创作者陷入“抽卡”困境。如果生成不满意只能重来,修改一个镜头就要重跑整条视频。
JoyAI-Echo引入Director Agent导演智能体,这也是最令人惊喜的交互功能。你可以用自然语言告诉它你的需求,比如“把第三场戏的咖啡馆背景换成图书馆”。它会自动理解并执行:拆解需求形成剧本和分镜,调用模型生成视频,检查生成结果。它只重新生成有问题的局部镜头,整条视频不用重来。
该智能体将长视频生成划分为规划、生成、评审三个阶段。智能体管控两类记忆:固定记忆从角色参考图/参考音频/开篇镜头提取,全片锁定人物外貌音色基准;动态记忆根据剧情语义筛选关联历史镜头,避免无关素材干扰。修改后的内容存入历史库,后续镜头自动读取新版画面特征,保障剧情连贯。
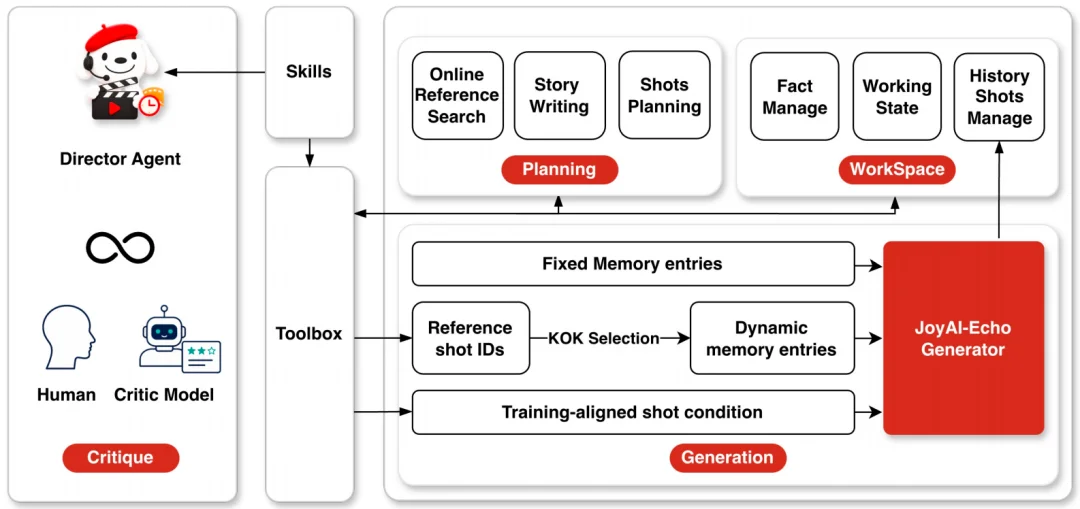
▲导演智能体工作流程概述
4、高清输出难:轻量化实时超分
原生720p生成视频时序连贯但细节不足。为了满足专业生产需求,JoyAI-Echo配套了一个专门的实时超分模块,在几乎不增加延迟的情况下,将原生720p的视频实时提升至最高1472×2560的高清分辨率。
该模块基于87.6万条1080P~4K高质量音视频片段训练,通过DMD蒸馏得到单步极速学生模型,在流式生成的延迟约束下兼顾画面清晰度。
总的来说,JoyAI-Echo首次一站式同时实现远距离跨模态一致性、分钟级视频实时生成、对话式交互编辑、高清画质输出四大能力,四项性能互不妥协,开创交互式视频生成全新范式。
AI视频进入长视频时代:
哪些行业将率先受益?
长视频生成的重要意义,并不只是让视频变得更长,还让AI首次具备了持续叙事能力。
但当角色、场景、对白需要跨越几十个镜头持续存在时,生成难度会指数级上升。一旦角色一致性、音色稳定性和生成效率问题得到改善,长视频生成的应用空间将迅速打开。
以JoyAI-Echo为代表的长视频生成模型框架,至少有望为以下五大应用场景带来新的可能性:
1、虚拟动漫与故事创作:创作者可以像导演一样,用自然语言指挥AI生成连贯的动漫剧集或绘本视频,角色形象和声音全程统一,无需逐帧手绘。
2、数字人直播与短剧生产:数字人主播可以在长达数分钟的直播或短剧中保持音色、口型、表情的高度一致,大幅提升观众沉浸感。
3、品牌营销内容快速迭代:营销团队只需修改台词或局部镜头,即可生成多条不同版本的品牌故事视频,实现秒级改片、分钟级上新。
4、影视前期预演与分镜制作:导演可以用JoyAI-Echo快速生成分镜预览视频,提前验证镜头语言和叙事节奏,大幅降低实拍试错成本。
5、互动教育课件与游戏剧情动画:教育机构和游戏开发者可以动态生成连贯的剧情动画,根据用户的选择实时调整后续内容,实现个性化叙事。
更重要的是,京东选择将代码与模型权重全部开源。
全球开发者都可以基于JoyAI-Echo进行二次开发、微调和研究,推动长视频生成从单一模型竞争走向产业生态竞争。中小团队和个人创作者可以直接使用这一世界级水平的模型,AI视频创作的“平民化”时代或将真正到来。
从京东的这次开源动作来看,落点不只是技术榜单的排名,更是未来AI内容生产基础设施的话语权。谁能成为全球开发者手里最顺手的视频生产工具,谁就有望占据未来智能化数字内容生态网络的主导地位。
结语:开源即格局
打开视频生成新局面
JoyAI-Echo的开源发布,不仅标志着京东在长视频生成领域进入全球第一梯队,更用实打实的技术手段为长视频生成的“不可能三角”交出了一份极具工程参考价值的答卷。
当AI长视频不再受制于换脸、失音和漫长的渲染等待,当创作者可以像和导演聊天一样,用自然语言随时微调、重绘局部分镜,高一致性、高画质、可交互的“长视频时代”便不再遥不可及。
目前,JoyAI-Echo的项目主页与GitHub仓库均已正式向全球开发者敞开大门。这场视频生成范式革命,才刚刚拉开序幕。
文章来自于微信公众号 "智东西",作者 "智东西"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
