# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

文生图的"慢思考",到底有没有用?
“8B 开源版是一扇窗,真正的风景还在 200B+ 参数的 Pro 版本之后。”
智象未来 HiDream-O1-Image 开源版(8B)发布之后,我在测评最后留下了这样一句判断。前者以 Peanut 匿名登上 AA 榜、拿下文生图开源模型全球第一的事迹犹在眼前,今天 1.5 闭源版本又和公众见面了。
珠玉在前,HiDream-O1-Image-1.5 可以说是备受瞩目,而智象未来的官方口径很大程度上回应了这种期待:“连续登顶不仅印证了智象未来在图像生成大模型上的硬核实力,更标志着公司已稳居全球视觉生成大模型的第一梯队”。
看过 1.5 版本在 Artificial Analysis 榜单上的成绩,你就知道这不是一句空话。已跃升至文生图模型排名的第3位,超越了Google的Nano Banana 2,仅次于OpenAI的两款模型。它与排名第二的GPT-Image 1.5综合评分差距仅有1分,展现了强劲的竞争力。
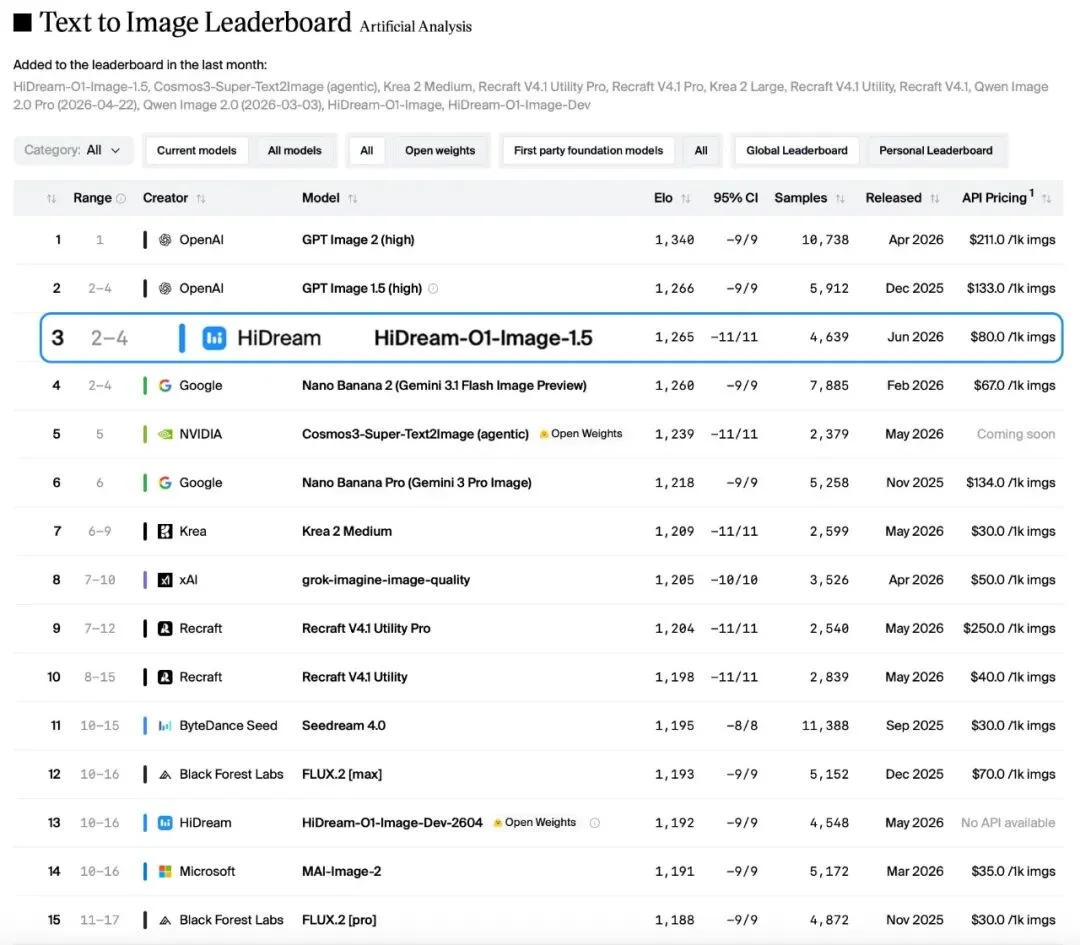
此前在 HiDream-O1-Image 上初露锋芒的 UiT 架构,也在新版本中继续大放异彩。
但今天我们不聊榜单,1.5 版本提出了两个更值得关心的问题是,一个图像模型到底需不需要“先想再画”?以及砍掉 VAE 这件事到底改变了文生图的什么底层逻辑?
Google Nano Banana 曾经是文生图赛道最有存在感的选手,不碰一下,实在不好意思给自己加冕新王。
HiDream-O1-Image-1.5 的单独展示已经没什么意义,我这次把它和 Nana Banana 2 放在了同一条起跑线上,用完全相同的 prompt 做三组盲测。
为了不让评价变成“我觉得好看”这种没法对焦的废话,我把图像模型能力拆成了八个维度:
▪ Prompt 遵循度:能否准确执行文字指令要求
▪ 构图能力:镜头组织和视觉重心
▪ 摄影语言理解:景深、焦点、镜头参数等概念
▪ 材质表现:如光影、反射、纹理等
▪ 细节准确性:文字、结构、生物解剖等硬指标
▪ 氛围塑造:情绪与环境营造
▪ 主体设计能力:自由发挥情况下,主体表现力的高级程度
▪ 以及商业完成度:能不能直接用
测试结束后我拿到了六份生成结果,但我隐去了它们分别出自谁手。你可以在阅读过程中先猜猜,看看判断和真相是否一致。
第一组测试是生成一张白酒产品图。
Prompt:一张高端中国白酒的奢华电商海报。正中央矗立着一个纯净半透明的羊脂玉瓷瓶。在瓶身的曲面上直接浮雕着一首八句中文古诗——崔颢的《黄鹤楼》。雕刻的文字内部镶嵌着精致闪烁的金箔。酒瓶放置在一块粗糙的黑板岩上,半浸在清澈见底的浅水池中,水面荡漾着柔和的同心涟漪。焦散光影在瓶底跳跃。背景有微型盆景松树和薄雾。边缘轮廓光,商业产品摄影。

1.1
1.1 的第一印象很惊艳,这就是奢侈品广告的画风,玉瓷材质的光泽和水面效果也很到位,让人觉得下一帧就要切到觥筹交错的商务宴请上。
但文生图模型最怕细看,如果你盯着瓶身上的文字,问题就出来了。古诗严重错误是最明显的,浮雕的层次感也模糊成一片。它在视觉创造力和材质表现上几乎满分,但细节准确性实在不够看。而细节恰恰是这组 prompt 关注的重点。好看、写字精确,1.1 在第一条上做到了极致,但在第二条上几乎放弃了。

1.2
与之相对,1.2 在复杂中文文字渲染上的优势就更加突出。你可以看到《黄鹤楼》的全诗被比较完整地呈现,文字排列也更接近真实产品包装上的竖排中文视觉效果,最直观的感受就是更可读、内容关系更明显。
诗词全文的呈现,或许是一种相对少见的需求,但它本质上是产品广告图这类场景对信息准确性的压力测试。相比 1.1 中文字出现的明显错乱、重复、错字和语义断裂,1.2 的稳定呈现已经跨越了落地的鸿沟,在此之上才有讨论视觉效果的空间。在这一维度上,1.2 同样不令人失望,玉瓷瓶体、浮雕文字、金色装饰、瓶身高光的塑造都审美在线。
第二组测试是生成一张小猫在花园里的照片。提示词用英文写成,原文及翻译如下:
prompt:An adorable, candid photograph of a curious kitten exploring lush green gardens, with oversized flowers and foliage creating a whimsical fairy-tale atmosphere.
翻译:一张可爱而自然抓拍的照片:一只充满好奇心的小猫正在郁郁葱葱的绿色花园中探索,周围硕大而繁盛的花朵与枝叶营造出梦幻般的童话仙境氛围。

2.1
2.1 在这组里的表现很有趣。它完美还原了 oversized flowers 的视觉冲击,对花朵巨大、色彩饱和、童话氛围这些画面元素的把握,都无师自通。此外光影处理也很棒,阳光穿过叶片的方式有真实摄影感。
要说有什么问题,就是小猫和环境没什么交互,不要说玩弄花草,它甚至不像在看路,眼神踏实得像在自己窝里。另外,作为主体的小猫在画面里也相对偏小,视觉中心容易被大叶片和花丛分散,存在感稍弱一些。

2.2
2.2 的主体辨识度就强上许多,生成的小猫眼神、姿态和身体结构清晰,“curious kitten”的好奇感跃然其上。此外小猫面部焦点明确,五官、毛发、四肢关系也更自然,保留了真实动物摄影的质感。
整体构图上,2.2 在画面右侧同时保留了放大的花朵、蘑菇、绿色植物等童话元素,但没有让环境压过主体。这种对主体清晰和氛围营造进行取舍之后得到的平衡,也是一大亮点。
第三组测试,我打算设计点展现模型创造力的。科幻题材是个不错的选择,我让两款模型分别生成了一个赛博格接受审讯的画面。
prompt:在一个灯光昏暗、烟雾弥漫的审讯室里,一张过肩镜头(OTS)电影剧照。前景左侧三分之一是侦探肩膀和侧脸的严重失焦剪影。焦点锁定在背景中坐在金属桌对面的嫌疑人——一个疲惫的赛博格,拥有发光的红色光学植入物,被头顶摇晃的刺眼聚光灯照亮。极浅的景深在模糊前景和锐利的嫌疑人面部之间形成强烈光学分离。85mm 镜头,f/1.4 大光圈。

3.1
3.1 在这组的表现最均衡。OTS 镜头角度标准,前景虚化到位,景深控制准确,摄影语言理解上这已经时满分的水平。同样值得一提的是审讯室的氛围感和灯光效果也能看出是经过设计的,在物理准确性之外,也很好地发挥了叙事功能。你能看出这是一个审讯场景,知道谁是权力方。

3.2
3.2 的表现也难分伯仲。前景人物虚化形成压迫感,焦点集中在嫌疑人身上,画面叙事关系清晰,同样一个 OTS 镜头拍出了电影级的质感。
值得注意的是,Prompt 明确要求 85mm、f/1.4、大光圈、极浅景深。3.2 的输出更明显地体现了前景虚化和背景主体清晰的光学分离,这说明模型不仅识别关键词,还能把镜头参数转化为画面效果。
这对于影视分镜、广告片预演、概念视觉生成非常关键。
另一个亮点是主体设计。此前 3.1 的赛博格设计偏保守,机械细节不够丰富,只是象征性地在人体上加了几处发光物。而 3.2 中的赛博格则有着更丰富的机械细节、更具质感的光学植入物。这种对主体的强调和突出似乎和上一个任务中的小猫一脉相承,模型能够理解画面的重点、叙事的中心在哪里。
那么回到本节开头的问题,作者是谁?
此前每组的第一张是 Nano Banana 2,第二张则是 HiDream-O1-Image-1.5 的作品。
到此为止,两款模型的能力画像都变得逐渐清晰。
在开放审美任务中,二者都已达到很高水准。但当评测标准从主观好看转向准确、稳定、可交付,HiDream 的优势会更清晰。
Nano Banana 2 像一个艺术家,懂摄影语言,构图能力在线,偶尔还能主动发挥一下创意,这些能力共同塑造了其作品中恰到好处的氛围感。
但缺点也在捉摸不定的创意上,它给人一种“意译”而非直译 prompt 的感觉,文字类任务的准确率并不稳定。给出一个需求,它会按自己的审美给你一套方案。未必 100% 按描述来的意思是,用抽卡成本交换潜在的惊喜。
而 HiDream-O1-Image-1.5 则是一个工程师,文字理解准确、细节执行严格、物体真实感高。你说什么,它就做什么,交付物绝不出错。
不过这种能力取向的不同,并没有在两款模型之间造成碾压式的差距。在标准 Benchmark 下,两者总体水平其实非常接近。HiDream-O1-Image-1.5 和 Nano Banana 2 的对比做到最后,我体感上不像在测试模型,更像是在测试选型。
上面三组盲测反映出的一个核心差异,是模型对于 prompt 的理解深度。从白酒广告的中文古诗,猫猫花园对“curious kitten”的独特理解,到赛博格审讯室对“一个疲惫的赛博格”的语言约束,1.5的响应更真实,更细节。
这背后是HiDream-O1-Image-1.5 所采用的 “先推理、后生成”机制。该机制基于 Gemma 4 的 Reasoning-Driven Prompt Agent模块,嵌入在生成管线内部,在用户按下生成按钮后、扩散模型开始工作前,先跑一轮思维链。
这跟 ChatGPT 的 system prompt 有本质区别。ChatGPT 的推理层在纯文本空间跑,优化的是“回答的逻辑一致性”。而 1.5 的 Prompt Agent 做的是从语义到空间的翻译。
如果你做过需要同时控制主体、环境、情绪和构图的复杂生图任务,就能直观感受到这个 Agent 在解决什么痛点。直白地说,以前你需要靠反复调 prompt 撞运气的任务,现在 HiDream-O1-Image-1.5 在生成之前就会先帮你把画面逻辑理清楚。
赛博格审讯室那组对比最能说明问题。“OTS + 浅景深 + 85mm f/1.4 + 赛博格 + 聚光灯”,这么多高信息密度的指令如果一股脑塞进传统文本编码器,编码器不会自动为这五个约束分配权重,很可能出现的情况是它会过度关注“赛博格”而忽略“OTS镜头”,或者过度渲染聚光灯效果而丢掉“浅景深”的质感。
但 HiDream-O1-Image-1.5 的 Agent 在推理阶段就把这五个约束分开处理了。镜头语言是 OTS、光学参数是 85mm f/1.4、氛围是聚光灯照明、主体是赛博格,各管各的,最后汇总。
当然,这里有一个重要的前提条件。CoT Agent 解决的是指令理解问题,而非常识储备。如果 prompt 没提供足够信息让 Agent 推理,它仍然不会凭空生成正确逻辑。如果你只说“水往低处流”,它仍然无法渲染复杂的流体变化,Agent 推理能力的边界,就是你 prompt 的信息边界。
CoT 解决了“理解”,但还有一个更底层的改动,解释了为什么 HiDream-O1-Image-1.5 的长文本渲染能达到 CVTG-2K 的 0.978,超越 GPT Image 2 的 0.961,以及为什么白酒产品图任务中只有 1.2 把崔颢的《黄鹤楼》从笔画到结构完整还原了出来。
在 HiDream-O1-Image之前,几乎所有主流文生图模型都是拼盘式的:VAE 压缩图像,T5/CLIP 理解文本,DiT 负责生成。
VAE 的工作方式是把一张 1024×1024 的图编码到一个小得多的潜空间(latent space),比如压缩 8 倍,在潜空间跑扩散,最后解码回原尺寸。这样做的好处很明显,计算量骤降,64×64 潜空间的扩散比 1024×1024 像素空间快不止一个数量级。
但压缩必然丢信息。而 VAE 丢掉的,恰好是文生图场景下最不能丢的两类。
第一类是高频细节。 VAE 在频域上倾向保留低频结构(物体轮廓、色块分布),压缩高频纹理(边缘锐度、细线、毛发)。这就是 SD 生成的图放大看经常有“涂抹感”的原因,问题都没跑到生成环节,因为在解码阶段高频信息就已经被丢了。
第二类是文字,这是更致命的。文字在图像里是一种极其脆弱的信号,它的辨识依赖精确的笔画边界和方向。“一”和“丨”只差 90 度的旋转,“士”和“土”只差几个像素的偏移。VAE 压缩对这类信号近乎灾难,压缩到重建的过程中,笔画端点模糊、拐角圆化、间距偏移几乎是肯定的。在这里文字“缺胳膊少腿”不是修辞,是 VAE 压缩的必然副作用。

HiDream 的 UiT(像素级统一 Transformer)架构直接砍掉了 VAE。所有信息——像素、文本 token、控制条件——映射到同一个 token 空间。没有了“压缩-重建”这个环节,文字信号从 prompt 到像素全程在一个空间内流转。
回到三组盲测。白酒产品图最能体现无 VAE 的价值。
1.2 的画面在玉瓷材质的光泽感、焦散光影的锐度、金箔镶嵌的纹理细节上都表现出极高的还原度。1.1 的构图更大胆,但在材质锐度和细节密度上明显不如 1.2,部分原因就在于竞品使用的 VAE 压缩削平了一些高频细节,让画面少了那层真实物料的质感。
古诗文字渲染则是更直接的证据。1.1 的古诗完全写错,并不是因为它不知道怎么布局,而是 VAE 压缩把中文字符的关键笔画特征破坏后,扩散过程只能“脑补”出近似文字的纹理,而非可辨识的字体。HiDream-1.5 砍掉了 VAE,文字信号从 prompt 到像素全程在同一个 token 空间流转,这也是 1.2 能把黄鹤楼全诗完整写出来的根本原因。
在中文场景下,这个问题被进一步放大。英文单词靠轮廓也能猜出大概,像是“ca_e”和“cake”,但中文单字完全依赖笔画完整性。上次测 8B 时频繁出现的“伪汉语”就是这么来的。
HiDream-1.5 的长文本渲染数据,揭示了一个相当底层的洞察,那就是想要稳定输出可读文字,目前解法只有两条,要么堆参数量补偿 VAE 损耗(FLUX 的 56B 路线),要么直接砍掉 VAE。
HiDream 选了后者,8B 开源版已经做到了比肩 56B 的渲染效果,1.5 在此基础上继续推高上限。而且此前 8B 开源版的性价比确实离谱,在 GenEval、DPG、HPSv3 等多个榜单上,8B 不仅秒杀同量级的 SD3.5 Large,还越级逆袭了参数量大得多的 Qwen-Image(27B)和 FLUX.2 [Dev](56B)。本来以为是小模型里的尖子生,结果是直接在跟大两个数量级的选手对打,还打赢了。
对想本地部署或者算力有限的团队,开源 8B 是更务实的选择。消费级显卡就能跑,出图质量不输那些大好几倍的模型。闭源的 HiDream-1.5 则适合对生成效果有更高要求的商业场景。两条路都摆出来了,按需取用。
到这里可以回答一个更内核的问题,为什么 CoT 推理和无 VAE 架构必须一起出现?
分开看,每个都有局限。
CoT 推理层能拆复杂指令、生成空间约束,但如果没有不打折扣的传递通道,这些约束在 VAE 压缩环节难免有所丢失。推理层拆得再细,生成底座拿到的也是缺损版本。
无 VAE 的 UiT 能忠实渲染细节,但如果 prompt 本身缺少空间逻辑,它也没有推理能力来补全缺失的约束。当你说“帮我画一个街景”却不指定透视角度,最终很可能拿到一个忠实渲染、每一个元素单独看上去都对,但整体空间逻辑奇奇怪怪的街景。
HiDream-1.5 的做法是把两个子系统串成完整链路,CoT Agent 负责推理和结构化,UiT 负责不打折扣地执行。
用一个不太严谨但直观的类比。
▪ 传统方案像 source code → 有损压缩 → 二进制,精度在中间环节丢失
▪ 1.5 像 source code → 语法分析和优化(CoT)→ 不加中间层的直接编译(UiT)
还有一个官方提到但实测没来得及覆盖的能力。1.5 原生支持多宫格故事板生成和 15 种以上的电影级镜头控制,包括特写、全景、鸟瞰、低角度……从单张图生成到连贯叙事,这个跨度比参数数字暗示的要大得多。从架构原理看,多宫格故事板对 IP 保持和空间连贯性的要求极高,而这恰好是 1.5 的两个最强项。如果你是做视频预演、广告分镜或漫画创作的,这个功能值得尽早上手试试。
当然,作为一种尚且年轻的技术路线,CoT 加无 VAE 的策略也有其代价。
一是 CoT 推理的延迟。 Gemma 4 的推理不是免费的,简单 prompt 可能只需要几十毫秒,但复杂提示词需要的更深层次推理,显然会增加延迟。这是一个没法绕过的取舍,要么牺牲 prompt 门槛,要么牺牲响应速度。
另一个问题是无 VAE 的效率瓶颈。VAE 的核心价值是压缩计算量,1024×1024 的图,像素空间的计算量理论上约是 64×64 潜空间的 256 倍。HiDream-1.5 的解法是蒸馏加速,8B 的 DMD+GAN 蒸馏版(DMD 快速采样 + GAN 生成对抗网络)只需 28 步推理。但蒸馏通常导致生成多样性下降,对于这一点,1.5 的具体指标暂未公开。
因此回到最初的问题,文生图的“慢思考”到底有没有用?
有用,但方式可能跟你想象的不同。它不是让模型“更聪明”,而是降低从“我想画什么”到“模型理解我想画什么”之间的语义损耗。与之相对地,无 VAE 的 UiT 架构则在试图减少从“理解”到“呈现”之间的信息损耗。两条路线合在一起,就是先理解,再无损执行。
六维玫瑰图的数据和三组盲测的结果相互印证。长文本渲染(中文 0.978 vs GPT Image 2 的 0.961)和 IP 保持上,HiDream-1.5 有着断层级的领先,主体理解精度和空间关系处理也明显优于同价位竞品。但在综合产品完成度和生态成熟度上,HiDream-1.5仍有不小的成长空间。
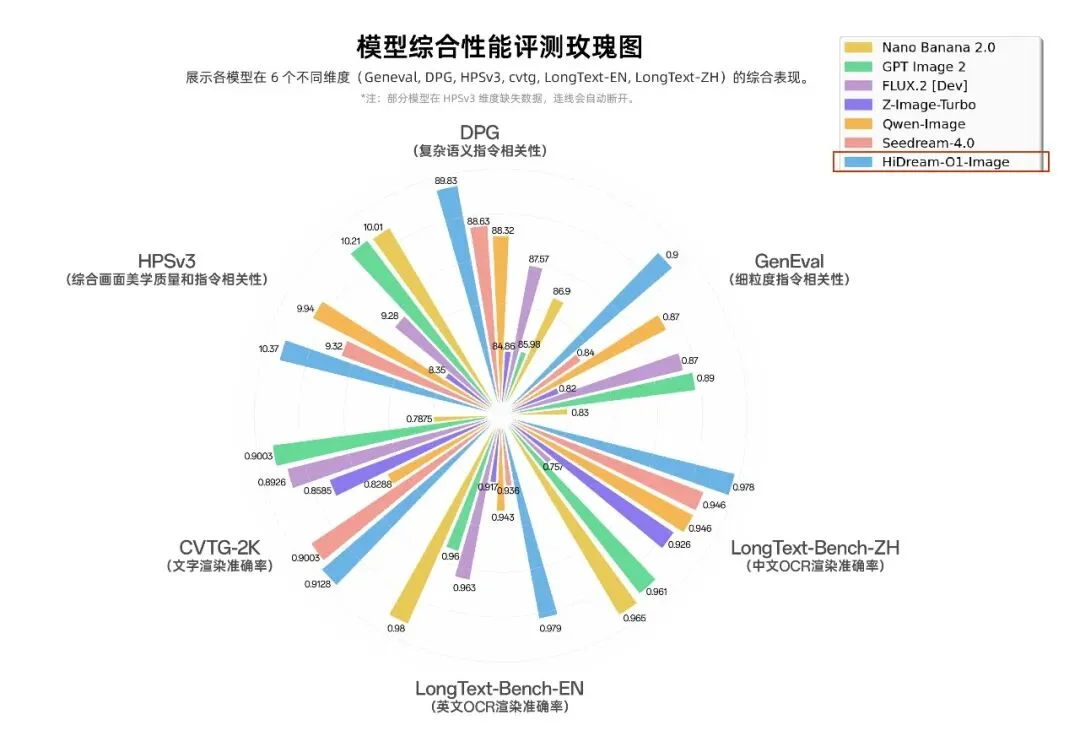
SD 生态在 VAE+DiT 路线上积累深厚,迁移成本极高。FLUX 堆参数填 VAE 的坑,虽然贵但不改变使用习惯。HiDream 改架构省算力,但生态重构是绕不过去的坎。
不过从此前的 8B 版本开始,HiDream 的应对策略就已经很清楚。开源 8B 培育社区信任和开发者生态,闭源 1.5 版本面向商用交付。它意味着你可以在 GitHub 上免费下载 8B 跑原型验证,验证通过了再升级到 1.5 做生产交付。这种直接利好落地的两步走思路,比单项技术参数更值得关注。
开源版的社区数据佐证了这个策略的可行性。仅发布一天,8B 版本就在 Hugging Face 冲上模型趋势榜第四,目前 HF 下载超 1 万、ModelScope 超 2 千。更实际的是,它已经被 WaveSpeedAI 和 fal 两个平台集成上线,用户无需自己部署就能跑。协议给的是 MIT,商业可用,对想拿它做产品的团队来说是实打实的利好。
VAE 架构因其模块协作之间的信息损耗而深受诟病,但人和模型之间,又何尝不是时刻在经历这种割裂。当图像模型从“生成一张好看的图”,走向“生成用户真正想要的图”,技术的切口会在哪里被发现,这是 HiDream-1.5 真正试图回答的问题。CoT 推理和无 VAE 架构,是目前看得见的两个切口。它们不完美,但它们指向的方向,减少语义损耗,减少信息损耗,大概率是未来两年图像模型迭代的源动力。
所以要不要用 HiDream-1.5?
这取决于你需要做什么。如果你常做中文海报、电商图、品牌物料,那么在长文本渲染和多主体保持这两个维度上,当前没有更好的选择。如果你是被 CoT 吸引来的创作者,HiDream-1.5 也的确能降低 prompt 门槛。但你无法指望它读心,用详尽的提示词把需求说清楚,至少在目前仍然必要。如果你是开发者,8B 开源版+MIT 协议的组合在开源图像模型里性价比最高。
有前提的好用,这是今天模型公司能够给出的,最有诚意的承诺。
通过以下链接体验HiDream-O1-Image-1.5 :
https://vivago.ai/
https://hiharness.ai/
开源模型HiDream-O1-Image下载地址:
GitHub:https://github.com/HiDream-ai/HiDream-O1-Image
Huggingface:https://huggingface.co/HiDream-ai/HiDream-O1-Image
文章来自于"AI科技评论",作者 "宇景"。


【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
